



Ceph/RADOS を OpenStack のストレージインフラとして利用する場合の構成例と性能比較例を解説します。
本稿は、@ITで連載している『Ceph/RADOS 入門』 の内容を踏まえた解説となります。@IT での連載記事は、以下を参照ください。
測定結果
測定の結果です。はじめに、各環境での bonnie++ 所要時間の最長です。
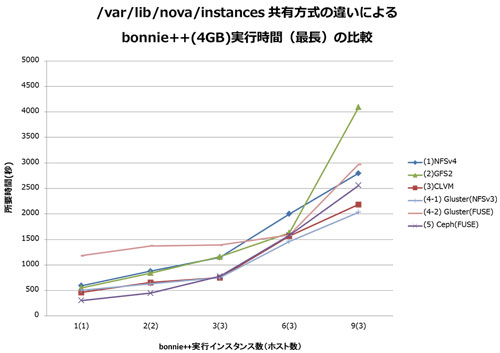
横軸は同時に bonnie++ を開始させたインスタンスの数でカッコ () 内はホスト数です。各インスタンスでの bonnie++ 走行数は 1 です。
縦軸は bonnie++ 終了までの最長時間 (秒) です。
第1回で解説したディレクトリの構成パターンを再掲します。
【ディレクトリの構成パターン】
- 「2. GFS2」と「3. CLVM」が iSCSI ボリュームによる /var/lib/nova/instances ディレクトリ共有です。
- 「2. GFS2」は NFSv4 に比べ劣る結果となりました。
- 「3. CLVM」は NFSv4 に比べ走行時間が短くなりました。
- 「4-1. Gluster (NFSv3)」、「4-2. Gluster (FUSE)」、「5. Ceph (FUSE)」がiSCSI ボリューム以外による /var/lib/nova/instances ディレクトリ共有です。
- うち、「4-1. Gluster (NFSv3)」、「4-2. Gluster (FUSE)」のみデータ冗長度が異なる (3 に対して 2 ) のでグラフのみ示し走行時間の比較からは除外します。
- 「3. CLVM」、「5. Ceph (FUSE)」は NFSv4 に比べで走行時間が短くなりました。
1. NFSv4
各インスタンス上での bonnie++ 終了までの所要時間のバラつきを示したグラフです。これが基準となる NFSv4 での結果となります。
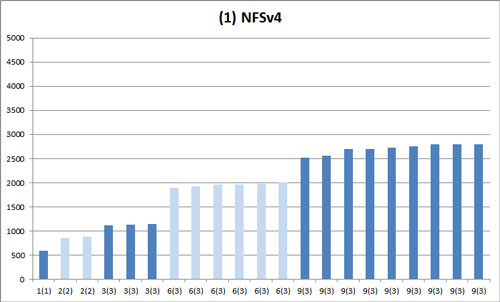
横軸は同時に bonnie++ を開始させたインスタンスの数でカッコ () 内はホスト数です。各インスタンスでの bonnie++ 走行数は 1 です。
縦軸は bonnie++ 終了までの時間 (秒) です。表はインスタンス数毎の標準偏差です。
| 2(2) | 3(3) | 6(3) | 9(3) | |
| 1. NFSv4 | 17.0 | 18.5 | 41.1 | 102.7 |
期待する結果は、同時に開始した bonnie++ は同時に終了する状態です。つまり、棒グラフで隣り合う同じ色の棒が同じ高さで揃い、標準偏差の値が小さい状態です。
【ディレクトリの構成パターン】一覧に戻る
2. GFS2
これは GFS2 での結果です。
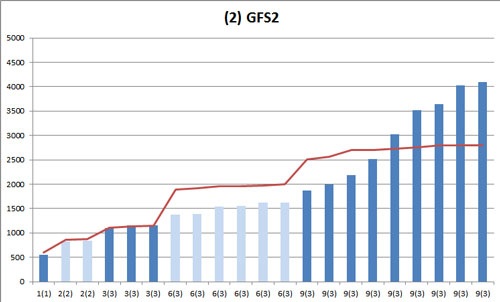
折れ線グラフは基準となる NFSv4 の棒グラフの頂点を結んだものです。9(3) インスタンス実行時のバラつきが非常に大きくなっています。
| 2(2) | 3(3) | 6(3) | 9(3) | |
| 1. NFSv4 | 17.0 | 18.5 | 41.1 | 102.7 |
| 2. GFS2 | 8.5 | 35.6 | 108.8 | 876.8 |
【ディレクトリの構成パターン】一覧に戻る
3. CLVM+NFSv4
これは CLVM での結果です。
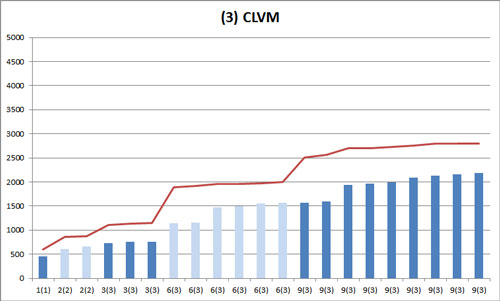
折れ線グラフは基準となる NFSv4 の棒グラフの頂点を結んだものです。6(3) インスタンス実行時と 9(3) インスタンス実行時のバラつきが大きくなっています。
| 2(2) | 3(3) | 6(3) | 9(3) | |
| 1. NFSv4 | 17.0 | 18.5 | 41.1 | 102.7 |
| 3. CLVM | 31.8 | 16.2 | 193.7 | 229.0 |
【ディレクトリの構成パターン】一覧に戻る
4-1. Gluster (NFSv3)
これは Gluster (NFSv3) での結果です。
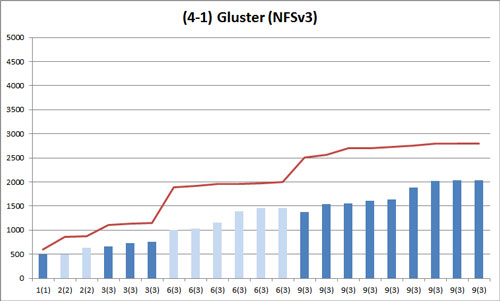
折れ線グラフは基準となる NFSv4 の棒グラフの頂点を結んだものです。データ冗長度が異なるのでグラフの高さではなく高さのバラつきにのみ着目します。
Gluster (NFSv3) は NFSv4 に比べ全体的にバラつきが大きくなっています。
| 2(2) | 3(3) | 6(3) | 9(3) | |
| 1. NFSv4 | 17.0 | 18.5 | 41.1 | 102.7 |
| 4-1. Gluster (NFSv3) | 94.8 | 46.7 | 211.6 | 252.3 |
【ディレクトリの構成パターン】一覧に戻る
4-2. Gluster (FUSE)
これは Gluster (FUSE) での結果です。
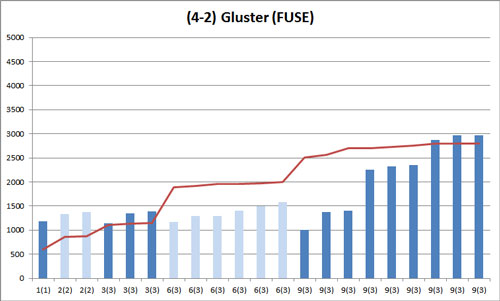
折れ線グラフは基準となる NFSv4 の棒グラフの頂点を結んだものです。データ冗長度が異なるのでグラフの高さではなく高さのバラつきにのみ着目します。
Gluster (FUSE) は NFSv4 に比べ全体的にバラつきが非常に大きくなっています。
| 2(2) | 3(3) | 6(3) | 9(3) | |
| 1. NFSv4 | 17.0 | 18.5 | 41.1 | 102.7 |
| 4-2. Gluster (FUSE) | 24.7 | 135.0 | 151.0 | 744.5 |
【ディレクトリの構成パターン】一覧に戻る
5. Ceph (FUSE)
これは Ceph (FUSE) での結果です。
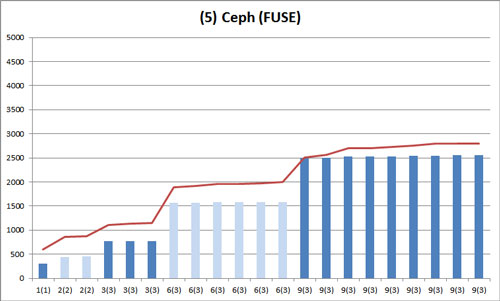
折れ線グラフは基準となる NFSv4 の棒グラフの頂点を結んだものです。Ceph (FUSE) は NFSv4 に比べ、全体的にバラつきが非常に小さくなっています。表は標準偏差です。
| 2(2) | 3(3) | 6(3) | 9(3) | |
| 1. NFSv4 | 17.0 | 18.5 | 41.1 | 102.7 |
| 5. Ceph (FUSE) | 9.2 | 1.5 | 7.1 | 18.8 |
【ディレクトリの構成パターン】一覧に戻る
測定結果のまとめ
測定結果以外も含め、各方式の長所と短所を表にまとめました。
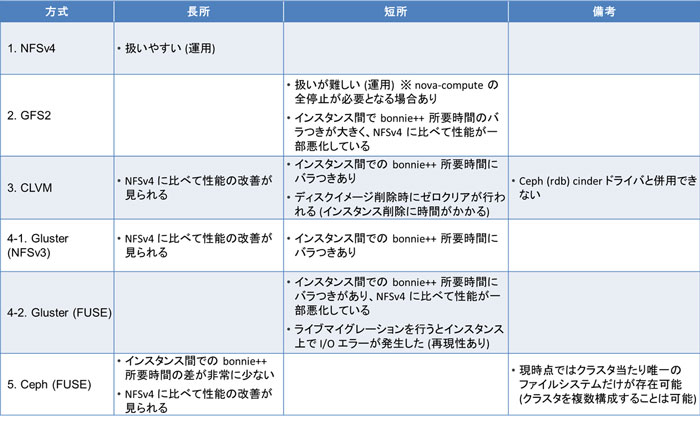
比較の目的は、第一に iSCSI ボリュームによる /var/lib/nova/instances ディレクトリ共有の現実性の見極めにありました。
「2. GFS2」と「3. CLVM」が iSCSI ボリュームによる /var/lib/nova/instances ディレクトリ共有です。
このうち、「3. CLVM」は、bonnie++ 終了までの所要時間が NFS の場合よりも短縮されましたが、「3. CLVM」は前述のとおり NFSv4 との併用です。
「2. GFS2」と「3. CLVM」の両方に共通して、運用に使用するためには iSCSI ボリュームの安定性の十分な検証が必要という印象です。
具体的には、「2. GFS2」については I/O エラーが発生するとファイルシステムが withdraw と呼ばれる状態に遷移し、GFS クライアントがハングすることがありました。この場合、ファイルシステムを修復するために /var/lib/nova/instances のマウントを全て解除する必要があるので、OpenStack の運用が継続できなくなります。
「3. CLVM」については複数のインスタンス (VM) を削除すると複数の論理ボリュームのゼロクリアが並行して行われるため、I/O 負荷が非常に高くなることがありました。論理ボリュームのゼロクリアには論理ボリュームの容量に応じて時間が掛かるため、運用への影響を考慮する必要があります。
比較の目的の第二は、iSCSI ボリューム以外で、NFS よりもスケーラビリティに優れた /var/lib/nova/instances ディレクトリ共有方法の検討でした。
「4-1. Gluster(NFSv3)」、「4-2. Gluster(FUSE)」、「5. Ceph(FUSE)」が iSCSI ボリューム以外による /var/lib/nova/instances ディレクトリ共有です。
うち、「4-1. Gluster(NFSv3)」、「4-2. Gluster(FUSE)」のみデータ冗長度が異なる (3 に対して 2 ) ので、bonnie++ 終了までの所要時間の比較からは除外しました。
「5. Ceph(FUSE)」は、bonnie++ 終了までの所要時間が NFS の場合よりも短縮されました。「5. Ceph(FUSE)」に関しては複数インスタンスで bonnie++ を同時に実行したときの所要時間のバラつきが非常に小さく、動作が安定している印象です。
これは /var/lib/nova/instances ディレクトリ上の VM イメージファイルが、4MB のオブジェクトに分割されて全 4 台の OSD サーバ上の全 8 個のボリューム (OSD) 上にバランスして配置されることにより、I/O 負荷がうまく分散しているものと思われます。
「4-1. Gluster(NFSv3)」や「4-2. Gluster(FUSE)」では Gluster ボリュームは 4 台の Gluster サーバ上の全 12 個のボリュームで構成されており、構成ボリューム数においては「5. Ceph(FUSE)」よりも多い状況ですが、複数インスタンスで bonnie++ を同時に実行したときの所要時間のバラつきは、「5. Ceph(FUSE)」に比べて大きい結果となりました。
これは Gluster の場合、/var/lib/nova/instances ディレクトリ上の VM イメージファイル (最大 9 個) は 1 個のファイルのまま Gluster サーバ上のファイルシステムに配置されるので、4MB の多数のオブジェクトに分割して配置する「5. Ceph(FUSE)」の方が I/O 負荷がバランスよく分散されたものと思われれます。
また、「4-1. Gluster(NFSv3)」や「4-2. Gluster(FUSE)」では、マウント時に 4 台ある Gluser サーバの 1 台を指定します。よって、I/O 対象の VM イメージファイルが当該 Gluster サーバにある場合と、他の Gluster サーバにある場合があります。
後者の場合、「4-1. Gluster(NFSv3)」の場合はマウント時に指定した Gluster サーバを介して read/write が行われます。これに対し、「5. Ceph(FUSE)」ではオブジェクトのある OSD サーバと直接 read/write を行います。この点も「5. Ceph(FUSE)」の方が I/O 負荷がバランスよく分散される要因と思われます。
なお、今回の測定では、「4-1. Gluster(NFSv3)」に比べて「4-2. Gluster(FUSE)」の方が複数インスタンスで bonnie++ を同時に実行したときの所要時間が全体的に長くバラつきも大きい傾向が見られました。
本来、「4-2. Gluster(FUSE)」の場合、各クライアントはマウント時に指定した Gluster サーバではなくボリューム構成ファイル (volfile) の情報に基づいてファイルを持っている Gluster サーバに直接アクセスし、「4-1. Gluster(NFSv3)」の場合よりも Gluster サーバによる中継が発生しない分アクセス効率が良いので、複数インスタンスで bonnie++ を同時に実行したときの所要時間は全体的に短時間かつバラつきも小さくなることが期待されるべきと思われます。
さいごに
Nova の共有ストレージ方式に関する比較例は以上となります。
Hammer リリースからプロダクションで使えるようになった CephFS は、今回の仮想マシンを使った小規模な実験でも良好なスケーラビリティの兆しが見えましたが、もっと大きな、NFSv4 では収容が難しいスケールや RDMA 通信媒体を使用した HPC 用途で CephFS はどうなのか?という点は機会があれば是非検証してみたいと思います。
今後は Ceph 単体の新しい機能として EC プールや Newstore に関連した検証、OpenStack との連携として、Manila 用途や Swift のバックエンド用途などの検証を進める予定です。また、その検証とその結果、技術的考察を一部公開していきたいと考えています。