



5. OpenStack/Ceph 異常系テスト (2)
OpenStack 環境のストレージを Ceph に集約することによる課題への取り組みとして、与えられたシステム構成で想定されるハードウェア障害が発生した際の対処に必要な情報を収集・整理します。
障害が及ぼす様々な影響のうち、「3. OpenStack/Ceph 異常系テスト (1)」ではアプリケーションの I/O への影響に着目しました。ここから説明する OpenStack/Ceph 異常系テスト (2) ではシステム管理者の操作への影響に着目します。システム管理者が OpenStack 環境に対してオペレーションを行っている状況で Ceph を構成するいずれかのハードウェアで故障を発生させます。この状況から、故障したハードウェアを交換するために必要な一連の手順を行います。
OpenStack/Ceph 異常系テスト (1) では、テスト項目はハードウェア障害パターンに対応するもので、テスト項目数は 53 項目でした。OpenStack/Ceph 異常系テスト (2) では、テスト項目はハードウェア故障パターンとシステム管理者が OpenStack 環境に対して実施するオペレーションの組み合わせに対応します。
オペレーションは 9種類を設定しました。各オペレーションについては後述します。
53個のハードウェア障害パターンのうち、OpenStack 環境に対するオペレーションへの影響がないことが明らかな 2 パターン (#52 と #53) とデータ冗長度 5 の設定の 1パターン (#21) は組み合わせから除外しました。後者については、システム管理者の操作への影響という観点から、データ冗長度は 4 までの設定 (#20) で十分と考えたことが除外した主な理由です。よって、テスト項目数は 50 x 9=450 項目です。
OpenStack/Ceph 異常系テスト (1) では、結果的に、コマンド出力等では障害箇所の特定ができない場合がありました。すなわち、コマンド (ceph -watch) 出力でハードウェア障害のイベント発生が分からないことや、コマンド (ceph -watch) 出力と実際のイベントが一致しないことがあるという点です。
フィールドサポートの場面としては障害箇所の特定のためのオペレーション (コマンド実行等) をタイムリーに実施することが困難な場合も想定されます。このような場合に対しては取得済みの Ceph のログからの障害箇所の特定が必要と思われます。 上記問題のフィードバックとして、OpenStack/Ceph 異常系テスト (2) では、ログだけからハード障害を切り分けできるかどうかという観点を加えています。OpenStack/Ceph 異常系テスト (2) ではテスト項目毎に、故障前、故障中、復旧後の時間的範囲での Ceph のログを取得します。
【異常系テスト見出し一覧】
5.1. システム管理者がOpenStack環境に対して実施するオペレーションの選択
OpenStack/Ceph 異常系テスト (2) では、テスト項目はハードウェア故障パターンとシステム管理者が OpenStack 環境に対して実施するオペレーションの組み合わせに対応します。オペレーションは 9種類を設定しました。
オペレーションの設定は以下のステップで実施しました。
- ステップ 1:システム管理者が使用する OpenStack API をリストアップ
- ステップ 2:うち、延長で Ceph 連携のある OpenStack API をリストアップ
- ステップ 3:リストアップした OpenStack API を使用して循環するオペレーションのシーケンスを作成
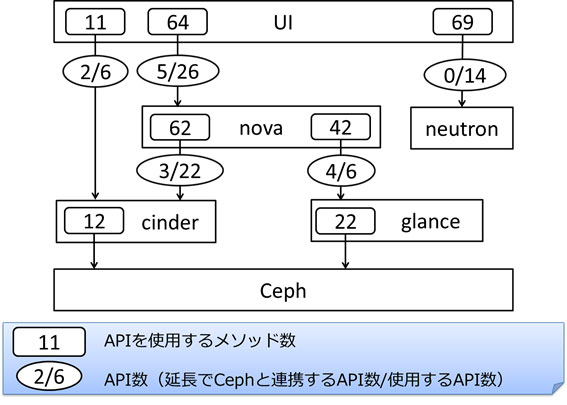
上記の図がステップ 1およびステップ 2のリストアップの結果です。直接使用する OpenStack API が 46個ありました。うち、延長で Ceph 連携のあるものは 7個でした。
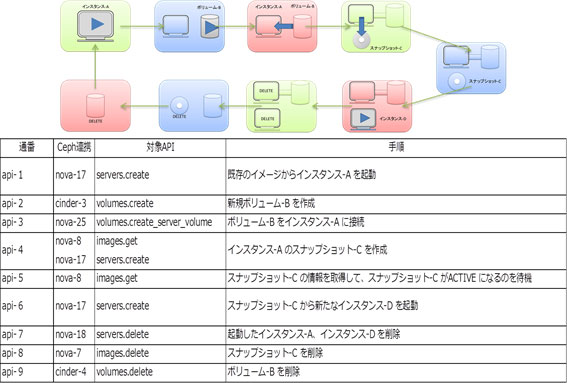
上記の図および表はステップ 3 で作成したシーケンスです。
シーケンスは api-1 から api-9 の 9個のオペレーションで構成されます。api-9 のオペレーションを実行すると、api-1 のオペレーションを実行する前の、最初の状態に戻ります。
- api-1: 既存のイメージからインスタンス-A を起動
- api-2: 新規ボリューム-B を作成
- api-3: ボリューム-B をインスタンス-A に接続
- api-4: インスタンス-A のスナップショット-C を作成
- api-5: スナップショット-C の情報を取得して、スナップショット-C が ACTIVE になるのを待機
- api-6: スナップショット-C から新たなインスタンス-D を起動
- api-7: 起動したインスタンス-A、インスタンス-D を削除
- api-8: スナップショット-C を削除
- api-9: ボリューム-B を削除
5.2. テスト項目実施方法
OpenStack/Ceph 異常系テスト (2) は OpenStack/Ceph 異常系テスト (1) と基本的に同じシステムを使用して実施しますが、テスト実施時期の違いから使用するソフトウェアバージョンに以下の違いがあります。
OpenStack/Ceph 異常系テスト (1) で使用したソフトウェアのバージョン
- OS: Ubuntu 14.04.2 LTS
- Ceph: hammer (v0.94.1)
- OpenStack: stable/kilo
OpenStack/Ceph 異常系テスト (2) 使用するソフトウェアのバージョン
- OS: Ubuntu 14.04.4 LTS
- Ceph: infernalis (v9.2.0)
- OpenStack: stable/liberty
「3. OpenStack/Ceph 異常系テスト (1)」の 3.1. システム構成で述べたように、テストは同じ構成のシステムを複数セット使用して並行実施します。
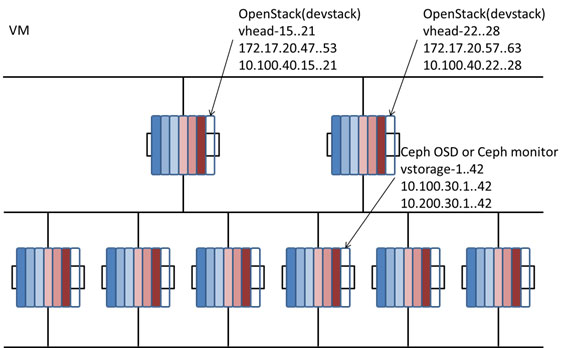
上記の図は、物理的サーバーの構成と、その上に VM で構成した 7つのシステムを表しています。
OpenStack/Ceph 異常系テスト (2) は項目数が 450項目と、OpenStack/Ceph 異常系テスト (1) の 53項目に比べて格段に多いため、実施にあたってはテスト全体に掛かる時間を短縮するための工夫が必要でした。api-1 から api-9 の 9個のオペレーションが循環するのもその工夫の一つです。これは、あるテスト項目の実行が次のテスト項目の準備を兼ねるようにすることで、テスト項目と次のテスト項目の間に必要な手順をなるべく減らすことを意図しています。
5.3. ログの分析
ログの取得には「4. Ceph のログ使い勝手の改善」の「4.2. Ceph ログの問題点への対処」で述べた Ceph クラスタのログを回収・管理する仕組みを使用し、テスト項目実施毎にテスト ID をログアーカイブに紐づけて管理します。また、取得したログアーカイブはログ行にログ出力箇所を付加する仕組みを使用してログ出力箇所のサブシステムおよびログレベルの分布を取得します。
各項目のサブシステムおよびログレベル分布は、故障のない状態 (障害パターン#1) で同じオペレーションを実行したときのサブシステムおよびログレベル分布と比較することで、故障時にのみ出力された、あるいは、出力頻度の増加が顕著なログを抽出します。前者を 0N ログ (ゼロエヌログ) と呼びます。これはログの出力頻度が 0 から N に上がったログという意味です。後者を NM ログ (エヌエムログ) と呼びます。これはログの出力頻度が N から M に上がったという意味です。ここでの N は0を含みます。
上述したように、故障パターン毎に 9個のオペレーションを実施します。故障パターンに固有のサブシステムおよびログレベル分布があると仮定し、9個のオペレーションに共通して抽出されるログを特徴ログとします。ログレベル設定を高く設定すると、ログレベル設定が低い場合に比べて抽出される 0N ログおよび NM ログの量は多くなります。運用上、より低いログレベル設定で (=より少ない量のログから) 特徴ログが検出できることが望ましいので、NM ログはログレベルの値を 0 か 1 に限定することにします。0N ログに関しては、故障時にのみ出力されたログであり、障害パターンに由来している可能性が高いのでログレベルの範囲は限定しませんが、ON ログの量が多くなりすぎる場合はログレベル を0 か1に限定し、NM ログを特徴ログに選択することにします。
OpenStack/Ceph 異常系テスト (2) ではテスト項目毎に、故障前、故障中、復旧後の時間的範囲でのCeph のログを取得します。よって、抽出された特徴ログ (ON ログまたはログレベル1以下の NM ログ) には障害発生に由来するログだけでなく、障害復旧のために行ったオペレーションに由来するログも含まれる可能性があります。ログだけからハード障害を切り分けできるかどうかという観点から、障害復旧に由来するログはできるだけ除外します。 そこで、抽出された特徴ログ (ON ログまたはログレベル 1 以下の NM ログ) は、ログアーカイブにログが記録されている時間的範囲の冒頭の 1分間に含まれていたものとそれ以外を区別します。
5.4. テスト結果
ここからは OpenStack/Ceph 異常系テスト (2) の結果のうち、ハードウェア障害のパターン毎に、以下のデータを 2種類の図で紹介します。
- ハードウェア故障箇所 (システム構成図)
ハードウェア故障箇所はシステム構成図中、灰色にマークされている箇所です。欄外には障害パターンの番号と必要に応じてデータ冗長度や min_size、ハードウェア障害が継続した時間の長さ等の補足情報を記載します。
- 9個のオペレーションへの影響 (システム構成図の中央に記載)
オペレーション番号 (api-1~api-9) 毎の観測された影響を青色、黄色、赤色の丸で表示します。
青色は、ハードウェア障害の影響がなかったことを表します。
黄色は、ハードウェア障害を取り除いた後で、当該オペレーションのリトライ等が必要だったことを表します。
赤色は、ハードウェア障害を取り除いた後で、OpenStack 環境の不整合等を修復するためのオペレーションが必要だったことを表します。
なお、観測された影響 (影響なしを含む) ついては以下の点に注意してください。
• 現象の再現性は確認されていません。
• 現象の原因が、発生させたハードウェア故障であることは確認されていません。
- 特徴ログの種類と行数、時間分布 (プロット図)
9個のオペレーションのうち、原則として api-1 のオペレーションのテスト項目の実行時のログから抽出された特徴ログの時間分布を示すグラフです。
横軸を時間、縦軸をログ出力件数としてサブシステムおよびログレベル毎の特徴ログ件数をプロットします。
ラベルは「サブシステム名_ログレベル」の形式です。
欄外の表示は、「障害パターン番号、オペレーション番号 (特徴ログの種類) 、特徴ログ行数/全体ログ行数」です。
特徴ログの種類は ON ログか NM ログかのいずれかです。
api-1 のオペレーションでメモリ上のログ領域不足によりメモリログの上書きが発生している場合はログ取得開始時点からの冒頭部分のログが失われている可能性があるため、この場合は api-1 以外のオペレーションでログの冒頭部分が取得できているオペレーションを選択して特徴ログを抽出します。
以降、障害パターン毎にシステム構成図とプロット図を示します。また、9個のオペレーションへの影響 (システム構成図の中央に記載) で黄色および赤色の箇所があるものについては、それぞれに対応する、観測された現象とハードウェア障害を取り除いた後で行った対処について列挙します。
6. まとめ
本稿では、Ceph を構成する各種ハードウェアで障害が発生してから復旧するまでの間の、OpenStack インスタンス (VM) 上で実行中のアプリケーション I/O への影響や、システム管理者が OpenStack 環境に対して行ったオペレーション (インスタンスの作成等) への影響を調査した結果を紹介しました。
また、ソフトウェア障害調査の場面で、調査対象となるソースコード範囲を狭めるために、Ceph の一連のログから、そのときに動作していた可能性のある処理ルートの候補をリストアップする仕組みや、フィールドサポートの場面で、事後にログから発生したハードウェア障害が何であったかを特定するために、ハードウェアの障害パターンに固有の特徴ログを抽出する試行について紹介しました。
- 資料をPDFにまとめましたのでこちらからもお読みいただけます。
- ダウンロードはこちらから
- 各種資料のダウンロードをご希望の方は、必要事項をご入力・ご確認のうえ「同意して確認」ボタンを押してください。