



4. Ceph のログ使い勝手の改善
「OpenStack/Ceph 異常系テスト (1)」では、特定のシステム構成で発生するハードウェア障害のパターン毎に、OpenStack インスタンス (VM) 上のアプリケーション I/O への影響と、コマンド (ceph –watch) 出力等に基づいた障害切り分けから復旧までの手順を見てきました。アプリケーション I/O への影響については、ハードウェアの故障を取り除くまでアプリケーションの I/O がブロックされる場合があることが分かりました。障害切り分けから復旧までの手順について、コマンド (ceph –watch) 出力だけでは障害箇所の特定ができない場合があることが分かりました。
そこで、ここからはログから障害の切り分けを行うことを想定した場合の、現状の Ceph ログの問題点とその対処案を検討します。
4.1. Ceph ログの問題点
まず、筆者の主観で Ceph ログの問題点を提示します。
対象の Ceph バージョンは Infernalis (v9.2.0) です。
本稿執筆時点 (2017年8月末) で Ceph バージョンはLuminous (v12.2.0) です。なお、10月 Web サイト掲載時点での最新バージョンは、9月28日にリリースされた Luminous (v12.2.1) です。
以下に述べる問題点の Jewel (v10.2.0) バージョン以降での状況は未確認です。
主に 2つの難しい点があると考えています。1つはログレベルの設定で、もう一つはログの解析です。
<ログレベルの設定の難しさ>
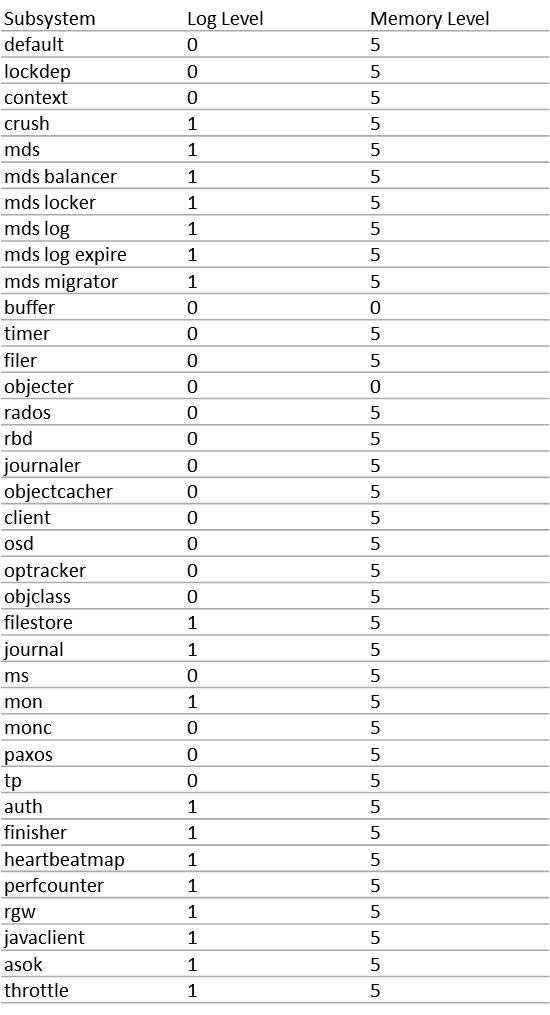
上記の表は、ログレベル設定に用いるパラメータの一覧とそれらのデフォルトの設定値です。サブシステム毎にログレベルとメモリログレベルの値を設定します。ログレベルというのは、ログファイルに出力するログ (以降、ファイルログと呼びます) のレベルです。メモリログレベルというのは、Ceph MON デーモンや Ceph OSD デーモン等のメモリ上のログ領域にサイクリックに記録するログ (以降、メモリログと呼びます) のレベルです。ある時点のメモリログはコマンド (ceph log dump) を実行することでファイルログにダンプすることができます。
ログレベルの値は高いほどログを出力するソースコード上のログ出力箇所が多くなるため、ログ出力頻度が上がります。ログレベルの値として有効な範囲は -1 から 40 です。
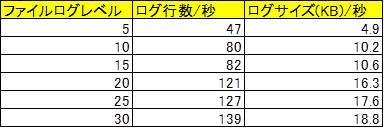
上記の表は、6台のサーバー (Ceph MON x 3台とCeph OSD x 3台) で構成された Ceph クラスタで、I/O 中のアプリケーションのないアイドル状態で出力されたログの量から求めたおよそのログ出力頻度です。全てのサブシステムについて同じログレベルを設定しています。
この結果からは、比較的低いログレベルの設定でもログ出力頻度は運用への影響が無視できないレベルであることが分かります。ログ出力による運用への影響は、ログの量だけでなく、I/O 性能の顕著な劣化としても現れる場合があります。また、メモリログに関してはメモリ上のログ領域にサイクリックに記録するので、メモリログレベルを高く設定すると、より広範囲のログが取得できる可能性がある反面、過去のログが上書きされるまでの時間が短くなり、障害発生時にメモリログをダンプするのに十分な時間的猶予を確保できなくなる可能性があります。よって、運用への影響を回避しつつ、できるだけ詳細なログをできるだけ長時間確保するための、サブシステム毎の最適なログレベル/メモリログレベル設定が求められます。
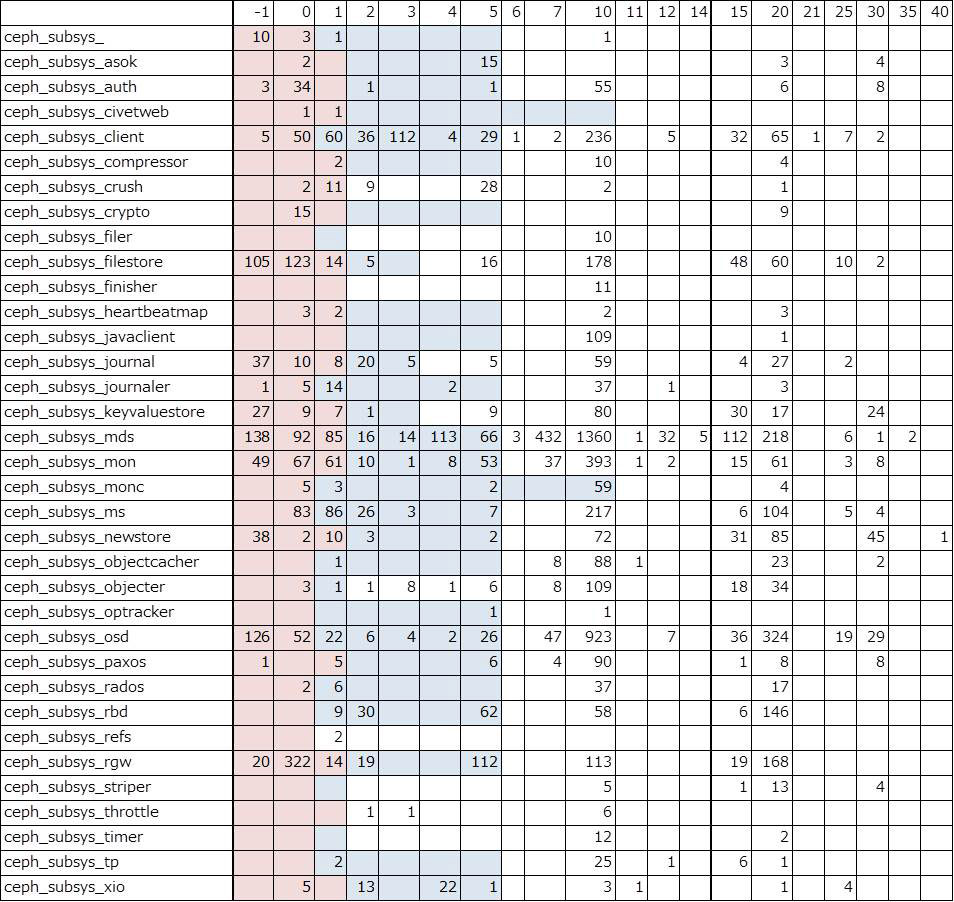
上記の表は、サブシステムおよびログレベル毎のソースコード上のログ出力箇所の数をカウントした結果です。全部で約 9,700 箇所あります。紫色のマークはデフォルトのログレベル範囲を表します。つまり、ファイルに残るログを出力している箇所です。水色のマークはデフォルトでメモリログレベル範囲を表します。つまり、メモリ上にサイクリックに記録されるログを出力している箇所です。 サブシステム毎の最適なログレベル/メモリログレベル設定には、これらのログ出力箇所のコードが実行される頻度に関する情報が必要と思われます。
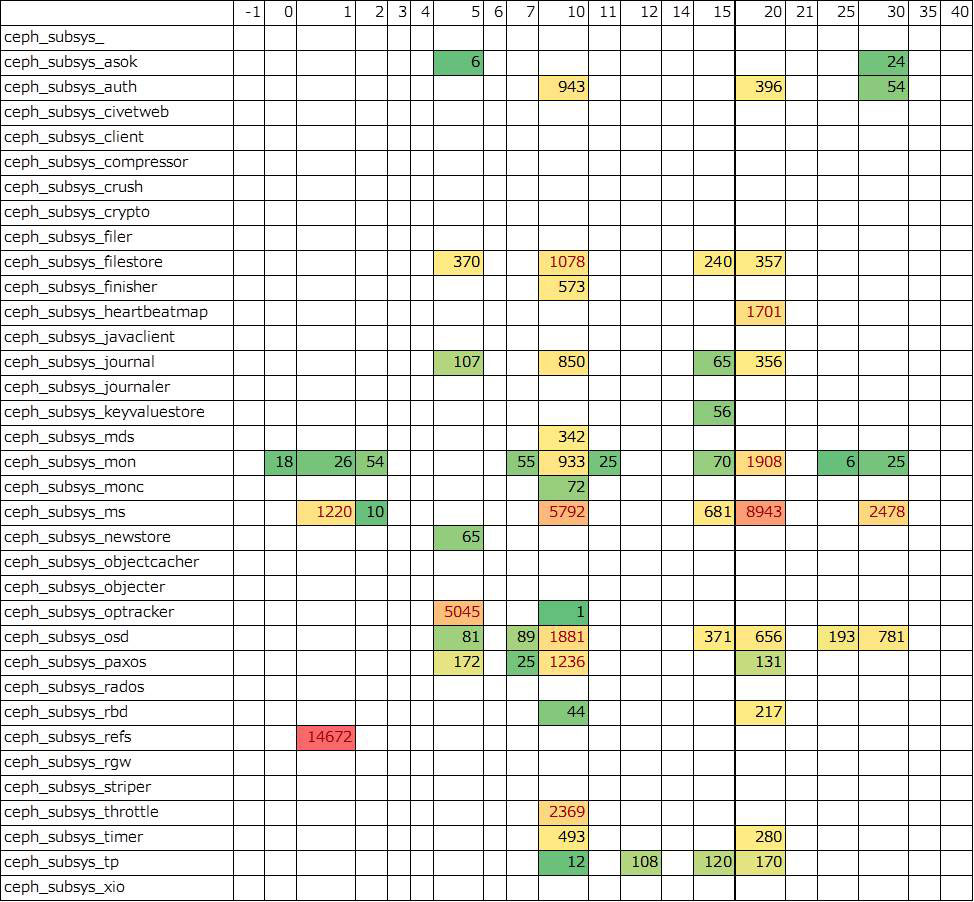
上記の表は、ある検証項目を実施したときに 6ノードの Ceph クラスタで出力されたログのログレベル分布です。 セルの値はログ出力件数です。頻度の高いものは赤、比較的低いものは緑色になっています。各 Ceph ノードのメモリ上のログ領域は 1万行に設定されているため、ログは全部で 6万件あります。 しかし、このログでカバーしている時間的範囲は 6 ノード合計で 210秒程度に過ぎません。 つまり、問題が発生からログを取得するまでの時間的猶予が非常に限られている状況です。現実的な時間的猶予でログを取得できるようにするためにはメモリ上のログ領域を拡大するだけでなくセルの赤い箇所のログを削減する必要があると思われます。
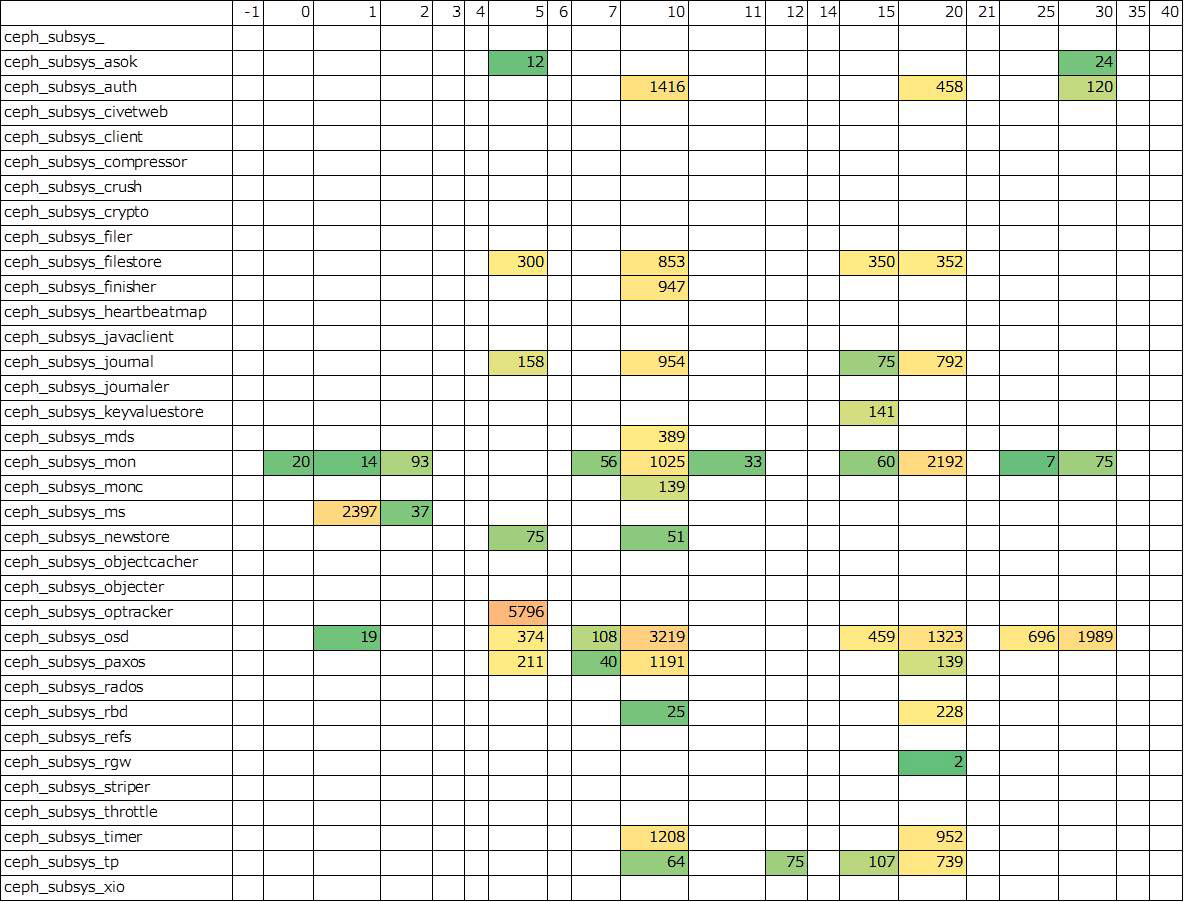
上記の表は、先程の表でセルが赤かった箇所のログを出ないようにログレベルを変更した後の様子です。先程と同じく 6ノード全部で 6万行のログ領域に対して 6ノード合計で 330秒間のログを格納してログは全部で 3万件に抑えられています。つまり、検証項目を実施したときに 6ノードの Ceph クラスタで出力されたログが全て残っている状況です。 このようにログ出力頻度の高い箇所を避けるようにログレベルを設定することでメモリ上にログが残る時間を延長することが可能です。本稿での検証は、90分間のメモリログが取得できるログレベル設定を目標とします。
<ログの解析の難しさ>
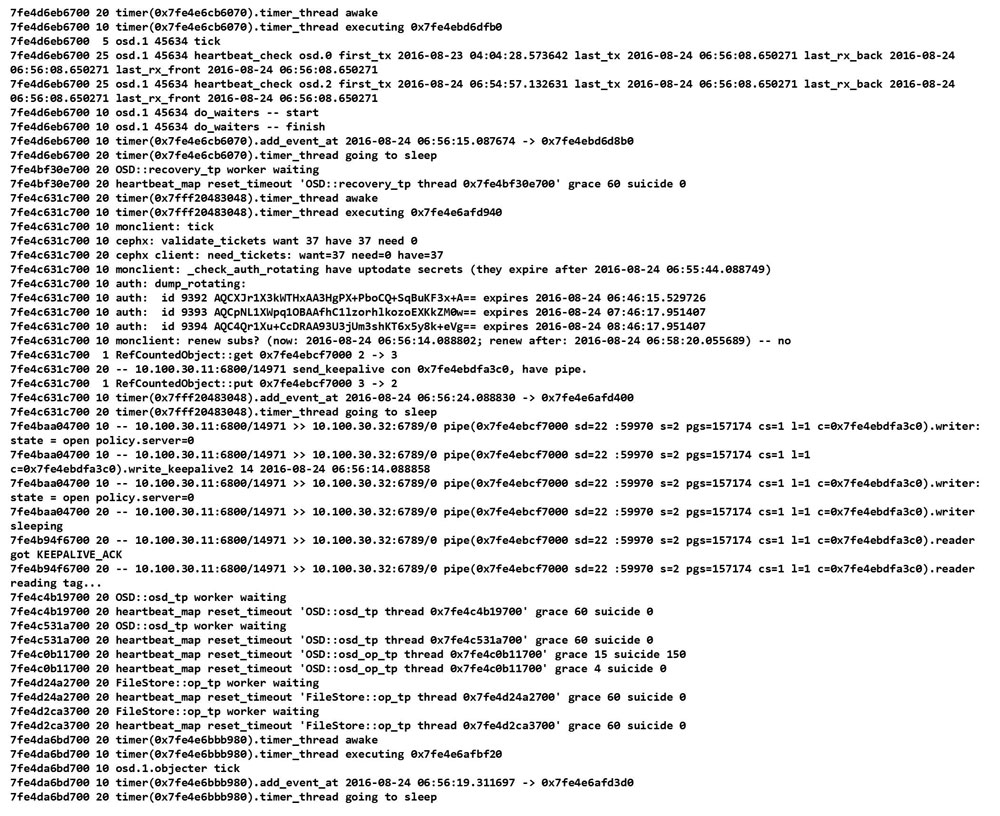
上記は Ceph OSD サーバーで出力されたログのサンプルです。各ログ行は数カラムのタイムスタンプ部から始まりますが、その部分は省略しています。最初のカラムの 7fe4d6eb6700 のような値はスレッド毎の値です。2番目のカラムはログレベルです。3番目のカラム以降がログメッセージです。
障害発生時に上記ログから切り分けを行おうとした場合を想定すると、まず、各ログを出力しているソースコード上の場所を、ログメッセージに含まれるキーワード等でソースコードを検索して特定し、次に、前後のログ行を出力しているソースコード上の場所から処理の流れを類推することになります。
「1. OpenStack/Ceph の現状と課題」の「1.2. Ceph を選択する課題」で述べたように、Ceph のコード規模は Linuxカーネルに含まれるすべてのファイルシステムのコード (linux-4.7/fs) の総量におよそ匹敵する大きさがあります。現実的な時間的コストで、ログメッセージに含まれるキーワードでソースコードを検索してログ出力箇所を特定し、さらに複数のログ出力箇所からそれらを通る処理ルートを類推するためには、予め何らかの準備が必要と思われます。
4.2. Ceph ログの問題点への対処
ログから障害の切り分けを行うことを想定した場合の Ceph ログの問題点として、ログレベルの設定やログの解析の難しさについて述べました。 ここからは、これらの問題点に対して本稿で実施したアプローチについて説明します。
ログレベルの設定の難しさについては、以下の仮定に沿って試行しました。
- 仮定 1. 障害のパターン毎に実行される処理の集まりに傾向がある
- 仮定 2. 処理の集まりの傾向は、出力するログの傾向に現れる
- 仮定 3. 出力されたログの傾向から障害のパターンを類推できる
ログの解析の難しさについては、以下の仮定に沿って試行しました。
- 仮定 4. 一連のログからそれらを出力した関数セットを抽出できる
- 仮定 5. 処理ルートは関数ペアの呼び出し関係の集まりとして記述できる
- 仮定 6. 一連のログから調査すべき処理ルートの候補を抽出できる
実施した作業ステップは以下の 7つです。
【作業ステップ】
- ステップ 1: Ceph クラスタのログを回収・管理する仕組みの作成
- ステップ 2: ログ行にログ出力箇所を付加する仕組みの作成
- ステップ 3: 障害パターン毎に特徴的なログの抽出
- ステップ 4: ログレベル設定
- ステップ 5: 処理ルートデータベースの作成
- ステップ 6: ログ出力箇所を通る処理ルートを検索する仕組みの作成
各ステップについて概要を説明します。
■ ステップ 1: Ceph クラスタのログを回収・管理する仕組みの作成
Ceph は複数のノードで構成されたクラスタで動作するので、障害調査には、クラスタ単位で同じ時間帯のログが必要とされる場合があります。 性能の観点から、運用時のログレベルは低く設定することが望ましいため、調査に必要とされる詳細なログはメモリログに取得する必要があると考えられます。そこで、クラスタ単位でログの取得開始、終了、回収を一括で行い、ユニークなログ ID に紐づけたログアーカイブで管理する仕組みを作成します。ログの取得終了時にはメモリログのログファイルへのダンプも行います。
■ ステップ 2: ログ行にログ出力箇所を付加する仕組みの作成
ソースコード上のログ出力箇所を洗い出し、それぞれについてサブシステム、ログレベル、クラス、メソッド、正規表現化したログメッセージを抽出します。次に、実際のログ行に含まれるログメッセージをキーに、各行にログ出力箇所を (クラス::メソッド) の形式で付加するスクリプトに加工します。このスクリプトは、ステップ 1で取得したログアーカイブに対して実行します。
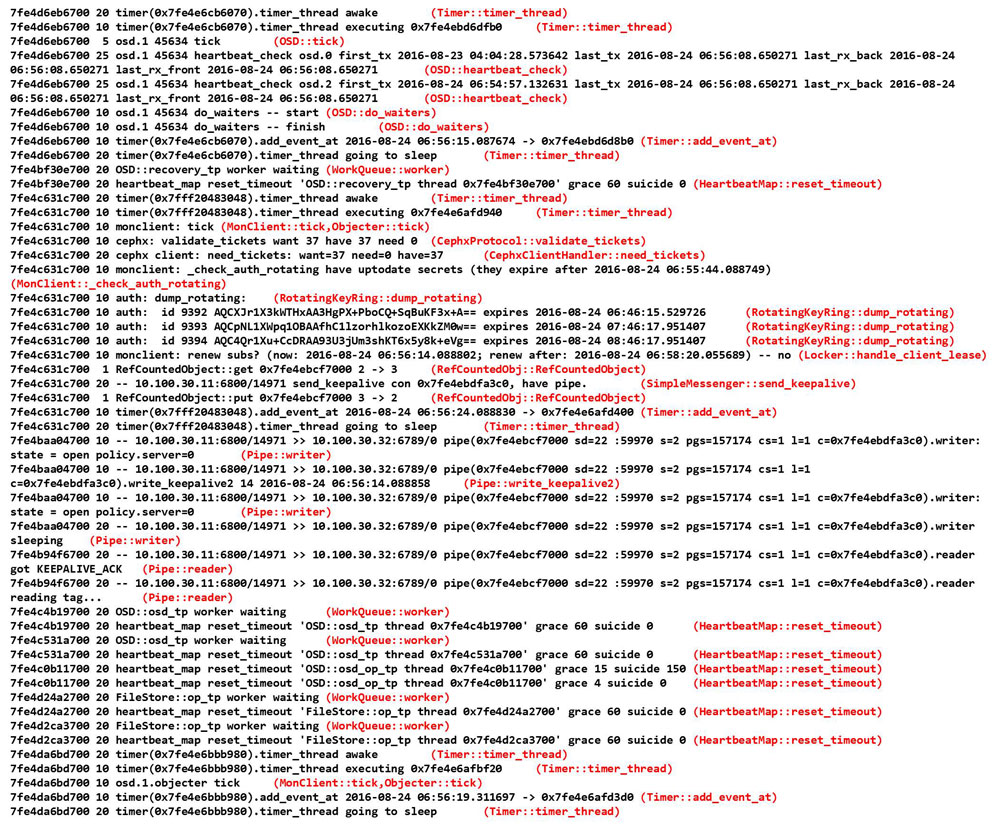
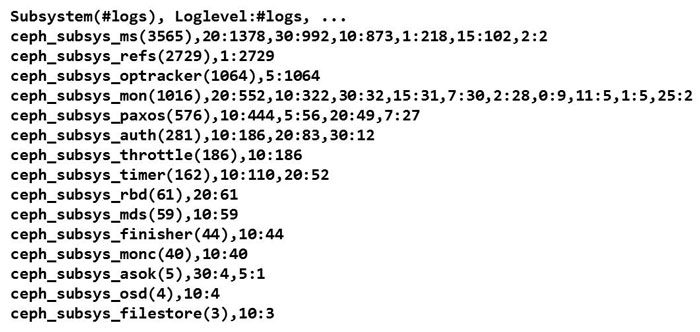
上記の 2つの図はスクリプトを実行した結果の一部です。各ログ行にログ出力箇所が付加される他、サブシステムおよびログレベル毎のログ出力回数をカウントします。
■ ステップ 3: 障害パターン毎の特徴なログの抽出
OpenStack/Ceph 異常系テストの実施の際にステップ 1 の仕組みで障害パターン毎のログアーカイブを取得します。各ログアーカイブに対してステップ 2 のスクリプトを実行することで、障害パターン毎のログのサブシステムおよびログレベルの分布を抽出します。各障害パターンのログレベル分布を、障害がない状態で同じオペレーションを実行したときにログレベル分布と比較することで、その障害パターンによって出力された可能性が高いログを抽出します。
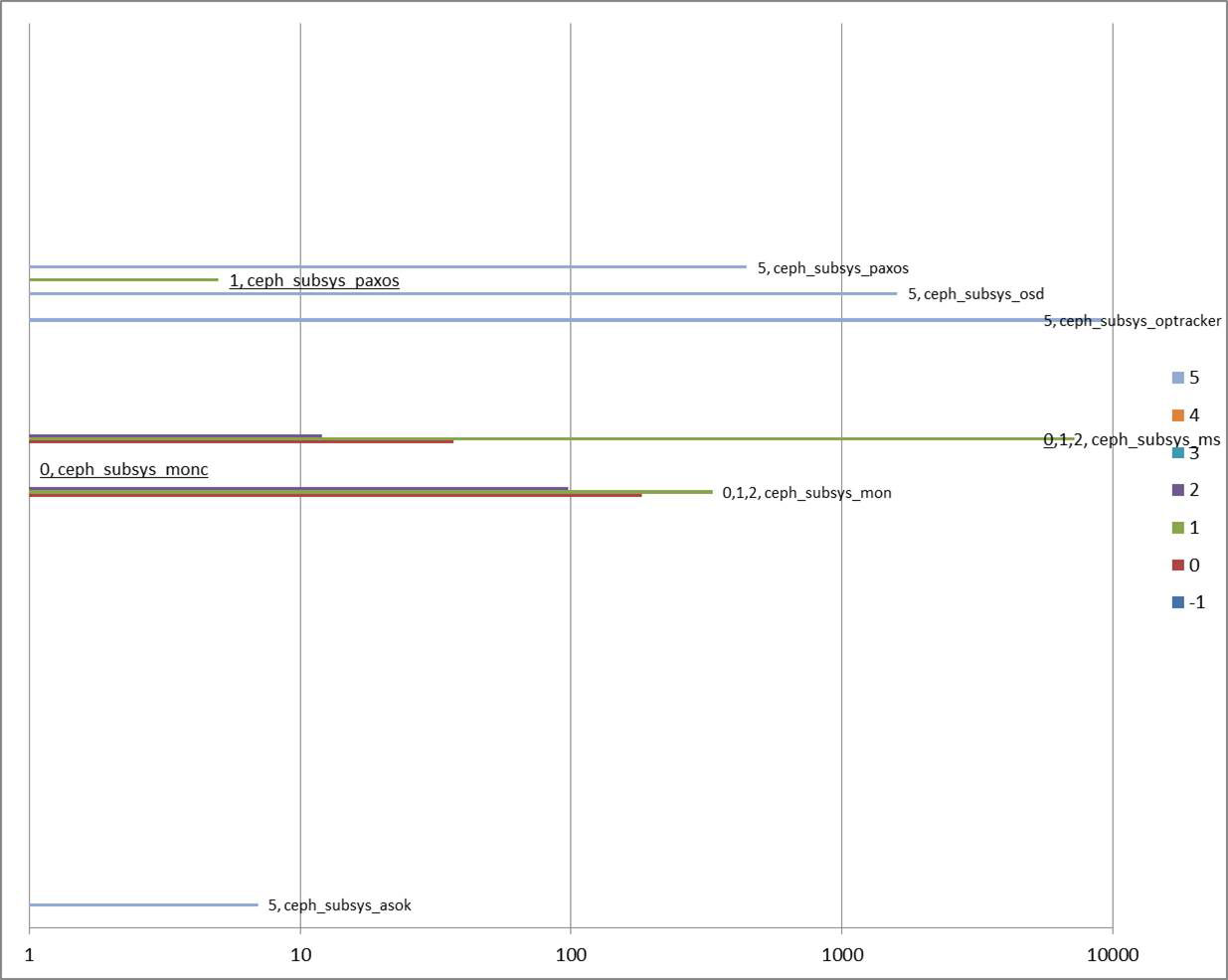
上記の図は、OpenStack/Ceph 異常系テストのテスト項目 (故障パターン) のうち、テスト項目 #1 の通常の状態と、テスト項目 #34 の 3台中 2台の Ceph MON でダウンが発生した場合でのログレベル分布を比較した例です。丸で囲ったサブシステムとログレベルのログがテスト項目 #34 でのみ出力されていたことを表します。
「3. OpenStack/Ceph 異常系テスト (1)」の「3.4. テスト結果」で述べたとおり、テスト項目 #34 では、コマンド (ceph –watch) の出力から Ceph MON がダウンしていることが判別できませんでした。
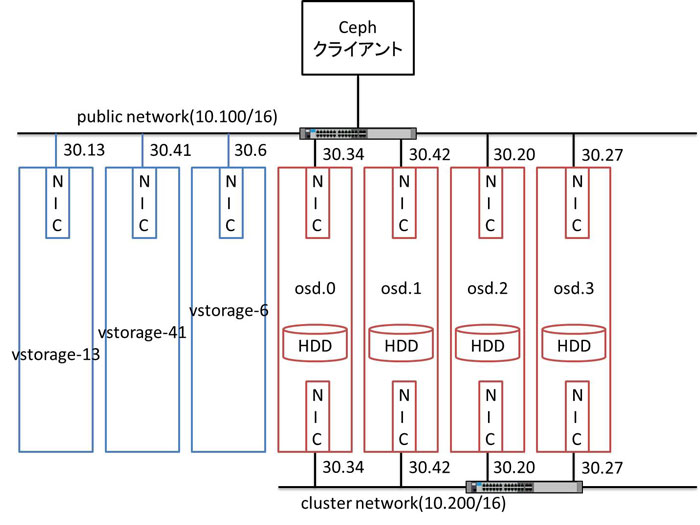
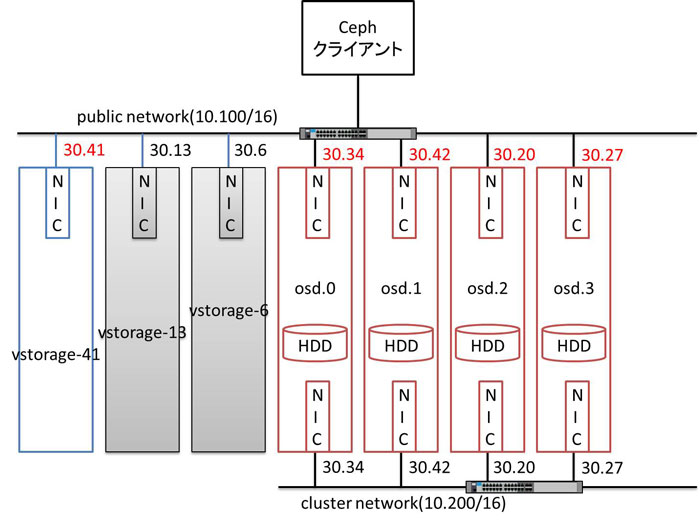
上記の図はテスト項目を実施したときの Ceph クラスタの構成です。
具体的には、2台の Ceph MON がダウンしたにも関わらず、コマンド (ceph –watch) の出力上では、1台の Ceph MON が停止し HELTH_WARN に状態遷移し、当該 Ceph MON 再起動後に HEALTH_OK に状態したように見え、もう 1台の Ceph MON が停止したことが分かりませんでした。
Ceph MON クラスタは奇数台数で構成され、その動作には多数派を形成できる台数 (=定足数) が健全である必要があります。テスト項目 #34 では、3台で構成された Ceph MON クラスタのうち 2台がダウンしてしまうため、健全な Ceph MON の台数=1 が定足数=2 に満たない状況となります。また、コマンド (ceph –watch) の動作は Ceph MON クラスタが動作していることに依存します。よって、Ceph MON クラスタの定足数がない状態で発生した、もう 1台の Ceph MON が停止、再起動の事象を、コマンド (ceph –watch) が正常に動作せず検知できなかったものと思われます。
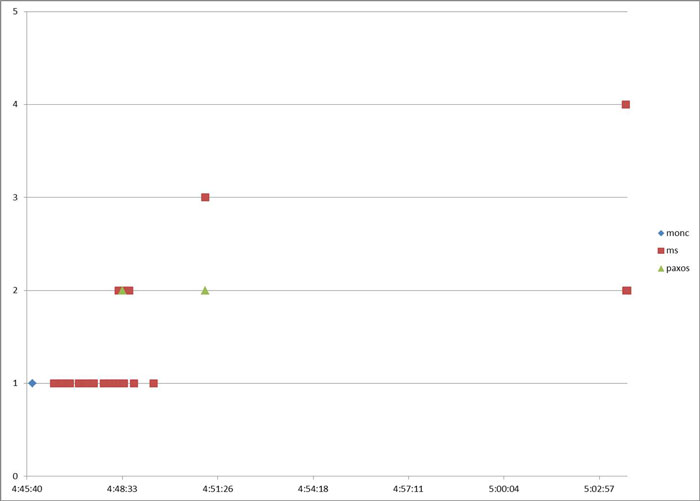
上記の図は、テスト項目 #1 の通常の状態ログレベル分布を比較して抽出された、テスト項目 #34 でのみ出力されていたログの時系列での件数分布です。
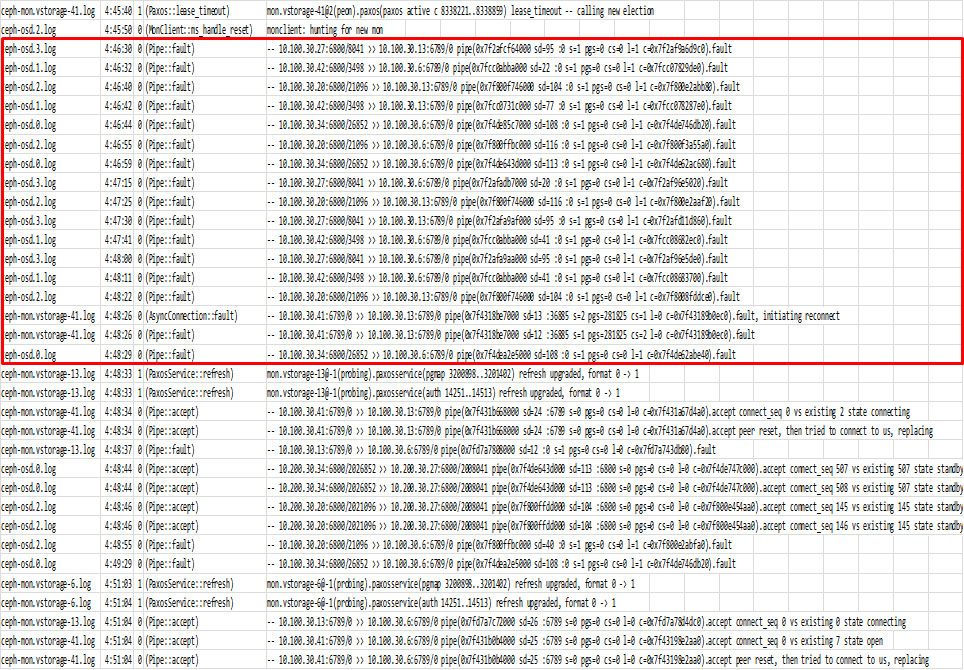
上記の図は、テスト項目 #1 の通常の状態とのログレベル分布を比較して抽出された、テスト項目 #34 でのみ出力されていたログ行です。赤線で囲った部分は、2台の Ceph MON への通信が、その他全てのノード上で失敗している状況を表示しています。
上記の図は、テスト項目 #34 でダウンさせた Ceph MON 2台を灰色で示し、テスト項目 #1 の通常の状態のログレベル分布を比較してテスト項目 #34 でのみ出力されていたログにある通信失敗の箇所を赤文字で示しています。つまり、テスト項目 #34 の実施によって検出された、コマンド (ceph –watch) で現象 (3台中 2台の Ceph MON ダウン) を検知できない問題に対する代替手段として、故障パターンに特徴的なログの内容 (通信が失敗している箇所) から現象を推測する方法が確認できたと思います。
■ ステップ 4: ログレベル設定
全てのサブシステムおよびログレベルの組み合わせのうち、ステップ 3 で抽出した障害パターンに特徴的なログを出力したサブシステムおよびログレベルの組み合わせを抽出します。
抽出されたサブシステムおよびログレベルの総和でログレベルを設定します。このログレベル設定でログ頻度が高くなり過ぎてメモリログが短時間でサイクルしてしまう場合は、ログ出力頻度の高い箇所を避けるようにログレベルを調整することでメモリ上にログが残る時間を延長します。
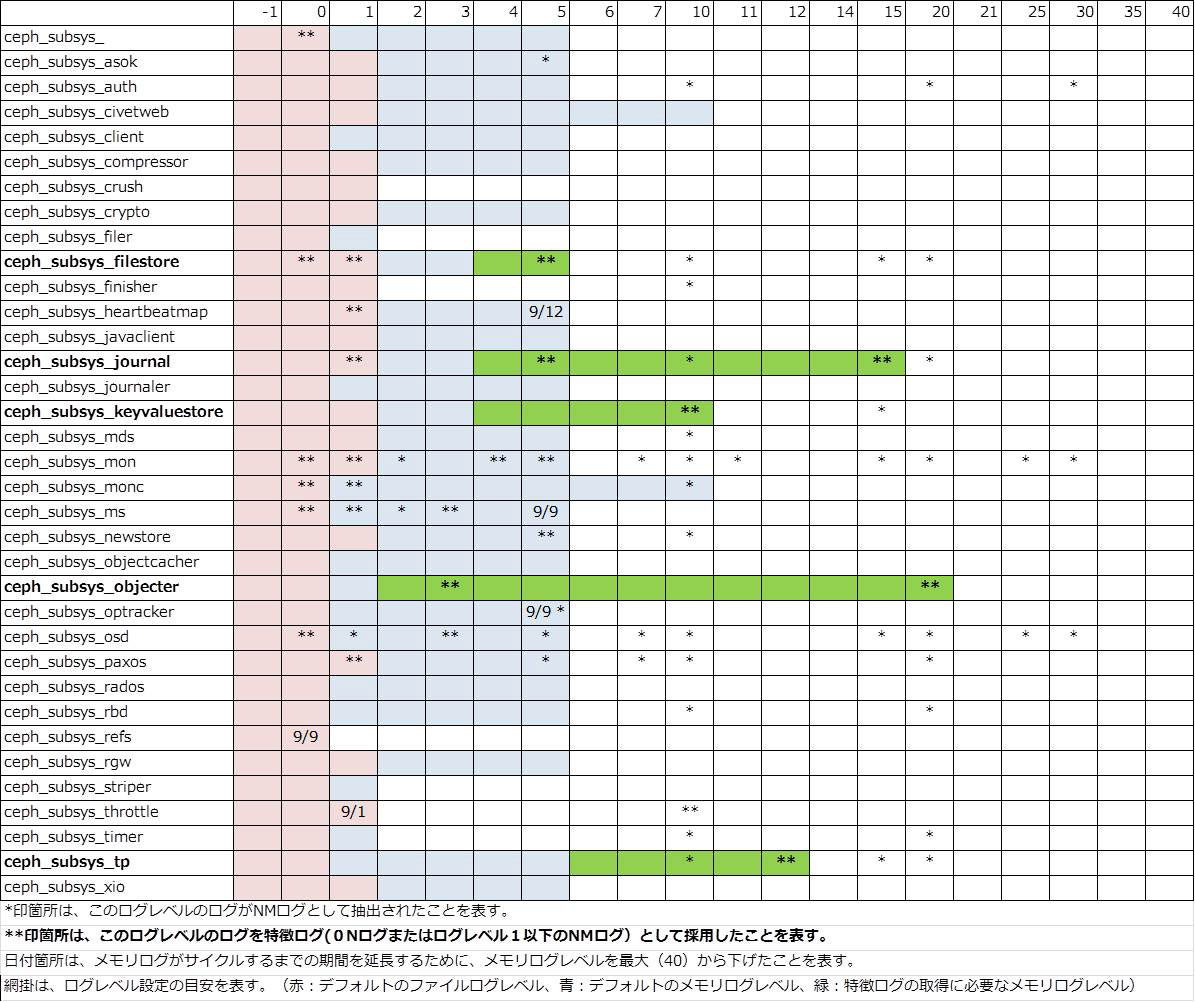
図は、「5. OpenStack/Ceph 異常系テスト (2) 」で述べるテストを通して得られたログから抽出したログレベル設定です。緑色のマーク部分はデフォルトのメモリログレベルから変更していることを表します。
■ ステップ 5: 処理ルートデータベースの作成
ソースコード上の関数呼び出し箇所を洗い出し、それぞれについて呼び出し元クラス::メソッド、呼び出し先クラス::メソッドを抽出します。次に、処理ルートを抽出し、処理ルートデータベースとします。
処理ルートの抽出は、呼び出されることのないクラス::メソッドから何も呼び出さないクラス::メソッドに至るまでの一連の関数呼び出し関係を機械的に検索することで行います。関数呼び出しを行うかどうかは多くの場合に条件がありますが、この機械的な検索において条件は考慮しません。つまり、関数呼び出しの条件は常に真です。よって処理ルートデータベースには実際には通ることのない処理ルートが多数含まれます。
■ ステップ 6: ログ出力箇所を通る処理ルートを検索する仕組みの作成
任意のログに対してステップ 2 のスクリプトを実行することにより、ログに含まれているログ出力箇所のリストが得られます。これらのログ出力箇所のうちの 1個から N個を含むような処理ルートをステップ 5の処理ルートデータベースから検索します。
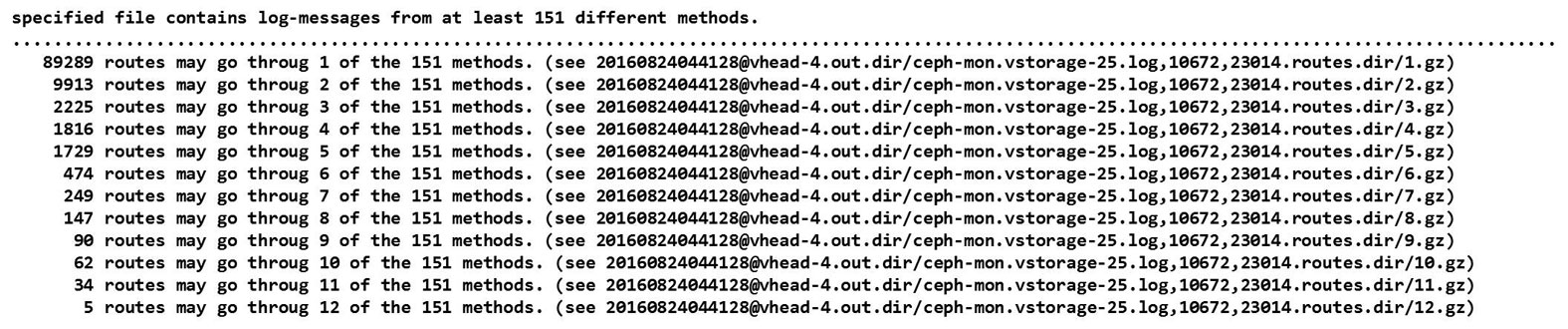
上記の図は、処理ルートデータベースを検索した結果のうち、検索で見つかった処理ルートの数の表示です。

上記の図は、処理ルートデータベースを検索した結果のうち、12 のログ出力箇所を通る 5つの処理ルートに関する内容です。
ログから障害の切り分けを行うことを想定した場合の、現状の Ceph ログの問題点とその対処案を検討については以上です。この後に述べる「5. OpenStack/Ceph 異常系テスト (2) 」においては、対処方法の情報として、ログだけからハード障害を切り分けできるかどうかという観点を加えています。