



This document is for Xen 3.0.0.(Some part of the document is for the later version.)
1 introduction
This document describes about xen/ia64 internals, especially on memory management and grant table. It is assumed that the readers have basic knowledge of IA64 address translation.
For example, translation registers, region registers and etc.
1.1 Related Documents
- Intel Itanium Architecture Software Developer’s Manual
- Itanium Software Conventions and Runtime Architecture Guide
2 the IA64 architecture
This section describes IA64 key features which are important to understand Xen/IA64.
However virtual addressing is too basic so that it isn’t being discussed here. For details, see the Intel IA64 architecture manual.
2.1 memory ordering
Memory ordering defines the global visibility of memory modification. It is important to distinguish an atomic operation from a memory barrier. For details, see the Intel Itanium Architecture Software Developer’s Manual volume2: System Architecture Part II chapter 2.2 Memory Ordering in the Intel Itanium Architecture.
The p2m table of Xen/IA64 is very basic structure and the Xen/IA64 updates it locklessly. It is required to understand its implementation because the Xen/IA64 exploits the IA64 memory ordering semantics.
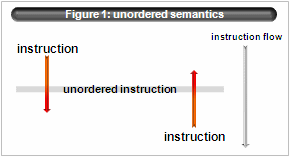
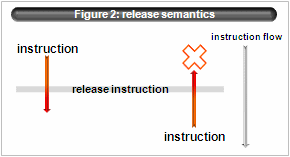
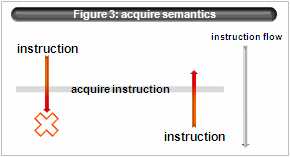
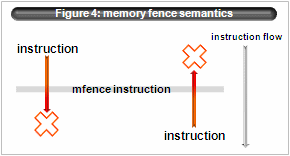
- unordered semantics
- release semantics
- acquire semantics
- memory fence semantics
2.1.1 dependent load
The IA64 doesn’t reorder memory access over dependent load unlike Alpha so that smp_read_barrier_depends() is defined as nop. But the Xen/IA64 doesn’t exploit it (yet). Possibly there is a room for p2m conversion performance exploiting dependent read.
2.1.2 compiler barrier and volatile
According to C standard, “volatile” type qualifier requires compiler not-optimize. Moreover IA64 ABI defines that storing of volatile type must have release semantics(“.rel”) and loading must have acquire semantics(“.acq”).
2.1.3 atomic operation and memory barrier
Note that atomic operation doesn’t mean memory barrier or ordered semantics. Especially simple atomic load/store has unordered semantics.
2.2 implemented address bits, region registers and psr.vm
- unimplemented physical address bits
31 <= IMPL_PA_MSB <= 50
32 – 51 bit
NOTE: Xen/IA64 assumes that no real memory is assigned at the physical address
>= 240. - unimplemented virtual address bits
50 <= IMPL_VA_MSB <= 60
51 – 61 bit
When psr.vm = 1, it is decreased by 1.
PAL_VM_SUMMARY vm_info2.impl_va_msb
NOTE: IMPL_VA_MSB = 60 on Itanium2 and Xen/IA64 assumes IMPL_VA_MSB = 60 - rid size
The number of bits implemented in the RR.rid field
18 – 24 bit depending on the processor implementation.
IA64_MIN_IMPL_RID_MSB = 17
PAL_VM_SUMMARY vm_info2.rid_size
3 execution model
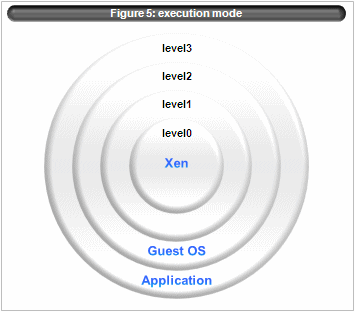 The Xen runs in ring 0, guest OS runs in ring 2, and user land runs in ring 3. ring 1 isn’t used.(figure 5)
The Xen runs in ring 0, guest OS runs in ring 2, and user land runs in ring 3. ring 1 isn’t used.(figure 5)
When a guest OS issues a privileged instruction, protection fault occurs. Xen/IA64 traps it, interprets it, emulates it and returns the execution to guest OS. The emulation code is implemented mainly in xen/arch/ia64/xen/vcpu.c.
To eliminate trap-and-emulate cost, most of the privileged instructions are para-virtualized. The corresponding hypercalls are defined and are called as hyperprivop.
3.1 VT-i
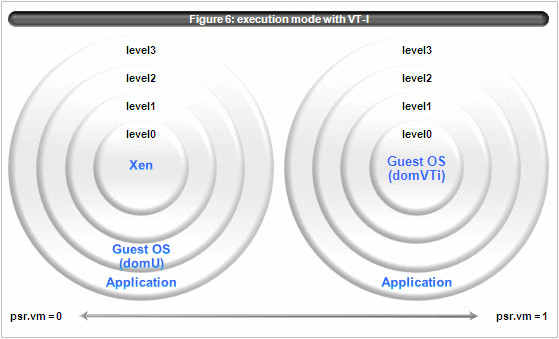
When VT-i is used, guest OS of domVTi is executed with psr.vm=1 and psr.cpl=0. (figure 6).
3.2 virtualizable/in-virtualizable instructions
Some instructions are dependent on privileged level, but it doesn’t trap so that trap-and-emulate strategy doesn’t work. Para-virtualization is required for those instructions.
The followings are such instructions.
- thash
translate virtual address to a corresponding vhpt entry address in virtual address.
This instruction can be executed in non-ring 0. - ttag translate virtual address into tag value.
This instruction can be executed in non-ring 0. - move from cpuid
This instruction can be executed in non-ring 0. - cover
There is side effects when psr.ic = 0 in cpl = 0.
Otherwise this instruction can be executed in non-ring 0. - move from ar.itc
When psr.si = 1. - move to ar.itc
3.3 hyper privop and memory mapped registers(hyper registers)
virtualizable instruction can be emulated with trap-and-emulate and Xen/IA64 is able to do. But it would be slow, Xen/IA64 defines the interfaces which is called hyper privop and hyper registers(memory mapped registers) to speed privileged instruction emulation.
3.3.1 vDSO and hyperprivop
Guest domain issues break instruction with psr.ic = 0 to use hyper privop. Usually OS doesn’t issues break with psr.ic = 0 or it would result in an unwanted effect. psr.ic = 0 imposes that the instructions which issue hyper privop must be covered by itr because tlb miss fault with psr.ic = 0 can’t be recovered.
Usually the Linux kernel text area is covered by itr, however the vDSO area isn’t covered. So the trick that jumping to kernel text area and issuing hyper privop and jumping back is necessary. It makes vDSO code very ugly.
There is a patch to remove psr.ic = 0 by Intel and make hyperprivop a simple break instruction with the pre-defined break-immediate.
4 memory management
This section describes about Xen/IA64 MMU virtualization.
4.1 overview
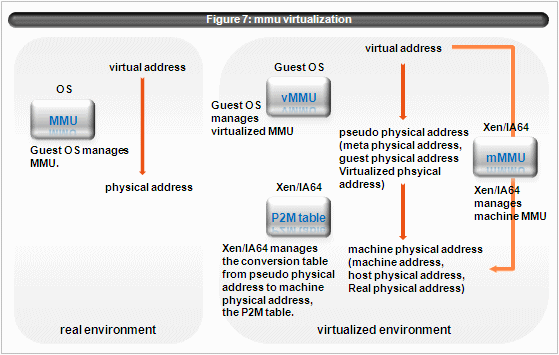
Xen/IA64 fully virtualizes MMU. (At least it tries to.) See figure 7.
4.2 MMU operations
The basic operations related to MMU are listed as follows. Those are the MMU-related instructions which must be virtualized.
| category | instructions |
|---|---|
| tr insert | itr.i, itr.d |
| tr purge | ptr.d, ptr.d |
| tlb insert | itc.i, itc.d |
| tlb entry purge | ptc.e |
| global tlb purge | ptc.g, ptc.ga |
| local tlb purge | ptc.l |
| VHPT | |
| virtual to physical translation | tpa |
| hash | thash, ttag |
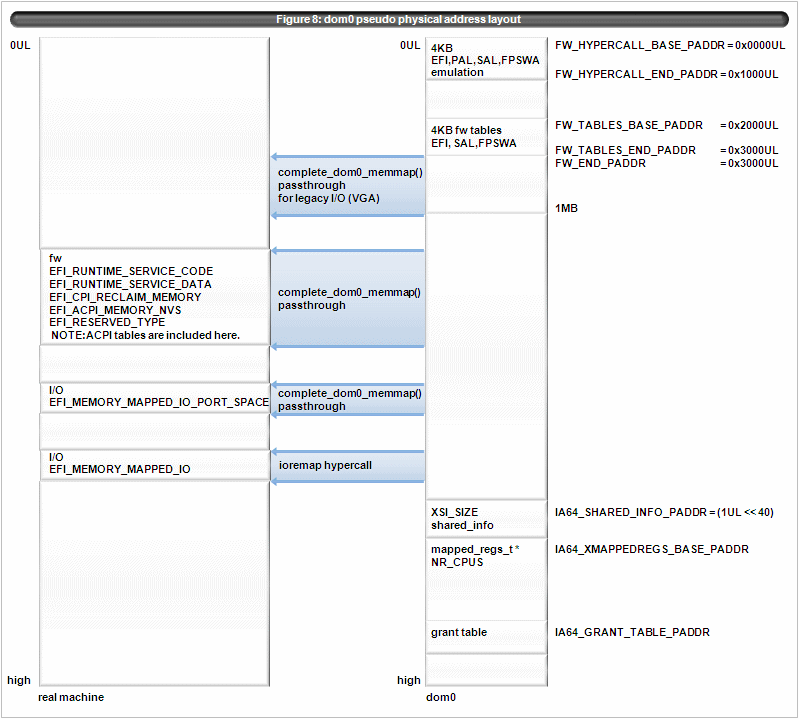
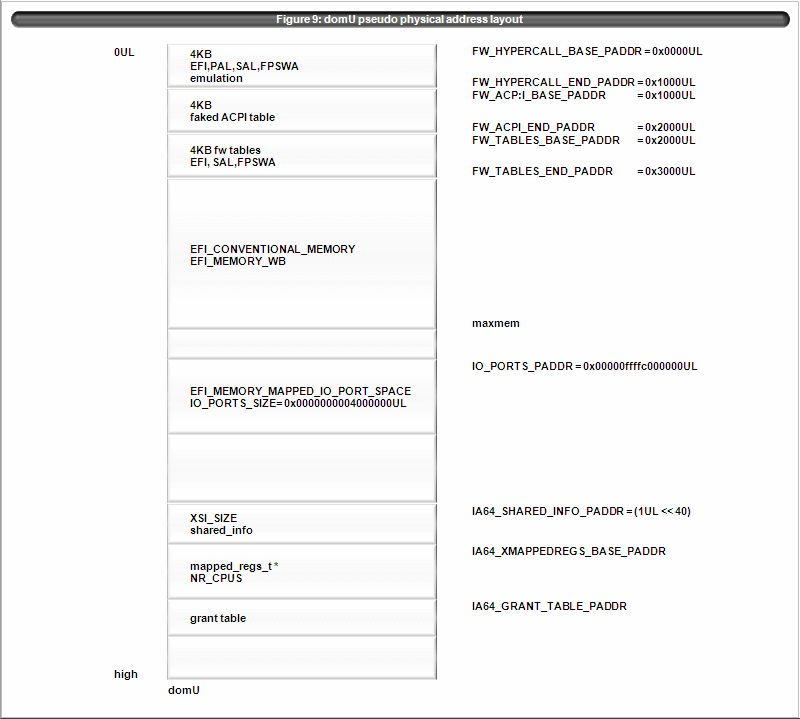
4.3 Domain meta physical address layout
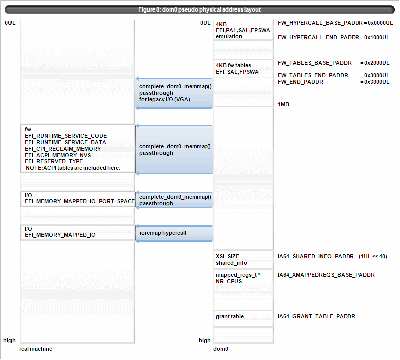
dom0 pseudo physical address layout is as figure 8. conventional memory is assigned according to real machine memory. (EFI_CONVENTIONAL_MEMORY, EFI_LOADER_CODE, EFI_LOADER_DATA, EFI_BOOT_SERVICES_CODE, EFI_BOOT_SERVICES_DATA with EFI_MEMORY_WB attribute) This is for avoiding assign conventional memory on the I/O area to cover the device which becomes unaccessible from dom0. (NOTE: Similar consideration must be paid for domU driver domain.)
domU pseudo physical address layout is as figure 9. conventional memory is filled in (FW_END_PADDR, maxmem).
Figure 8:dom0 pseudo physical address layout
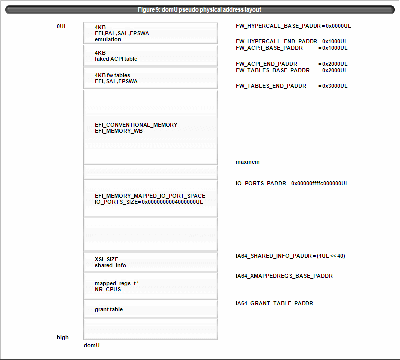
{kind=link}
{kind=link}
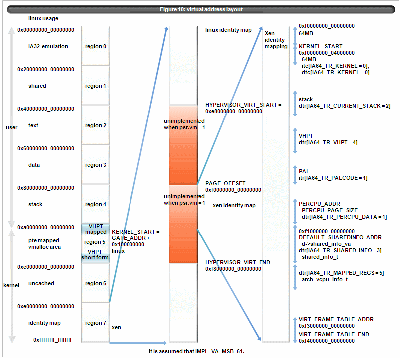
4.4 virtual address layout and TR/VHPT usage
Xen/IA64 uses the area from 0xf00000000_00000000 in the region 7. The followings are the section when Xen/IA64 runs. (The number in () is the TR used to map)
- xen/ia64 text and data section(itr[0], dtr[0])
- PAL code(itr[1])
- stack when executing(dtr[2]) unless dtr[0] covers
- percpu data(dtr[1])
- shared info(dtr[3])
- vhpt(dtr[4]) unless dtr[0] or dtr[2] cover
- arch_vcpu_info_t(dtr[5])
Figure 10 shows those usage.
Figure 10:virtual address layout
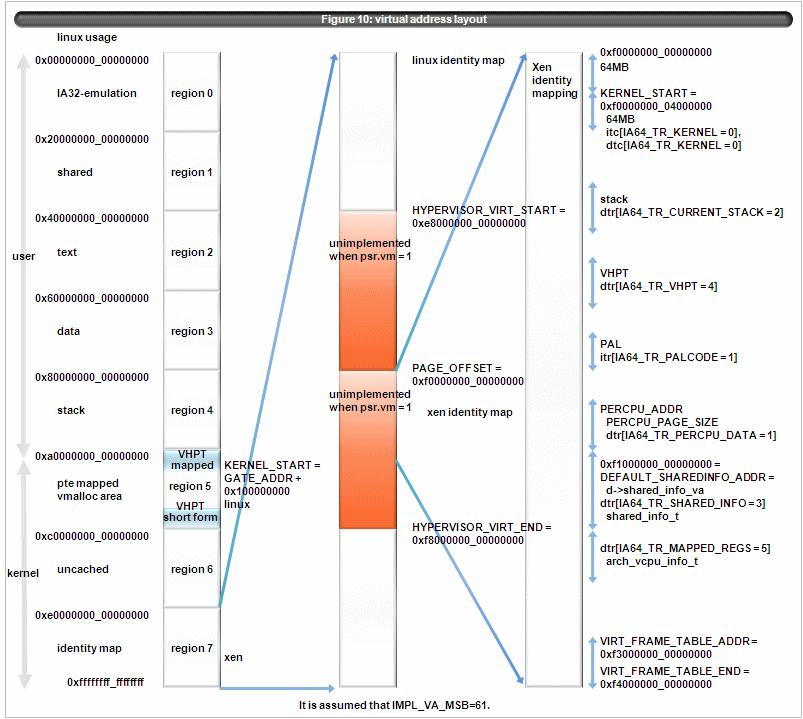{kind=link}
4.5 related data structures
This section summarizes the data structures related to Xen/IA64 memory management.
【Data structure that relates to Xen/IA64 memory management】
| structure | variable | operations |
|---|---|---|
| struct page_info | frame_table | get_page(), put_page() |
| the m2p table | machine_to_phys_mapping (mpt_table) | set_gpfn_from_mfn(), get_gpfn_from_mfn() |
| the p2m table | struct mm_struct d->arch.mm | lookup_alloc_domain_pte() and its variants assign_new_domain_page(), assign_domain_page() and its variants assign_domain_page_replace() assign_domain_page_cmpxchg_rel() and destroy_grant_host_2mapping(), steal_page(), zap_page_one() lookup_alloc_domain_pte() and its variants |
| vTLB for domU | vcpu->arch.{d,i}tlb DEFINE_PER_CPU(unsigned long,vhpt_paddr) vcpu->arch.vhpt_maddr |
|
| vTLB for domVTi | vcpu->arch.vtlb vcpu->arch.vhpt |
|
| tlb insert tracking | vcpu->arch.tlb_track | |
| tlb flush clock | vcpu->arch.last_vcpu.tlbflush_timestamp |
- struct page info
The structure which tracks page status. This is global structure. - the m2p table
The structure which track gpfn corresponding to mfn. with the owner of struct page_info, we can determine pseudo physical address. This is global structure. - the p2m table
The structure which converts from pseudo physical address of a given domain to machine address. This is per domain structure and may be asynchronously accessed from another domain’s context. - vTLB
The structure which virtualize TLB of a given vCPU. This structure is per vCPU.
This might be asynchronously accessed by the same/another domain vCPU when virtualizing ptc.ga, ptc.g and grant table related operations. - tlb tracking hash table
The structure which track tlb insert of any vCPU of a domain. This is per domain structure. This might be asynchronously accessed by same/another domain’s vcpu.
4.6 vTLB overview
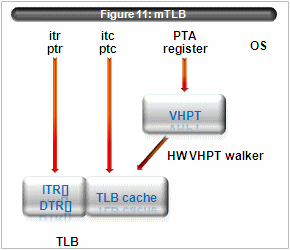
At first we review IA64 tlb structures. see figure 11.
4.6.1 virtualizing TLB
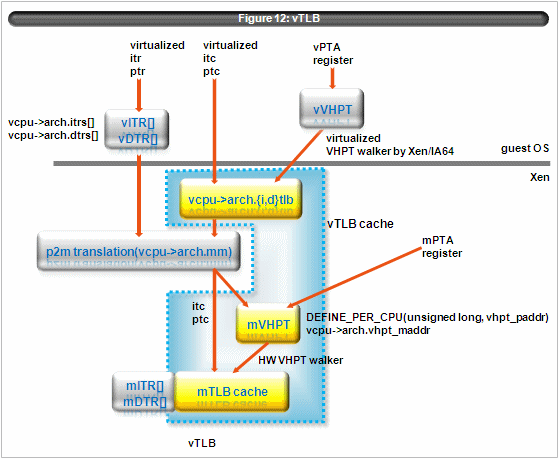
Xen/IA64 fully virtualizes TLB using following structures. (Figure 12)
The way Xen/IA64 virtualizing TLB is that it hooks tlb insert with pseudo physical address of guest domain and the Xen/IA64 issues real tlb insert with machine address translated by the p2m table in behalf of guest domain.
In case of tlb purge, virtual addresses don’t need address translation. So just pass Xen/IA64 simply issues tlb purge instruction in behalf of guest domain in principle. However some optimization needs to cache tlb insert (i.e. vcpu->arch.i, dtlb, VHPT), so those related structure must be purged before issuing purge instruction. They complicates virtualizing tlb purge instruction.
Another complication is grant table implementation. Xen/IA64 grant table modifies the p2m table. To prevent a domain from accidental/malicious accessing freed pages, it is necessary to purge mTLB.
While the basic idea is very easy, its implementation is very subtle because it chose the lock-less p2m table for scalability. So Xen/IA64 must keep the consistency of the related structures and Xen/IA64 developer must be aware of those and be aware of memory-ordering.
It’s the cost of the lock-less p2m table.
- vTR
struct arch_vcpu
TR_ENTRY itrs[NITRS]
TR_ENTRY dtrs[NITRS]
This structure is virtualized TR. - swTC
struct arch_vcpu
TR_ENTRY itlb
TR_ENTRY dtlb
This structure is a part of vTLB. - vVHPT
VHPT is also virtualized. Currently Xen/IA64 supports short format. - mTR(machine translation registers)
- mTC(machine translation cache)
- mVHPT(machine VHPT)
vhpt(per pcpu or per vcpu)
4.6.2 virtualizing VHPT
Xen/IA64 uses VHPT in long format mode. Xen/IA64 virtualize only VHPT in short format and doesn’t virtualize long format VHPT because Linux/IA64 uses short format VHPT. (There is a long format VHPT patch though) Xen/IA64 tlb miss handler reads virtualized VHPT and inserts tlb entry.
4.7 virtual address space switch and per vcpu vhpt
Xen/IA64 switches virtual address space by changing region registers. When changes rr[7], the special handling is required because Xen/IA64 lives in region 7. (ia64_new_rr7())
- store all required values in registers.
- turn off address translation. (psr.it = psr.dt = psr.rt = 0) by ia64_switch_mode_phys()
- store new value to rr[7]
- store new value to translation registers. (itr[], dtr[])
- re-enable address translation by ia64_switch_mode_virt()
4.7.1 address translation and the p2m table
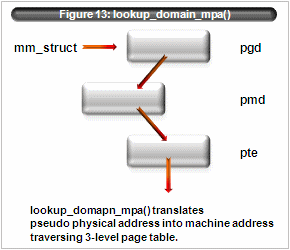
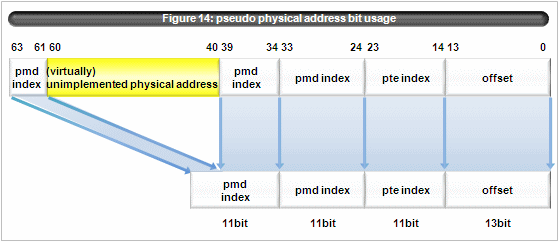
Figure 13: lookup_domain_mpa()Xen/IA64 tracks the translation from the pseudo physical address to machine address by using (a subset of) mm_struct structure same as Linux.
lookup_domain_mpa() function translates using the p2m table via 3-level table lookup.
pgd -> pmd -> pte (figure 13)
Its page size is 16KB(= 1 << 14), size of pgd, pmd, pte is also 16KB. Its entry size is 8 bytes = (1 << 3)
| page size | 16KB |
| pgd bit size | 11 |
| pmd bit size | 11 |
| pte bit size | 11 |
| offset bit size | 13 |
In addition to bits which is defined by vanilla Linux, Xen/IA64 uses the following bits.
| _PAGE_VIRT_D | |
| _PAGE_TLB_TRACKING | pte_tlb_tracking() |
| _PAGE_TLB_INSERTED | pte_tlb_inserted() |
| _PAGE_TLB_INSERTED_MANY | pte_tlb_inserted_many() |
| _PAGE_PGC_ALLOCATED | pte_pgc_allocated() |
Pseudo physical address is used as pictured in figure 14. (pgd_index(), pmd_offset(), pte_index())
4.7.2 virtualizing itr.i, itr.d
- 1. When itr.i or itr.d issued, store its value into vcpu->arch.itrs[] or vcpu->arch.dtrs[]
- 2. When tlb miss fault occurs, Xen/IA64 looks up itrs[] or dtrs[].
- 3. If the corresponding translation is found, Xen/IA64 converts pseudo physical address to machine address, then issues itc.i or itc.d with machine address and 16KB page size and then returns execution to guest.
4.7.3 virtualizing itc.i and itc.d
- 1. When guest OS issues hyperprivop of itc.i or itc.d with pseudo physical address, cpu traps Xen/IA64.
- 2. Xen/IA64 converts pseudo physical address into machine address with the p2m table.
- 3. Then it issues itc.i or itc.d with machine address.
- 4. returns execution to guest OS.
4.7.4 virtualizing purging translation cache
Purging tlb is based on virtual address so that no address translation is required.
- ptc.e
purge translation cache entry - ptc.g, ptc.ga
purge global translation cache - ptc.l
purge local translation cache - ptr
purge translation register
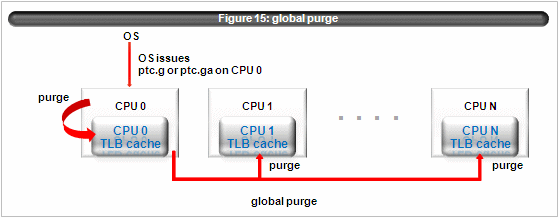
The figure 15 depicts the global purge.
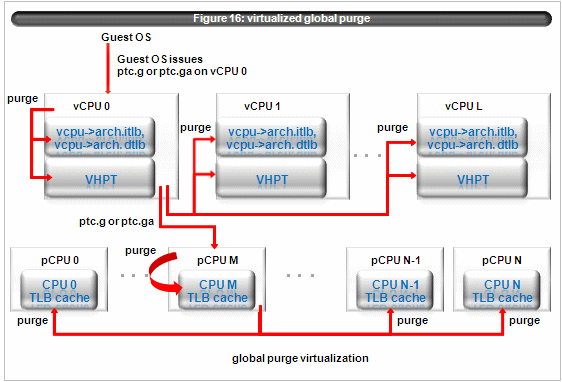
The figure 16 illustrates virtualized ptc.g or ptc.ga for domU.
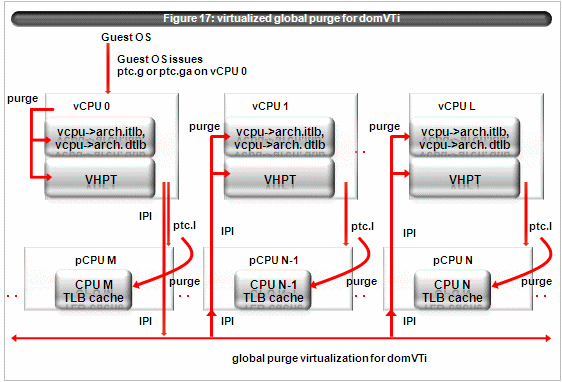
The figure 17 illustrates virtualized ptc.g or ptc.ga for domVTi.
4.8 metaphysical addressing
The term, metaphysical addressing, comes from vBlades. This is the mode which xen uses when guest OS disables its (virtualized) address translation. (see figure 18)
Xen/IA64 supports only the following address translation combinations.
- (it, dt, rt) = (0, 0, 0)
- (it, dt, rt) = (1, 1, 1)
- (it, dt, rt) = (1, 0, 1)
This combination is used by Linux when IR VHPT Data fault, VHPT instruction fault, VHPT Data fault.
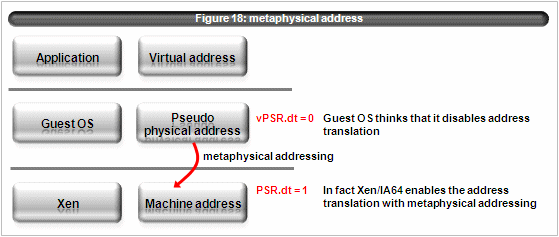
Where it, dt and rt is a bit of the psr register.
Xen/IA64 allocate dedicated rid for region 0 and region 4. (figure 19) Currently Xen/IA64 supports only region 0. When vPSR.dt is set to 0, it enters into metaphysical addressing mode. When vPSR.dt is set to 1, it leaves into metaphysical addressing mode. tlb miss handler have special address translation code for the virtual address in region 0 with metaphysical mode.

4.9 avoiding races
4.9.1 tlb insert and purge
When resolving tlb miss fault by ia64_do_page_fault(), there is a race with global tlb purge.
It can be determined by checking vcpu->arch.{i,d}tlb.
4.9.2 grant table and tlb purge/insert
Xen/IA64 grant table is based on pseudo physical address. i.e. When guest domain requests Xen/IA64 to map/unmap a granted page of another domain, Xen/IA64 updates the p2m table.
- mapping means inserting new entry into the p2m table.
- unmapping means purging the entry from the p2m table.
Then the domain issues tlb insert on the corresponding pseudo physical address. Thus the domain can access the page.
However its implementation becomes subtle because of the lock-less p2m table. Especially grant page unmapping is subtle because mVHPT and mTLB cache are dependent on the p2m table.(Figure 12) When the p2m entry is modified, mVHPT and mTLB must be flushed. And There are races with tlb inserting code path of Xen/IA64. I.e.
- virtualizing TR
– ia64_do_page_fault() - virtualizing itc
– vcpu_itc_i()
– vcpu_itc_d()
To avoid those races they check whether the p2m entry is modified by p2m entry retry(). If modified, they purge tlb cache and retry.
4.10 micro optimizations
4.10.1 vcpu migration between physical cpu
Figure 20: vcpu migrationvcpus of same domain use same region id and they may map different pseudo physical address into same virtual address. Linux ia64 per cpu variable is an example.
So when vcpus of same domain shares a same pcpu, VHPT and tlb cache must be flushed at each context switch. Xen/IA64 delays flush as a optimization. There are two cases to take care of. (figure 20)
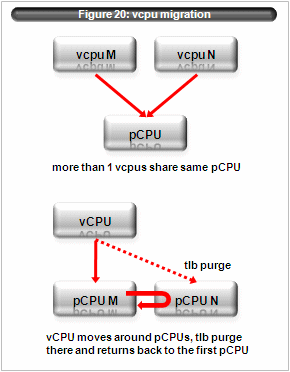
- more than 1 vcpu of a same domain share one pcpu
After one vcpu runs on a given pcpu, another vcpu of the same domain may execute on the same pcpu. In this case tlb entry which inserted by the first vcpu must flushed. Xen/IA64 delays such tlb flush until the second vcpu execution. If more than one domains execute, the number of tlb flush may be reduced. - one vcpu moves to another pcpu, issue tlb flush there and moves back.
In this case the first pcpu may still have stale tlb entries which should be flushed before guest execution. Xen/IA64 detects this case and issues tlb flush.
4.10.2 tlb flush clock
When full tlb flush is necessary, all VHPT entry and tlb cache must be flushed. The global tlb flush clock is the monotonic counter which is incremented when tlb is flushed. And tlb flush on each pcpu and vcpu is also tracked by their own counter.
By comparing those values, Xen/IA64 can detect unnecessity tlb flush and eliminate them.
4.10.3 tlb insert tracking
When the p2m entry is purged, VHPT must be purged. Purging all the entry of VHPT cost is very high, so it tries to track tlb insert and VHPT entry insert.
4.11 caveats and known issues
4.11.1 caveats
- referencing vcpu->processor isn’t SMP-safe
4.11.2 known issues
- probably there remains a race related tlb insert tracking hash table with purging tlb
- fix domain_flush_vtlb_all(). It should require struct domain as argument.
References
- Daniel J. Magenheimer, Thomas W. Christian, vBlades: Optimized paravirtualization for the Itanium processor family, Proceedings of the Third Virtual Machine Research and Technology, May 2004.
- Havard K. F. Bjerke, HPC Virtualization with Xen on Itanium, July 2005.