



はじめに
Ceph は OpenStack 環境向け分散ストレージのデファクトスタンダードとして広く利用されています。ブロックIF、オブジェクトIF、ファイルIFを備えており、Ceph のみで OpenStack の様々なコンポーネントが使用するストレージバックエンドを構築できることだけでなく、長期間に渡って安定して動作することや、ネット上に流通している情報が豊富なことで、安心して利用できる点が選ばれているものと思われます。
OpenStack 環境のストレージを Ceph に集約できることは大きなメリットですが、その結果 Ceph の障害が OpenStack 環境に及ぼしうる影響範囲は広くなります。Ceph 自体の品質が安定していることも大きなメリットですが、その結果システムの運用体制が、Ceph 障害は発生しないことが前提になっている、という声もあるようです。よって、障害発生時のノウハウは是非とも蓄積・整理しておきたいところです。
本稿では、Ceph を構成する各種ハードウェアで障害が発生してから復旧するまでの間の、OpenStack 環境で走行中のインスタンス (VM) 上でアプリケーションI/O や、システム管理者が OpenStack 環境に対して行ったオペレーション (インスタンスの作成等) への影響を調べます。これには、発生したハードウェア障害が何であったかを事後に調べられるかという観点や、ハードウェア障害復旧後に OpenStack 環境を復旧するための追加的な手順が必要だったかどうかという観点等も含まれます。
一方、ソフトウェア障害に対しては、現象の状況やログ等の情報を参考に既知の問題かどうかをネット上で検索するところから始まり、未知の問題の場合はコアとソースコードから解析することになります。Ceph は RADOS と呼ばれる分散オブジェクトストレージと、それを利用する各種ストレージIF毎のサービスという構成となっており、使用する機能範囲に応じて調査対象のコード規模は大きくなります。
テストコードや内部的に使用している Ceph 以外のコンポーネント (キーバリューストアやウエブサーバー等) を除いたコード全体の規模はLinuxカーネルに含まれるすべてのファイルシステムのコード (linux-4.7/fs) の総量におよそ匹敵します。よって、ソフトウェア障害発生時に調査すべきソースコードの範囲をできるだけ限定できる仕組みが欲しいところです。
本稿では、Ceph の一連のログから、そのときに動作していた可能性のある処理ルートの候補をリストアップする仕組みの試行についても紹介します。
本稿の取り組みは、2015年から2017年に掛けて、弊社の VA Quest サービスをご利用のお客様に対して実施したものです。
本稿で使用している Ceph および OpenStack のバージョンは以下のとおりです。
- 2015年 Ceph Hammer + OpenStack Kilo
- 2016-2017年 Ceph Infernalis + OpenStack Liberty
本稿は、2017年8月末に執筆しました。その時点での Ceph バージョンは Luminous (v12.2.0)です。なお、10月掲載時点での最新バージョンは、9月28日にリリースされた Luminous (v12.2.1) です。
1. OpenStack/Ceph の現状と課題
1.1. Ceph を選択する利点
OpenStack Summit の開催時期 (半年毎) に合わせて OpenStack コミュニティで選択されている各種技術のアンケート (https://www.openstack.org/user-survey) の結果が発表されます。
この中の、OpenStack ブロック・ストレージ・サービス (Cinder) で使用されているストレージバックエンドのシェアに注目すると、Ceph (RBD) は 2014年11月に首位となって以降も毎回シェアを伸ばしており、2017年4月の結果では全体シェアで 65%、大規模システム (1,000コア以上) で 44% と、実質的にデファクトスタンダードとなっているようです。
Ceph が選択される理由はケースバイケースだと思いますが、以下のような理由が含まれるのではないかと考えます。
- ブロックIF、オブジェクトIF、ファイルIF を備えており、Ceph のみで OpenStack の様々なコンポーネントが使用するストレージバックエンドを構築できる
– ブロックIF (Nova/QEMU,Cinder, Glance, …)
– オブジェクトIF (Swift, …)
– ファイルIF (Manila) - 安心して利用できる
– 長期間に渡って安定して動作する
– ネット上に流通している情報が豊富 - その他 (利用する OpenStack ディストリビューションに Ceph が含まれている等)
1.2. Ceph を選択する課題
Ceph を選択する利点は課題をともなうと考えられます。OpenStack 環境のストレージを Ceph に集約できることからくる支出の小ささは大きなメリットですが、その結果、Ceph で発生した障害が OpenStack 環境に及ぼす影響は複合的に広範囲になる可能性があります。Ceph 自体の品質が安定していることからくる運用費の安さも大きなメリットですが、その結果システムの運用体制が Ceph で障害が発生しないことが前提となっており、今後何かあった場合に対するノウハウが蓄積されていないという不安の声もあるようです。
Ceph 障害にはハードウェア障害とソフトウェア障害 (バグ) がありますが、上記はその両方に当てはまると考えられます。ハードウェア障害に対しては、現象から原因を切り分けて故障箇所を特定し、良品と交換することになります。
本稿で紹介する検証で分かったことでもありますが、比較的日常的なハードウェア障害でも対応にはノウハウがあります。例えば、ディスク故障はハードウェアの経年劣化でいずれ発生します。Ceph でディスク故障が発生した場合、他に健全なディスクが十分な数残っていれば、影響が表面化しないことが多いため、ユーザーや管理者は (積極的にシステムを監視していない場合)ディスクが故障したことに気が付かないかも知れません。さらに別のディスク故障が発生し、健全なディスクの数が足りなくなった時点でアプリケーションの I/O がハングするといった現象になります。よって、アプリケーションへの影響を予防するためには最低限の監視が必要になります。障害に全般に着目した場合、以下の課題があると思われます。
- Ceph に集約することによる課題
– 障害時の影響範囲の把握
– 障害時の対処手順の確立 - Ceph 自体の品質が安定していることによる課題
– 何かあった場合に対するノウハウが蓄積されていない
一方、ソフトウェア障害に対しては、現象の状況やログ等の情報を参考に既知の問題かどうかをネット上で検索するところから始まり、未知の問題の場合はコアとソースコードから解析することになります。Ceph は RADOS と呼ばれる分散オブジェクトストレージと、それを利用する各種ストレージIF 毎のサービスという構成となっており、使用する機能範囲に応じて調査対象のコード規模は大きくなります。
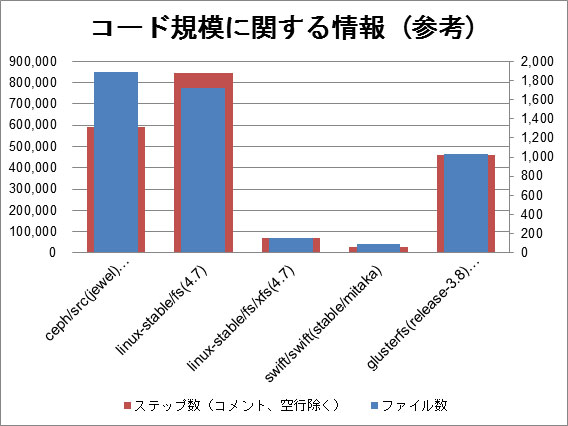
テストコードや内部的に使用している Ceph 以外のコンポーネント (キーバリューストアやウエブサーバー等) を除いたコード全体の規模は Linuxカーネルに含まれるすべてのファイルシステムのコード (linux-4.7/fs) の総量におよそ匹敵します。
コード規模が大きいことに加えて、本稿で紹介する検証で分かったことでもありますが、Ceph のログはソースコード上の当該ログ出力箇所が特定しにくい状況です。よって、Ceph のソースコードやログを日常的に見慣れていない限り、ソフトウェア障害調査は非常に困難が予想されます。ソフトウェア障害に着目した場合、以下の課題があると思われます。
- Ceph のソースコード規模が大きいことによる課題
– ソフトウェア障害に対応できる体制作り
– ログの使い勝手の改善
– ソースコード解析の参考情報の整備
2. Ceph の課題への取り組み
2.1. Ceph に集約することによる課題への取り組み
上述した課題のうち、本稿では「Cephに集約することによる課題」と「Cephのソースコード規模が大きいことによる課題」に取り組みます。 これらの課題以外の「Ceph自体の品質が安定していることによる課題」については障害対応ノウハウの蓄積と共有が 1つの対策と考えます。 上記課題の対策が、障害対応ノウハウとして役立つことを期待します。
2.1. Ceph に集約することによる課題への取り組み
予め、障害が発生した場合に必要な以下の情報を整理しておくことが対策となると考えます。
- 起こりうる障害 (ここでの障害はハードウェア障害を指します)
- 障害の影響
- 障害の切り分け方法
- 障害の対処方法
そのためのアプローチとしてテストを実施します。これは、与えられたシステム構成で想定される障害を「項目」として洗い出し、選択した項目について実際に障害を発生させます。このとき、以下の情報を記録・整理します。
- 影響の観点
- 影響としての現象
- 切り分け方法
- 復旧方法
- 作業所要時間
影響の観点として、本稿では「アプリケーションの I/O への影響」と「システム管理者の操作への影響」の 2つを設定しています。それぞれの観点について実施したテストの具体的な内容や結果については 「3. OpenStack/Ceph 異常系テスト (1)」、「5. OpenStack/Ceph 異常系テスト (2) 」で述べます。
2.2. Ceph のソースコード規模が大きいことによる課題への取り組み
ソフトウェア障害発生時に障害情報として採取した Ceph のログを用いて、調査すべき Ceph ソースコード範囲を限定することを試みます。これは以下の 3つの作業から成ります。
- Ceph ログ行から Ceph ソースコード上のログ出力箇所 (関数) を特定する仕組みの作成
- Ceph ソースコード内の関数呼び出しの関係の洗い出しおよび処理ルートデータベース化
- 一連の Ceph ログのログ出力箇所 (関数) で処理ルートデータベースを検索し、一連のログに対応する処理ルート候補を抽出する仕組みの作成
具体的な内容や結果については「4. Ceph のログ使い勝手の改善」の中で述べます。
- 資料をPDFにまとめましたのでこちらからもお読みいただけます。
- ダウンロードはこちらから
- 各種資料のダウンロードをご希望の方は、必要事項をご入力・ご確認のうえ「同意して確認」ボタンを押してください。