



柔軟なプロビジョニング
多くのクラウドコンピューティング環境が備える主要な機能の1つとして、利用するコンピューティングリソースを拡張および縮小できる機能があります。
リソースの料金は使用量に応じて決まるのが一般的です。
リソースは、必要になった時点でプロビジョニングや有効化を行い、不要になった時には解放や無効化を行うと、コストを節約できます。
クラウドコンピューティング環境では、プロビジョニングや解放は一般に秒や分の単位で行うことができ、料金も多くの場合は時間単位で決まります。
これは、機器や装置を物理的にプロビジョニングする場合とは好対照です。こうして得られる柔軟性は、クラウドコンピューティングの大きな特長の1つです。
また、コンピューティング環境が備える機能にアクセスするためのAPIが用意されていることも、クラウドコンピューティングの大きな特長の1つと言えるでしょう。
キャパシティプランニング
LVSクラスタを導入して負荷分散を行う根本的な目的は、提供するサービスがリクエストを処理するキャパシティを高めることにあります。
つまりその場合には、サービスに対する需要が高まる時間または期間が多少なりとも存在し、単一のサーバのキャパシティを超えることが予想されるということです。
さらには、クラスタに存在する実サーバの数で、一定のレベルの需要に対応するのに十分なキャパシティを備えているということも必要になります。
需要が常に一定で、LVSクラスタのキャパシティで、そのレベルの需要に十分対応でき、しかも余分なキャパシティがあまりない、という状況であれば、アイドル状態のリソースがほとんどなく、しかもすべてのリクエストに対応できるクラスタということになります。これはおそらく、理想的な状況といえるでしょう。
しかし残念ながら、需要は往々にして一定ではありません。
たとえば、顧客宛てのメールマガジンを月1回配信している企業があるとしましょう。
メールマガジンの配信直後には、その企業のWebサイトを大勢の人が訪れます。
仮に、メールマガジンの配信から数時間は、同じ月のそれ以外の期間に比べて、Webサイトの閲覧数が2倍になるとしましょう。 メールマガジンの内容や配信パターンを変えるのは望ましくないと仮定すると、プロビジョニングという面で興味深い問題が生じます。
つまり、月1回の負荷のピークに対応できる十分なキャパシティを持つようにWebサイトをプロビジョニングするにはどうすればよいかということです。
1つの方法としては、実サーバを恒常的に増やした状態でプロビジョニングしておくというやり方も考えられます。しかし、追加分のリソースは、ほとんどの期間はアイドル状態となってしまいます。
したがって、必要な期間だけ(つまり月に数時間だけ)リソースをプロビジョニングするというやり方が理にかなっているように思います。そうすれば、コストと電力消費の両方を節約できる可能性があります。
Rackspace Cloud Serverなどのクラウドコンピューティングは、実サーバのプロビジョニングや解放をオンデマンドで行うのにも適しているはずです。このようなプロビジョニングは、手動で実行することも、何らかの形で自動化することもできます。
クラスタの負荷
UNIXシステムでは、システムの負荷の状態を数値で表して判断します。その計算方法の詳細はここでは説明しませんが、一般にその値が1未満の場合はリソースのリクエストをシステムがブロックしていないことを表し、1を超える場合はブロックしていることを表します。この値を使うことで、システムが過負荷かどうかを判断できます。
同様に、LVSクラスタのキャパシティと需要を比較するときには、負荷という観点で考えると有効です。
- すべてのリクエストに即座に対応でき、アイドル状態のリソースがある
クラスタはキャパシティが余っています。このようなクラスタは過少負荷です。 - 処理待ちのリクエストが待機していて、アイドル状態のリソースがない
クラスタは、キャパシティが不足しています。このようなクラスタは過負荷です。
負荷の数値化にはさまざまな方法があります。いくつかの例を示します。
- それぞれの実サーバについて、アクティブな接続とアクティブでない接続の数を調べる。
例えば、それぞれの実サーバに対するアクティブな接続の数を1000件未満に抑えることが望ましい場合があります。
これは、1台のサーバに対する1000件の接続のコストはサーバが変わっても同じだということを前提としたシンプルなシステムです。この前提は、常に成り立つとは限りません。 特に、接続数が少ない場合で、コストが大きいわずかな数の接続が相手の実サーバの負荷に悪影響を及ぼすときには成り立ちません。
- システムの負荷やCPU使用率など、実サーバの指標値を監視する。
そのようなシステムの例が、feedbackd (プロジェクトWebサイト)です。
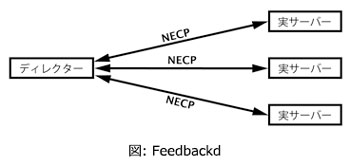
Network Element Control Protocol(NECP)を利用して、実サーバとディレクターの間で負荷情報をやり取りします。
プロビジョニングという観点では、クラスタの過負荷は避けるのが望ましいことです。
しかしその一方で、クラスタが極端に過少負荷になるのを避けることも、同じく望ましいと言えます。それによって、コストや電力消費を抑えられる可能性があります。
動的プロビジョニング
クラスタの負荷を数値化できれば、クラスタが次の3つの状態のどれに該当するかを判断できるはずです。
1. 均衡状態:キャパシティが需要より大きいが、極端な超過ではない。
2. 過少負荷:キャパシティが需要を大きく超過している。
3. 過負荷:需要がキャパシティに非常に近いか、または需要がキャパシティを超過している。
さらに、過負荷のクラスタに対して実サーバを動的にプロビジョニングしたり、過少負荷のクラスタから実サーバを解放したりすることもできるはずです。
この処理は、クラウドコンピューティング環境が備えるAPIを使って、プログラムで実現できます。
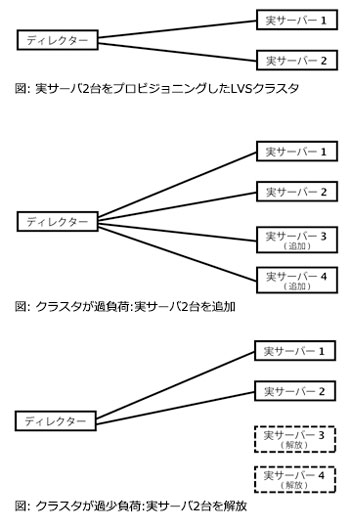
実サーバのプロビジョニングや解放を行うタイミングについて判断するときに併せて考慮すべき点として、以下が挙げられます。
- クラスタから実サーバを削除するときに、その結果クラスタが過負荷にならないようにする。
- 実サーバのプロビジョニングや解放に要する時間についても、需要の変動に照らして考慮する必要がある。
- プロビジョニングの判断を人的対応で左右する何らかの手段を検討する。企業のメールマガジンの例で言うと、メールマガジンの配信前に実サーバのプロビジョニングを増やすよう要求すると効果的な場合がある。
- 実サーバを解放するときには、処理する接続の数を円滑にゼロまで減らすように、実サーバを休止させる方法も考えられる。
- スロースタート機能を実現するようにIPVSを拡張し、新たにプロビジョニングした実サーバに接続が押し寄せるのを防ぐと効果的な場合がある。