「Linuxカーネル2.6解読室」(以降、旧版)出版後、Linuxには多くの機能が追加され、エンタープライズ領域をはじめとする様々な場所で使われるようになりました。
それに伴いコードが肥大かつ複雑化し、多くのエンジニアにとって解読不能なブラックボックスとなっています。
世界中のトップエンジニア達の傑作であるLinuxカーネルにメスを入れ、ブラックボックスをこじ開けて、時に好奇心の赴くままにカーネルの世界を解読する「新Linuxカーネル解読室」プロジェクト。
本稿では、(その1)に引き続き、カーネルv6.8におけるタスクスケジューラの仕組みや実装について解説したいと思います。
執筆者 : 西村 大助
※ 「新Linuxカーネル解読室」連載記事一覧はこちら
はじめに
(その1)ではスケジューリングクラスといったタスクスケジューラの基本的な考え方について簡単に解説しました。
本稿(と次の記事)では、少し踏み込んで「どのタスクをどの程度実行するか」をどのように決定しているかという、タスクスケジューラの最重要機能を、スケジューリングクラス毎に解説したいと思いますが、本稿では、まず現在デフォルトのスケジューリングクラスとなっているEEVDFについて解説します。
なお、章節番号は(その1)からの連番となっています。
3. どのタスクをどの程度実行するか
(その1)の「1.2.3 スケジューラコアとスケジューリングクラス」でも軽く触れましたが、次に実行すべきタスクを選択する__pick_next_task()は簡単に言うと以下のようになっており、スケジューリングクラスの優先度順に各スケジューリングクラスのpick_next_task()ハンドラを呼びだしていって、最初に見つかったものを返すようになっています。
(kernel/sched/core.c)
6052 for_each_class(class) { 6053 p = class->pick_next_task(rq); 6054 if (p) 6055 return p; 6056 }
また、これも(その1)の「2.2 タスクスケジューラによりCPUを明け渡す場合」で触れましたが、タスクをどの程度実行するかは、タスクスケジューラがどれくらいの時間でTIF_NEED_RESCHEDを立てるかで決まってきます。
本章では、FAIR(EEVDF)、RT、DL(DeadLine)のそれぞれのスケジューリングクラスにおいてタスクがどのように管理されているかを解説しつつ*1、それらのpick_next_task()ハンドラの処理内容や、TIF_NEED_RESCHEDを立てるタイミングやその条件について具体的に見ていきたいと思います。
3.1 FAIR(EEVDF)
3.1.1 概要
EEVDF(Earliest Eligible Virtual Deadline First)*2は、v6.6でそれまでのCFS(Complete Fair Scheduler)に置き換わり導入された比較的新しいスケジューリングアルゴリズムですが、その考え自体は1995年の論文で登場した物です。
また、ソースコードや内部構造は既存のCFSから引き継いでいる物も多いため、後述するようにデータ構造の名前などには今でも"CFS(cfs)"という用語が残っています。
本稿ではCFSの詳細については触れませんが、CFSにしろEEVDFにしろ、スケジューリングクラスの名が示す通り、タスクに対して「FAIR(公平)」にCPU時間を割り当てる事を目的としています。
CFSではnice値に応じてCPU時間を公平に割り当てる事が出来ましたが、nice値を下げても(優先度を上げても)CPU時間が多く貰えるというだけで早くCPUが割り当てられるとは限らないため、latencyという意味では必ずしもうまく機能しませんでした*3。
EEVDFは、その名の通り「"eligible"なタスクなうち、"virtual deadline"が一番早いタスク」に実行権を与えますが、CPU時間をnice値に応じて公平に割り当てつつ、nice値に応じてCPUの割り当てタイミングも早くなるように工夫されていて、CFSにあったlatencyの問題も改善しようとしています。
この"eligible"や"virtual deadline"とは何かを説明する前に、いくつかの重要なパラメータを説明します。また、議論を単純化するため、全てのタスクが常にCPUを奪い合っているような理想的な状況を想定して、議論を進めます。
- weight(
)*4
- 文字通りタスクの「重み」を表す正数で、高優先度程大きくなります。
- 実装上は、
sched_prio_to_weight[]という配列を元にnice値から計算されます。 - EEVDFではタスク
の理想的な実CPU時間(
)を、実経過時間(
)のうちの、当該タスクのweightの割合分*5としています。
ただし、
- vruntime(
)*6
- VirtualRuntimeと呼ばれる仮想的なCPU時間で、タスクに割り当てられた実CPU時間(
)をweightで割った物です。
- タスクに割り当てられた実CPU時間が同じでも、vruntimeは優先度が大きい程は小さく(逆に優先度が小さい程大きく)なります。
- VirtualRuntimeと呼ばれる仮想的なCPU時間で、タスクに割り当てられた実CPU時間(
- lag(
)
- 理想的な実CPU時間(
- 前述のvruntime同様、weightを加味した仮想的なlagとしてvlag(
)を定義すると、
なので、とすると、vlag(
- 理想的な実CPU時間(
- slice
- タスクのtime sliceで、v6.8では固定値*7となっています。
- slice にもこれまで同様にweightを加味した仮想的なvslice(
)を定義できます。
話を"eligible"と"virtual deadline"に戻します。
EEVDFにおいてタスクが"eligible"とは、
が0以上である事である事を指し、意味としては「実際に割り当てられたCPU時間が、本来割り当てられるべきCPU時間に達していない(もしくは一致する)」という事になります。また、その定義から計算すると、
であるとも言えます。
次に、"virtual deadline"()ですが、
と定義されていて、nice値が小さければ(weightが大きければ)、その定義からや
、"virtual deadline"(
)も小さくなり、(詳細は後述しますが)EEVDFでは"virtual deadline"の大きさによりタスクの割り当て順を決める(小さい程早くなる)ので、より早くタスクに実行権が割り当てられるようになります(そうする事でCFSにあったlatencyの問題を改善しようとしています)。
数式が続きましたが、冒頭の「"eligible"なタスクなうち、"virtual deadline"が一番早いタスク」に実行権を与えた際の動きをイメージするため、具体例を使って各パラメータの変化を見てみましょう。
それぞれのweightが,
な3つのタスク(
,
,
)が同時に実行可能になったとします。
なので、割り切れるようにsliceを10とすると、
はslice毎に2ずつ増える事になります。また、
,
なので、初期状態(
)での各タスクの
(上段)と
(下段)、および
を整理すると以下のようになります。

この状態では、どのタスクも"eligible"()ですが、
の近さから
(ないしは
)に実行権が与えられることになります。
ここから、「"eligible"なタスクなうち、"virtual deadline"が一番早いタスク」に実行権を与えるというルールの元、(上段)と
(下段)、および
がslice毎にどのように変化していくか整理すると以下のようになり(薄青:eligible、薄赤:not eligible、赤矢印:実行状態)、
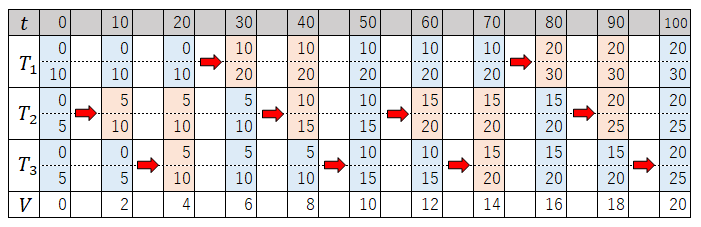
weightの比率に応じて実行権が割り当てられる頻度が変わる事がわかります。
最後に、前述のに関して、もう少し掘り下げます。
は
(weightあたりの平均CPU時間)と定義しましたが、全てのタスクがCPUを奪い合っているような理想的な状況では、実経過時間と各タスクのCPU時間の合計が一致するので*8、
とすることができます。これを前述の定義から整理すると、
となります。
ここで、タスクに依存しない値を考えると、
と書けるので*9、展開して整理すると、
となります(この式や式を構成する各項はまた後で出てきます)。
3.1.2 cfs_rq構造体とsched_entity構造体
EEVDFでは、CPU毎のランキューに対応する物としてcfs_rq構造体(以降、cfs_rq)、タスクに対応する物としてsched_entity構造体(以降、sched_entityまたはse)を使います*10。
具体的には、se->run_nodeをcfs_rq->tasks_timelineをrootとしたrb-treeに挿入していく事で、実行可能なタスクを管理していますが、このrb-tree内での「大小」はse->deadline(前述の"virtual deadline"()に相当)で決まる(下記の
entity_before()参照)ので、
551 static inline bool entity_before(const struct sched_entity *a, 552 const struct sched_entity *b) 553 { 554 /* 555 * Tiebreak on vruntime seems unnecessary since it can 556 * hardly happen. 557 */ 558 return (s64)(a->deadline - b->deadline) < 0; 559 }
次に実行するタスクは、基本的にこのrb-treeのleft-mostなseに対応するタスク("virtual deadline"()が最も小さいタスク)、という事になります*11。
具体的な実装を見る前に、前項で解説したパラメータが、実装上cfs_rqやseのどのメンバに対応するのかを整理すると以下のようになります*12。
| パラメータ | 対応 |
|---|---|
| weight( |
se->load.weight |
| vruntime( |
se->vruntime |
| vlag( |
se->vlag |
| slice( |
se->slice |
| virtual deadline( |
se->deadline |
cfs_rq->min_vruntime |
|
cfs->rq->avg_vruntime |
|
cfs_rq->avg_load |
当然と言えば当然ですが、タスク固有のパラメータはse、タスク全体に関するパラメータはcfs_rqのメンバに対応している事がわかります。
3.1.3 V
本項から、前項までの内容を念頭に、実際の実装についてソースレベルで解説していきたいと思います。
具体的な処理の前に、weightあたりの平均CPU時間であるがどのように計算されるかを見てみましょう。
結論から書くと、は
avg_vruntime()で求められる値となります。
656 /* 657 * Specifically: avg_runtime() + 0 must result in entity_eligible() := true 658 * For this to be so, the result of this function must have a left bias. 659 */ 660 u64 avg_vruntime(struct cfs_rq *cfs_rq) 661 { 662 struct sched_entity *curr = cfs_rq->curr; 663 s64 avg = cfs_rq->avg_vruntime; 664 long load = cfs_rq->avg_load; 665 666 if (curr && curr->on_rq) { 667 unsigned long weight = scale_load_down(curr->load.weight); 668 669 avg += entity_key(cfs_rq, curr) * weight; 670 load += weight; 671 } 672 673 if (load) { 674 /* sign flips effective floor / ceil */ 675 if (avg < 0) 676 avg -= (load - 1); 677 avg = div_s64(avg, load); 678 } 679 680 return cfs_rq->min_vruntime + avg; 681 }
注意が必要なのは、3.1.2で「タスク全体に関するパラメータはcfs_rqのメンバに対応している」と書きましたが、cfs_rqのメンバには今、実行状態にあるタスクの情報は反映されていないことです。これは、cfs_rqの各メンバで管理されているのは、rb-treeに乗っているタスク全体に関する情報であるが、実行状態にあるタスクはrb-treeには乗っていないためです。一方で、実際に必要になるのは、実行状態にあるタスクも含めた全体の情報になるので、L666-L671のように、実行状態にあるタスクの情報は必要に応じて計算・加算するようにしています(同じようなコードが随所に見られますが、同じ理由によるものです)。
この事に注意した上で、3.1.1で提示した、の計算式である
と、cfs_rqの各メンバとの対応表を見ると、この関数によりが計算できるとわかると思います。
3.1.4 enqueue
enqueue処理がどのように実装されているか、各パラメータに注目しながら見ていきましょう。
enqueue処理について解説する理由は、「どのタスクをどの程度実行するか」に深く関わってくる"virtual deadline"()を計算するのがenqueue処理の時だからです。
EEVDF(SCHED_FAIR)のenqueue()ハンドラは、enqueue_task_fair()ですが、本質的な処理の多くはその延長で呼ばれるplace_entity()と__enqueue_entity()で行われており、大まかに言うと、place_entity()でse->deadline等のパラメータを設定して、__enqueue_entity()でrb-treeに挿入するという流れになっています。
place_entity()ですが、コメント等を省いて主な処理だけを抜き出すと以下のようになっています。
5157 static void 5158 place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags) 5159 { 5160 u64 vslice, vruntime = avg_vruntime(cfs_rq); 5161 s64 lag = 0; 5162 5163 se->slice = sysctl_sched_base_slice; 5164 vslice = calc_delta_fair(se->slice, se); 5165 ... 5174 if (sched_feat(PLACE_LAG) && cfs_rq->nr_running) { 5175 struct sched_entity *curr = cfs_rq->curr; 5176 unsigned long load; 5177 5178 lag = se->vlag; ... 5232 load = cfs_rq->avg_load; 5233 if (curr && curr->on_rq) 5234 load += scale_load_down(curr->load.weight); 5235 5236 lag *= load + scale_load_down(se->load.weight); 5237 if (WARN_ON_ONCE(!load)) 5238 load = 1; 5239 lag = div_s64(lag, load); 5240 } 5241 5242 se->vruntime = vruntime - lag; ... 5252 /* 5253 * EEVDF: vd_i = ve_i + r_i/w_i 5254 */ 5255 se->deadline = se->vruntime + vslice; 5256 } 5257
処理の流れとしては、
- se->
sliceの設定(固定値)と - se->
vruntime()を
と
- se->
deadline()を計算(L5255)
となっています。基本的には定義に基づいて計算しているだけですが、の計算(L5174-L5240)は少々わかりづらいので説明します。
まず、L5178でse->vlagをのベース値としていますが、se->
vlagはdequeue時に計算されたvlagです。ベース値をそのまま使用せず、L5232-L5239でさらに補正しているのは、enqueueを行う事によるへの影響を加味するためです。
というのも、
の計算式は前述の通りですが、この式は全てのタスクがCPUを奪い合っているような理想的な状況でしか成り立ちませんが、実際のシステムでは、タスクのsleep(dequeue)やwakeup(enqueue)等も発生し、それによる
への影響も無視できないためです。詳細は前述した論文を参照して頂きたいのですが、タスク
のenqueueに伴い、
は以下のように変化します(
付はenqueue後)。
これは、タスクのlagの分だけ
(つまり、weightあたりの平均CPU時間)が「減る」(lagが正値の場合。負値の場合は増える事にはなるが、いずれにせよ0に近づく事になる)事を意味します*13。
が「減る」という事はその分(
だけ)vlagも減り、見方によってはvlagが実質的に
倍になってしまうとも言えるので、L5232-L5239ではあらかじめその逆数(
)倍しておくことで、enqueueするタスクのlagが実質的に変わらないようにしています*14。
次に、rb-treeに挿入する__enqueue_entity()ですが、以下のようになっていて、
(kernel/sched/fair.c)
849 /* 850 * Enqueue an entity into the rb-tree: 851 */ 852 static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) 853 { 854 avg_vruntime_add(cfs_rq, se); 855 se->min_vruntime = se->vruntime; 856 se->min_slice = se->slice; 857 rb_add_augmented_cached(&se->run_node, &cfs_rq->tasks_timeline, 858 __entity_less, &min_vruntime_cb); 859 }
cfs_rq->avg_vruntime, avg_loadをenqueueするタスク分だけ増やした上で(L854)、rb-treeへの挿入(L857)を行っていますが、大小関係は__entity_less()、つまりplace_entity()で計算したse->deadlineで決まる事がわかります。
3.1.5 pick_next_task()ハンドラ
SCHED_FAIRのpick_next_task()ハンドラは、__pick_next_task_fair()ですが、端的に言えば以下の部分に集約され、
(kernel/sched/fair.c)
8472 do { 8473 se = pick_next_entity(cfs_rq); 8474 set_next_entity(cfs_rq, se); 8475 cfs_rq = group_cfs_rq(se); 8476 } while (cfs_rq);
pick_next_entity()でタスクを選択し、set_next_entity()で必要な設定を行う事になります。
まず、pick_next_entity()ですが、その実体は基本的にpick_eevdf()であり、rb-treeから最もse->deadlineが小さく、且つ、eligibleなタスクを選択する事になります。具体的には
(kernel/sched/fair.c)
878 static struct sched_entity *pick_eevdf(struct cfs_rq *cfs_rq) 879 { 880 struct rb_node *node = cfs_rq->tasks_timeline.rb_root.rb_node; 881 struct sched_entity *se = __pick_first_entity(cfs_rq); 882 struct sched_entity *curr = cfs_rq->curr; 883 struct sched_entity *best = NULL; ... 902 /* Pick the leftmost entity if it's eligible */ 903 if (se && entity_eligible(cfs_rq, se)) { 904 best = se; 905 goto found; 906 }
の通り、left-mostな(se->deadlineが最も小さい)タスクがeligibleであればそのタスクを選択するようになっています。
ただ、前項でも説明した通り、se->deadlineはenqueue時のをベースに設定されている一方、タスクのenqueue/dequeueに伴い
は増減する事もあり、left-mostな(se->
deadlineが最も小さい)タスクでも必ずしも今のに対してeligibleとはならないため、その場合は(詳細は省きますが)これ以降の処理でrb-treeを走査し、可能な限りse->
deadlineが小さいeligibleなタスクを見つけられるようになっています。
次に、set_next_entity()ですが、
(kernel/sched/fair.c)
5403 static void 5404 set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) 5405 { 5406 clear_buddies(cfs_rq, se); 5407 5408 /* 'current' is not kept within the tree. */ 5409 if (se->on_rq) { 5410 /* 5411 * Any task has to be enqueued before it get to execute on 5412 * a CPU. So account for the time it spent waiting on the 5413 * runqueue. 5414 */ 5415 update_stats_wait_end_fair(cfs_rq, se); 5416 __dequeue_entity(cfs_rq, se); 5417 update_load_avg(cfs_rq, se, UPDATE_TG); ...
統計情報の更新に加え、rb-treeからの削除も行います(L5416)。これが、前述した通り、「実行状態にあるタスクはrb-treeには乗っていない」となる所以です。
3.1.6 TIF_NEED_RESCHEDを立てるタイミング
SCHED_FAIRにおいて、実行中のタスクにTIF_NEED_RESCHEDを立てるタイミングですが、(その1)の「2.2.2 tick」でも触れましたが、tick毎に実行されるupdate_curr()*15が鍵となります。
(kernel/sched/fair.c)
1156 static void update_curr(struct cfs_rq *cfs_rq) 1157 { 1158 struct sched_entity *curr = cfs_rq->curr; 1159 s64 delta_exec; 1160 1161 if (unlikely(!curr)) 1162 return; 1163 1164 delta_exec = update_curr_se(rq_of(cfs_rq), curr); 1165 if (unlikely(delta_exec <= 0)) 1166 return; 1167 1168 curr->vruntime += calc_delta_fair(delta_exec, curr); 1169 update_deadline(cfs_rq, curr); 1170 update_min_vruntime(cfs_rq); 1171 1172 if (entity_is_task(curr)) 1173 update_curr_task(task_of(curr), delta_exec); 1174 1175 account_cfs_rq_runtime(cfs_rq, delta_exec); 1176 }
まず前回のupdate_curr()からの経過時間をdelta_execに保存し(L1164)、weightを加味した上でその分だけse->vruntimeを増やし(L1168)、update_deadline()を実行します。
(kernel/sched/fair.c)
978 static void update_deadline(struct cfs_rq *cfs_rq, struct sched_entity *se) 979 { 980 if ((s64)(se->vruntime - se->deadline) < 0) 981 return; 982 ... 990 /* 991 * EEVDF: vd_i = ve_i + r_i / w_i 992 */ 993 se->deadline = se->vruntime + calc_delta_fair(se->slice, se); 994 995 /* 996 * The task has consumed its request, reschedule. 997 */ 998 if (cfs_rq->nr_running > 1) { 999 resched_curr(rq_of(cfs_rq)); 1000 clear_buddies(cfs_rq, se); 1001 } 1002 }
update_deadline()では、se->vruntimeがse->deadlineを超えた場合に(L980)、TIF_NEED_RESCHEDを立てる(L999)ので、それぞれの計算方法を考えると、se->slice(前述の通り固定値)だけCPU時間が経過するとTIF_NEED_RESCHEDフラグが立てられる事がわかります。
最後に
本稿では、デフォルトのスケジューリングクラスであるEEVDFの考え方を解説しつつ、「どのタスクをどの程度実行するか」がどのように実装されているかを解説しました。
想定より内容が膨らんでしまったため、RTおよびDL(DeadLine)スケジューリングクラスについては、次回の記事で解説したいと思います。
*1:むしろその解説が殆どです。
*2:ドキュメントが追加されたのは最近のため、ここだけ最新のkernel documentへのリンクとなっています。
*3:latency niceと呼ばれる試みもあったようです。
*4:ここでは、タスク毎の値に添え字としてを付けています。
*5:shareとも呼ばれますが、本稿ではあまり使いません。
*6:当然、実時間の経過に伴い増加するので、とでも書くべき物ですが、vruntimeに限らず時間経過により変化する物でも、本稿では説明をシンプルにするため
部分は省略します。
*7:具体的には750usをベース値として、CPU数に応じて計算されます。
*8:コンテキストスイッチにかかる時間も無視しています。
*9:のまま計算すると積算によりオーバーフローしてしまうため、このような工夫が施されています。
*10:(その1)でも触れたとおり、cfs_rqはCPU毎のrq構造体に、sched_entityはタスク毎のtask_struct構造体に含まれています。
*12:これを念頭に置くと、EEVDFの実装本体であるfair.cが大分読みやすくなります。
*13:dequeueの際は逆にlagの分だけ「増える」ことになります。
*14:とはいえ、dequeue時と現時点でそれ以外のタスクが同じである保証がなく、無関係のタスクが優遇or冷遇する事にもつながるため、enqueue時にlagをどうすべきか、という点について正解はなく、今のLinuxの実装上こうなっている、というだけです。
*15:それ以外のタイミングでも実行されますが、大事なのはtickのタイミングで必ず実行される、という事です。