



OpenStackは、IaaSを構築するためのクラウド基盤ソフトウェアで、OpenStackプロジェクトによって提供されています。
2012年4月5日にリリースされた「OpenStack 2012.1」(コード名:Essex)は、機能・用途別に大きく以下の5つのコンポーネントから構成されています。



VA Linuxは、OpenStackの開発プロジェクトのコントリビューターとして、OpenStackそのものの開発に携わっており、ネットワーク処理を自動運用化するための機能開発プロジェクトである「Quantum」に提供したコード数は世界第6位となりました。
Quantumは、次期バージョンFolsomで正式にリリースされる予定です。また、技術者カンファレンスでの技術発表など、積極的にコミュニティに参画しています。
VA Linuxは、OpenStackを利用したクラウド基盤の構築や、OpenStackの機能強化に関するサービスを提供しており、Object Storage機能を担っているSwiftに関する調査および検証も行ってきました。
これらの開発貢献や活動によるOpenStackコミュニティとの強い連携と独自の知見から、クラウド環境において分散オブジェクトストレージを提供する『OpenStack Object Storage: Swift』について、基礎知識およびSwift内部の仕組みや各種APIに関する詳細解説から、構築運用、課題についての技術調査レポートを作成しました。
【技術調査レポート内容】

本編では、Swiftの概要およびSwift内部の仕組み、インストール手順、運用のヒントを抜粋して解説します。
Swiftの概要と構造
用語
本編で使用している用語を以下にまとめます。
オブジェクトストレージとネットワークファイルシステム
最近、クラウドサービスのひとつとしてオブジェクトストレージサービスが注目を浴びています。ネットワークの先にあるオブジェクトストレージサービス上に、データを保存することができます。最も有名なオブジェクトストレージサービスAmazonが提供するS3サービス(Amazon Simple Storage Service)は、実際に利用されたことがある方もおられるでしょう。
オブジェクトストレージに似たものとして、ネットワークファイルシステムがあります。Windowsの共有フォルダ機能やNFSなどを利用されてきたことと思います。
ネットワークの先にあるストレージのデータを操作できるという点では共通していますが、それらの使い勝手は全く異なります。
ネットワークファイルシステムを利用すると、ネットワークの先にあるファイルも、ローカルマシンのディスク上にあるファイルと区別すること無く同様に操作できます。
一方、オブジェクトストレージは非常に限られたアクセス手段しか提供しません。オブジェクトストレージは、基本的にオブジェクト(ファイルシステムのファイルに相当)のアップロードとダウンロードという二つの手段しか提供していません。
ファイルシステム上のファイルとは異なり、オブジェクトにデータを追記したり、オブジェクトの任意の場所のデータを変更するといった操作はできません。オブジェクトストレージの使い勝手は、どちらかというとファイルシステムよりも、FTPサーバに近いものになります。
Swiftの狙い
OpenStackプロジェクト内には複数のサブプロジェクトがあり、その中の一つが OpenStack Object Storage (Swift)を提供しています。このSwiftの狙いは、高可用でかつスケーラビリティのあるデータの保存場所を提供することです。
実際のところ、SwiftはRackSpace社のオブジェクトストレージサービスCloudFilesに利用しているプログラムのソースコードがベースになっており、実際のサービス提供を通して得られた知見がコードに反映されています。スケーラビリティと高可用性の両方の目的を実現できる設計となっています。
Swiftの構成
Swiftは、多くのサーバPC上で動作するデーモン群が協調動作することによりサービスを提供します。多数のサーバPCを協調動作させようとすると、システム全体を整合性ある状態に保つための管理コストが大きくなり、一定以上スケールさせることが難しくなりがちです。
しかしSwiftでは、Swift全体の構造を集中管理するノードを置かないことにより、この問題を解決しています。その仕組みについては、後ほど説明します。
Swiftが管理対象とするデータには、【アカウント】【コンテナ】【オブジェクト】の3種類があり、それぞれアカウントサーバ、コンテナサーバ、オブジェクトサーバというデーモンが管理しています。
オブジェクトサーバに注目すると、次のように動いていることが分かります。
- 多数のオブジェクトサーバがそれぞれ異なるハードウェア上で動作している。
- オブジェクトサーバ毎に、責任を持っている管理対象のオブジェクト群が異なる。
- あるオブジェクトの複製は、必ず複数箇所のオブジェクトサーバで管理されている。
標準設定では、複製は3つ。
多数のオブジェクトサーバにオブジェクトデータを分散させることにより、スケーラビリティを確保し、オブジェクトを複製して保存することにより耐障害性も確保しています。アカウントサーバ、コンテナサーバも同様の仕組みです。
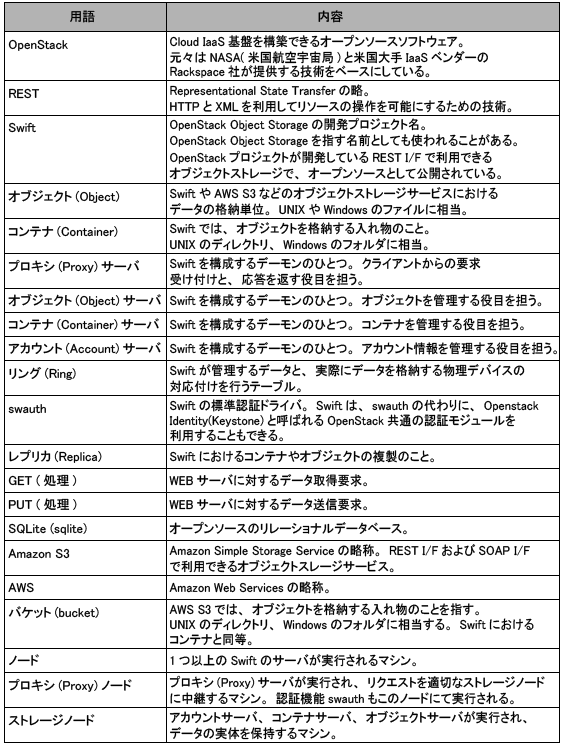
耐障害性を確保するためにデータの複製を複数サーバに置くと説明しましたが、耐障害性を高めるためにゾーンを定義することができます。
例えば、ラックやデータセンタ内の1区画を1のゾーンと定義します。Swiftは、データの複製それぞれが異なるゾーンの中に配置されるようにします。これによりデータセンタ内のあるネットワークスイッチが壊れたり、電源が故障してもオブジェクトストレージ全体としてはサービスを止めずに動かすことができます。
Swiftにはアカウントサーバ、コンテナサーバ、オブジェクトサーバ以外にもう1種類重要なデーモンとして、プロキシサーバがあります。プロキシサーバの役目はSwiftのAPIを提供することです。
APIの呼び出しがあると、それを実際にデータを格納しているアカウントサーバ、コンテナサーバ、オブジェクトサーバに要求を転送し実際のデータ操作を指示します。
ユーザクライアントは必ずプロキシサーバを経由してSwift上のオブジェクトを操作することになります。プロキシサーバは、耐障害のための機能も持っています。
要求の転送先のアカウントサーバ、コンテナサーバ、オブジェクトサーバに問題がある場合、要求転送先を代替のサーバに切り替えます。
アカウントサーバ、コンテナサーバ、オブジェクトサーバと対になって動作するデーモンとして、他には次のようなものがあります。
- レプリケータ
壊れたデータの修復処理や、不要となったデータの削除処理を受け持つ。 - アップデータ
サーバ間の通信が失敗した場合、アップデータがその通信を再実行する。 - オーディタ
データの破損が発生していないか全てのデータを周期的にチェックする。 - リーパ
アカウントを削除した時、そのアカウントに属するデータを削除してまわる。
【リング】
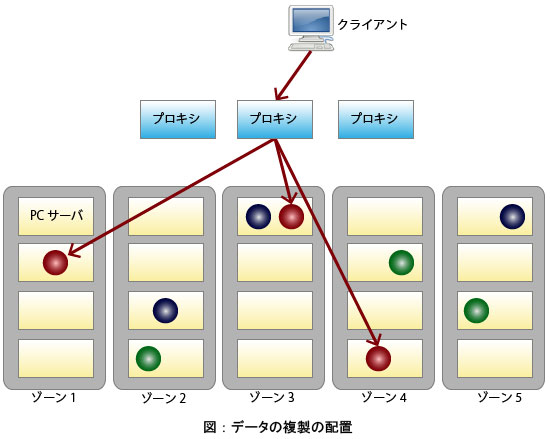
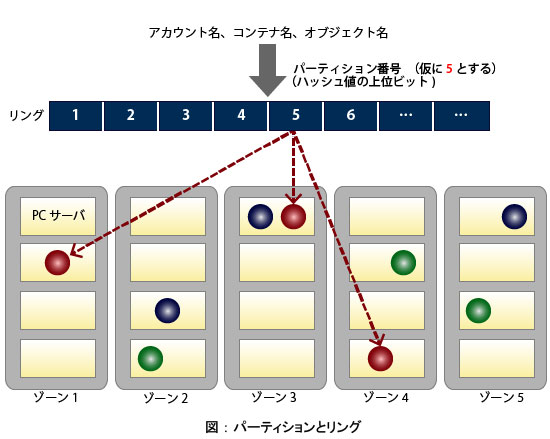
リングは、データとそのデータを格納する物理的な位置(サーバ、ディスク)を対応づけるテーブルです。データの種類には、オブジェクト、コンテナ、アカウントの3種類があるため、リングにもオブジェクト用リング、コンテナ用リング、アカウント用リングの3つが必要になります。
リングの特徴は、「データ物理位置が静的に一意に決定する」ことです。 分散ファイルシステムなどに良く見られる実装は、データ位置を管理するテーブルを用意し、そこにデータの記録場所を追記していくという方式です。それに対し、Swiftは、将来作られるデータも含めて、予め静的に格納場所を決めてしまうというアプローチを採っています。データ名を元に、データ位置を計算するという方式を採用することにより、これを実現しています。
リングはインストール時およびシステムの構成変更時にのみ作成し直し、全てのサーバに同じものをコピーします。
各サーバは、自分のところに置かれているリングだけを見て動作します。
- パーティション
データ(オブジェクト、コンテナ、アカウント)をその名前を元にグルーピングしたものをSwiftの世界ではパーティションと呼びます。
ディスクパーティションとは何ら関係ありません。データを複数のパーティションに分割する場合、パーティション毎に属するデータの数に偏りが出ないように(均等になるように)、データ名のハッシュ値を計算し、そのハッシュ値の上位数ビットをパーティションの番号として利用するという方式を採っています。 - リングのデータ構造
リングは、「パーティション番号毎に、どのサーバのどのディスク上にデータを配置するか」のテーブルを持っています。
パーティション毎に複数のディスクが登録されていますが、それらのディスクは必ず、異なるゾーンに存在することが保証されます。リングの作成ツールが、必ず異なるゾーンにパーティションの複製が置かれるように計算しています。
ネットワーク障害などにより、パーティションの複製を置くべきサーバにアクセスが出来ない場合には、代替サーバ(代替ディスク)もこのリングから求めることができるようになっています。
【オブジェクトサーバ】
オブジェクトサーバは、ローカルファイルシステム上のファイルにオブジェクトを格納します。オブジェクトのメタデータは、ファイルの拡張属性(xattr)内に格納します。
各オブジェクトが格納されるファイルの名前には、オブジェクト名のハッシュ値とタイムスタンプを組み合わせたものを利用します。
1つのオプジェクトに複数回の書き込みがあった場合でも、タイムスタンプ情報を利用することにより、最後に書き込んだオブジェクトを選択することができます。
面白い点は、オブジェクトの削除時にオブジェクトを完全には消し去らないことです。オブジェクトの削除要求があると、削除する代わりに墓石ファイル(tombstone)を置きます。この仕掛けは、障害復旧時、レプリケータが活躍する時に非常に重要な意味を持って来ます。
【コンテナサーバとアカウントサーバ】
コンテナは、オブジェクトの入れ物です。ファイルシステムで言えばディレクトリやフォルダに相当します。各コンテナサーバは、管理担当となったコンテナを管理します。
コンテナ配下にあるオブジェクト一覧を管理するのが仕事です。オブジェクト一覧管理には、SQLite3データベースを用いています。
同様にアカウントは、コンテナの入れ物です。アカウント毎にその配下に作成したコンテナの一覧を、SQLite3データベースを利用して管理しています。