



3. OpenStack/Ceph 異常系テスト (1)
OpenStack 環境のストレージを Ceph に集約することによる課題への取り組みとして、与えられたシステム構成で想定されるハードウェア障害が発生した際の対処に必要な情報を収集・整理します。
障害が及ぼす様々な影響のうち、ここではアプリケーションのI/O への影響に着目します。OpenStack のインスタンス (VM) 上で OS が動作し、その上でユーザーのアプリケーションが動作します。アプリケーションがファイルI/O を行っている状況で Ceph を構成するいずれかのハードウェアで故障を発生させます。この状況から、故障したハードウェアを交換するために必要な一連の手順を行います。故障前、故障中、復旧後を通してアプリケーションのファイルI/O の進捗を監視します。
アプリケーションのファイルI/O への影響がない (ファイルI/O がエラーにならない) ことが最も望ましい結果です。故障パターン毎にアプリケーションのファイルI/O への影響の有無や、アプリケーションのファイルI/O への影響が出る場合にはどの時間的範囲で影響が持続するのかといった情報を予め得ておくことは有用と思われます。
また、故障したハードウェアを交換するために必要な一連の手順実施に要したおよその時間も記録します。この時間は上述の影響が持続する時間的範囲に含まれる場合と含まれない場合があります。前者の場合はハードウェア故障発生時の対処の緊急性が求められる場合があります。
このテストでは特定のハードウェア障害を意図して発生させますが、実際のケースでは障害箇所の特定が必要であることは言うまでもありません。よって、故障したハードウェアを交換するために必要な一連の手順には、故障箇所の特定も含まれます。 結果的に、コマンド出力等では障害箇所の特定ができない場合がありました。また、フィールドサポートの場面としては障害箇所の特定のためのオペレーション (コマンド実行等) をタイムリーに実施することが困難な場合も想定されます。このような場合に対しては取得済みの Ceph のログからの障害箇所の特定を試みます。具体的な内容や結果については「4. Ceph のログ使い勝手の改善」の中で述べます。
【異常系テスト見出し一覧】
3.1. システム構成
OpenStack/Ceph 異常系テスト (1) に使用したシステムの構成を説明します。下記図に示すような構成のシステムを 7 セット使用します。複数のシステムを使用する主な目的は、システム毎に異なるテスト項目を並行して実施することで、テスト全体に掛かる時間を短縮することです。
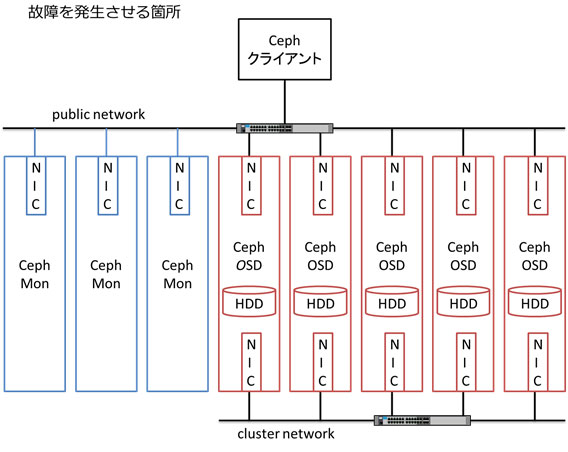
図の「Cephクライアント」は、OpenStack 環境と RBD クライアントを指します。OpenStack 環境は、1台のコントロールノード兼コンピュートノードと 1台のコンピュートノードから構成されます。
OpenStack の以下のコンポーネントがストレージバックエンドに Ceph を使用します。
- OpenStack Compute (nova)
- OpenStack Block Storage Service (cinder)
- OpenStack Image Service (glance)
2つの OpenStack インスタンス (VM) を作成します。1つはイメージから起動し、1つはボリュームから起動します。各インスタンスは別々のコンピュートノードにアサインされます。各インスタンスにファイルI/O 用のボリュームを 1つ作成し、インスタンスに接続します。
RBDクライアントは 1台のノードです。ファイルI/O 用の RBD ボリュームを作成し、RBD クライアントにブロックデバイスとして接続します。いずれの Ceph クライアントも Ceph のブロックI/F (RBD) を使用します。OpenStack 環境と RBD クライアントではボリュームの接続方法が異なります。OpenStack 環境からは librbd ライブラリで接続し、RBD クライアントからは Linuxカーネルの krbd ドライバで接続します。
本稿ではファイルI/FおよびオブジェクトI/Fを使用するアプリケーションへの影響の観点については扱いません。
Cephクラスタは以下の構成です。
- Ceph MON サーバー: 3台
- Ceph OSDサーバー: 2~5台、各Ceph OSD サーバーで Ceph OSD デーモンが1つ動作
- ネットワーク: 2系統
使用するソフトウェアのバージョンは以下のとおりです。
- OS: Ubuntu 14.04.2 LTS
- Ceph: hammer (v0.94.1)
- OpenStack: stable/kilo
OpenStack 環境や RBD クライアント、Ceph クラスタを構成するサーバーは全て VM です。よって OpenStack インスタンス (VM) は VM 上の VM (ネストVM) です。
OpenStack 環境や RBD クライアント、Ceph クラスタを構成する各 VM は以下の構成です。
- CPU:1コア/2ソケット
- メモリ:8GB (OpenStack サーバー、RBD クライアント) または 1GB (Ceph MON サーバー、 Ceph OSD サーバー)
上記の VM は 10台の物理サーバーに分散して収容しています。実際の運用で用いられるのはベアメタルサーバーで、搭載 CPU コア数や搭載メモリ量も上記 VM よりも格段に大きい場合が多いようです。
物理サーバーのネットワーク媒体は 1Gb イーサーネットを使用します。この環境では 1Gb イーサーネットを、上述の 7セットのシステムでシェアしています。つまり、帯域性能的には 1Gb イーサーネットの 1/7 になる可能性があります。実際の運用で用いられるのは 10Gb イーサーネットが多いようです。
物理サーバーのストレージ媒体は 3.5´ SATA HDD を使用します。各 Ceph OSD デーモンあたり 3.5´ SATA HDD 1本の割り当てです。実際の運用で用いられるのは SSD が多く、1台の Ceph OSD サーバーに n 台の SSD を搭載し、これを n 個の Ceph OSD デーモンでサービスする構成のようです。
上記のように、本稿で使用するシステム構成と実際の運用で用いられるシステム構成とでは、使用するサーバースペック (CPUコア数、メモリ量) やネットワーク媒体、ストレージ媒体の構成が異なるため、本稿のテスト結果と実際の運用とでは性能上の傾向が大きく異なる可能性がある点に注意が必要です。
例えば Ceph OSD サーバーがダウンしたときに残りの Ceph OSD サーバーでデータ冗長性を維持するためのリバランスが動作しますが、 上記の違いにより 1台の Ceph OSD サーバーがダウンした時に影響を受ける Ceph OSD デーモンの数が異なりますし、リバランスに使用できるネットワーク帯域が異なるので、リバランスに掛かる時間等が大きく異なってくると思われます。
また、実際の運用では、OpenStack のコンピュートノードが Ceph OSD サーバーを兼ねる構成を採る場合があります。この場合、Ceph クラスタのリバランス処理によって発生した負荷等が OpenStack のコンピュートノード上のインスタンス (VM) に及ぼす影響や、反対に、インスタンス (VM) によって発生した負荷が Ceph クラスタの I/O 性能に及ぼす影響等も予め把握しておきたいところです。
一般に、このような観点での検証 (運用で使用するサーバーのサイジングの検証) では使用する物理サーバーのスペックも重要なパラメータとなります。本稿でのテストにはサイジングの観点は含まれていません。
3.2. テスト項目 (想定されるハードウェア障害)
上述したシステム構成において想定されるハードウェア障害のパターンをリストアップし、テスト項目とします。
リストアップの方法は、はじめに故障するハードウェアのドメインやシステム構成のパラメータを「要因」としてリストアップし、次に、各ハードウェアのドメインやシステム構成のパラメータがとりうる状態や設定について「因子」としてリストアップします。最後に、各要因に設定する因子の組み合わせパターンとしてテスト項目を記述します。
以下に要因とその因子を列挙します。
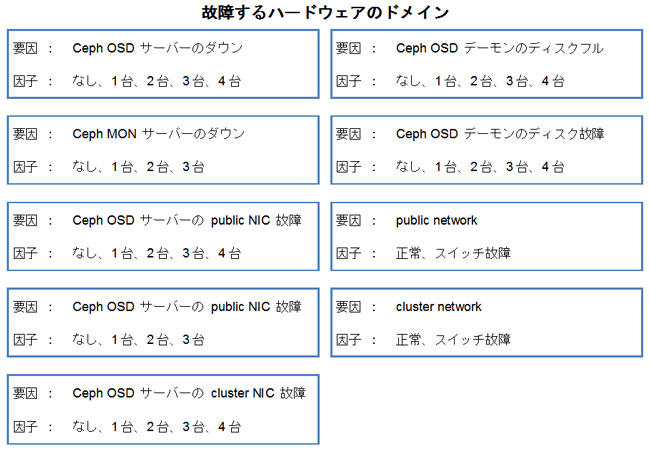
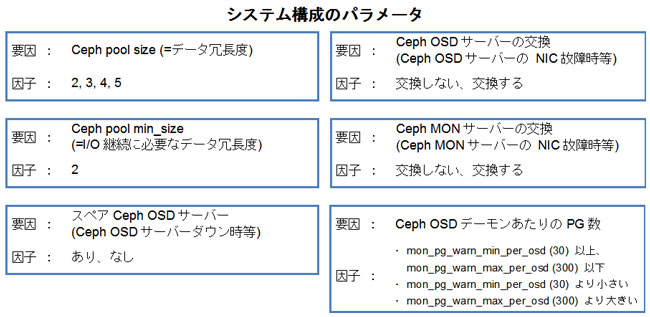
具体的なテスト項目については「3.4. テスト結果」に記述します。
3.3. テスト方法
以下の方法で、OpenStack から Ceph へのワークロードが継続的にある状態をつくります。
各システムに 2つのインスタンス (VM) が置かれています。1つはイメージから起動、1つはボリュームから起動しています。各インスタンスにはファイル I/O 用のボリュームが 1つ追加されています。ファイル I/O 用のボリュームにファイルシステムを構築し、インスタンスからマウントします。各インスタンス上に I/O プロセスを起動します。I/O プロセスは、1秒間のスリープと上記ファイルシステム上に 1個の新規ファイルを作成する処理を繰り返します。
OpenStack から Ceph へのワークロードの他に、RBD クライアントから Ceph へのワークロードも発生させます。上述したように、OpenStack 環境と RBD クライアントではボリュームの接続方法が異なります。OpenStack 環境からは librbd ライブラリで接続し、RBD クライアントからは Linuxカーネルの krbd ドライバで接続します。また、両者でファイル I/O の仕方を変えます。後述するように、RBD クライアントからは DirectIO を使用します。
各システムに 1つの RBD クライアントが置かれています。RBD クライアントにはファイル I/O 用の RBD ボリュームが 1つ接続されています。ファイル I/O 用の RBD ボリュームにファイルシステムを構築し、RBD クライアントからマウント (syncオプション指定) します。RBD クライアント上に I/O プロセスを起動します。I/O プロセスは、1秒間のスリープと上記ボリューム上に 1個の新規ファイルを作成して 4KB のデータを write (direct I/O) する処理を繰り返します。
次に、この状態でテスト項目に記述したハードウェア障害を発生させます。ハードウェア障害の発生方法については説明を省略します。
何らかの理由で新規ファイルが作成できない場合、I/O プロセスは終了します。各テスト項目実施を通して当該プロセスが終了しないことをもって運用が継続できている状態とみなします。Ceph へのワークロードが (I/O がブロックされる等で) 停止と再開を繰り返している状態も運用が継続できている状態の一部とみなします。
3.4. テスト結果
具体的なテスト項目とその結果について説明します。
始めに、各テスト項目を表現した図の見方を説明します。テスト項目は、故障するハードウェアのドメインの状態とシステム構成のパラメータの値のパターンです。
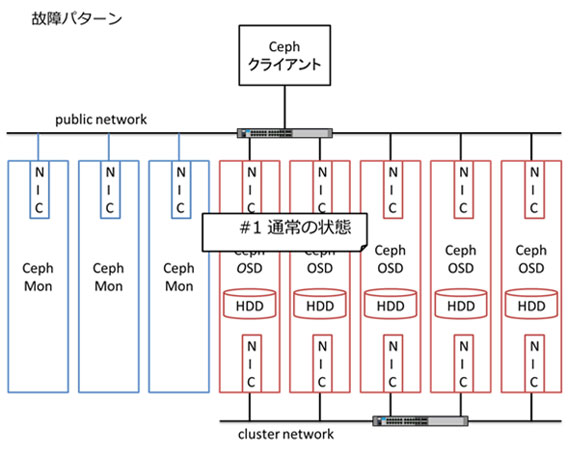
この図はテスト項目 #1 を表しており、全てのテスト項目の基準となります。この図では 3台の Ceph MON サーバーと 5台の Ceph OSD サーバーがあり、全てのサーバーが public network に接続されており、全ての Ceph OSD サーバーが cluster network に接続されている状態を表しています。故障するハードウェアのドメインは灰色で示されます。この図では灰色のドメインは存在せず、すなわち、通常の状態を表します。システム構成のパラメータについては、注目すべきものについて余白に記載します。この図では何も記載されていません。
つぎに下記の図の見方を説明します。
OpenStack/Ceph 異常系テスト (1) では、障害が及ぼす様々な影響のうち、アプリケーションの I/O への影響に着目します。
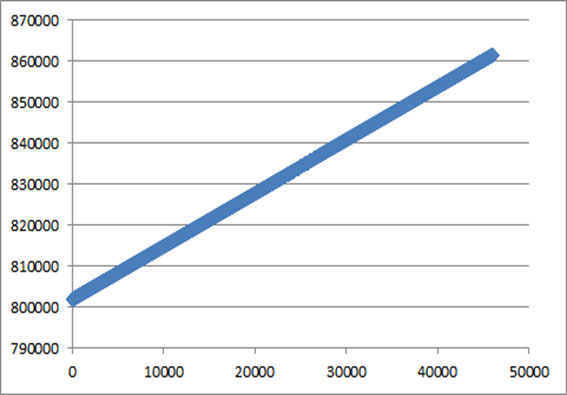
上記の図は、障害 (=テスト項目) 毎に示されるアプリケーション I/O の進捗を表します。縦軸は単位時間を表し、横軸はファイル I/O 用のボリュームに作成されたファイルの数を表します。データは、RBD クライアント上で DirectIO を使用してワークロードを生成している I/O プロセスでの結果を使用しています。
テスト項目 #1 は通常の状態での結果です。時間の経過におよそ比例して作成されるファイル数が増加しています。このグラフは、ファイルを 1つ作成する毎に点をプロットしています (複数の点を結んだ直線でないことに注意してください)。
もし、ファイル I/O でエラーが発生すると I/O プロセスは終了するのでその時点以降、ファイル数はプロットされません。もし、ファイル I/O でハングが発生すると、I/O プロセスもハングするので、ハングしている間はファイル数がプロットされません。ハングが解けた時点で再びファイル数がプロットされますので、点の集まりはハングが持続した長さだけ上下に分断されるはずです。また、ファイル I/O の進捗が滞ると点の集まりの傾きが急になり、逆に進捗が捗ると傾きが緩やかになるはずです。
- 資料をPDFにまとめましたのでこちらからもお読みいただけます。
- ダウンロードはこちらから
- 各種資料のダウンロードをご希望の方は、必要事項をご入力・ご確認のうえ「同意して確認」ボタンを押してください。