「Linuxカーネル2.6解読室」(以降、旧版)出版後、Linuxには多くの機能が追加され、エンタープライズ領域をはじめとする様々な場所で使われるようになりました。
それに伴いコードが肥大かつ複雑化し、多くのエンジニアにとって解読不能なブラックボックスとなっています。
世界中のトップエンジニア達の傑作であるLinuxカーネルにメスを入れ、ブラックボックスをこじ開けて、時に好奇心の赴くままにカーネルの世界を解読する「新Linuxカーネル解読室」プロジェクト。
この「タスクスケジューラ」の記事(いくつかの記事に分ける予定です)では、カーネルv6.8におけるタスクスケジューラの仕組みや実装について解説したいと思います。
執筆者 : 西村 大助
※ 「新Linuxカーネル解読室」連載記事一覧はこちら
1. 概要
本章では、タスクスケジューラに関する基本的な概念や全体像について説明したいと思います。
1.1 タスクスケジューラとは
先日公開したプロセスディスパッチャの記事(前編・後編)では、タスクの切り替え(コンテキストスイッチ)処理について解説しました。つまり、既にどのCPUでどのタスクに切り替えるかが決まった後の、切り替え処理に焦点を当てて解説したわけです。
本稿から数記事に分けて、そこに至るまでの、どういったタイミングでどのタスクに切り替えるのかや、どのCPUでタスクを動作させるのか、といった事を判断するロジックについて解説したいとおもいます。ここでは、そのロジックの事を「タスクスケジューラ」と呼ぶこととします。
Linuxのタスクスケジューラでは、CPU毎にランキューと呼ばれる、【実行可能状態】のタスクの一覧を保持するデータ構造*1を持っていて、タスクを実行するには必ずどこかのCPU(1つだけ)のランキューにenqueueする必要があります*2。
また、Linuxのタスクスケジューラでは、タスクの状態として、【待機状態】【実行可能状態】【実行状態】の大きく3つの状態が存在し、task_struct構造体の__stateメンバの値で管理しています。
このタスクの状態遷移、及び、遷移に伴い実行されるタスクスケジューラ関連の主要な関数は以下の図のようになっています(TASK_***はそれぞれの状態における、task_struct構造体の__stateメンバの値です)。
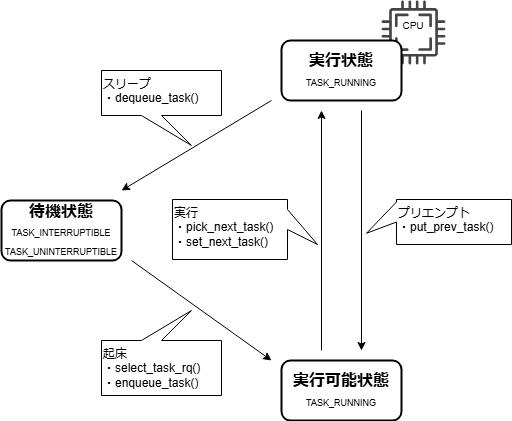
これがタスクスケジューラの骨格であり、この状態遷移が各CPUで独立して行われています。
まず、【待機状態】⇒【実行可能状態】の状態遷移について説明します。
【待機状態】ですが、これはデバイスの処理待ちやロックの解放待ちなど、何らか処理の完了を待っている(他に処理を行う事ができずスリープしている)状態です*3。
その何らかの処理が完了するなどしたら当該タスクは起床されますが、その際、select_task_rq()で当該タスクを実行するCPUを選択し、enqueue_task()でそのCPUのランキューにenqueueする事で、【実行可能状態】(実行されるのを待っている状態)となります。
【待機状態】⇒【実行可能状態】以外の状態遷移を行い、タスクスケジューラの中心となっているのが__schedule()です。
__schedule()の主な役割は、次に実行するタスクを選択し、実行中(__schedule()を実行した)タスクから、その選択したタスクへコンテキストスイッチを行うことですが、少し詳しく見てみましょう。
6607 static void __sched notrace __schedule(unsigned int sched_mode) 6608 { ... 6657 prev_state = READ_ONCE(prev->__state); ① 6658 if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) { 6659 if (signal_pending_state(prev_state, prev)) { 6660 WRITE_ONCE(prev->__state, TASK_RUNNING); 6661 } else { ... 6681 deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK); ② ... 6687 } 6688 switch_count = &prev->nvcsw; 6689 } 6690 6691 next = pick_next_task(rq, prev, &rf); ③ ... 6698 if (likely(prev != next)) { … 6726 /* Also unlocks the rq: */ 6727 rq = context_switch(rq, prev, next, &rf); ④ ...
【実行状態】にあるタスクにより__schedule()が実行される契機はいくつかありますが(後述します)、タスク自身がなんらかの処理の完了を待ち合わせるために自らスリープする場合などは既に【待機状態】(prev_stateが0以外)となっていて(①)dequeueされます(②)が、タスクがタイムスライスを使い切るといった理由によりプリエンプションされる(実行権を奪われる)場合(prev_stateが0)にはdequeueされません。
いずれにしても、次に実行するタスク(next)を選択するためにpick_next_task()が呼ばれますが(③)、その延長で、元のタスク(prev)はput_prev_task()により【実行可能状態】に戻され*4、set_next_task()(相当の処理により)nextが【実行状態】となります*5。
その後、先日の記事で解説したコンテキストスイッチが行われます(④)。
1.2 スケジューリングクラス
1.2.1 概要
Linuxでは複数のスケジューリングクラスが定義されています。
スケジューリングクラス毎に対応するsched_class構造体が定義されていて(後述します)、タスクがどのスケジューリングクラスに属しているかは、task_struct構造体のsched_classメンバにより管理され、タスクスケジューラが当該タスクをどのように扱うかが変わってきます。
カーネルv6.8では*6、IDLE, FAIR, RT, DEADLINE, STOPの5つのスケジューリングクラスが定義されてて、詳細は後述しますが、IDLE<FAIR<RT<DEADLINE<STOPの順番に優先度も設定されています。また、STOP とIDLEは特殊なスケジューリングクラスであり、通常のタスクに割り当てられるスケジューリングクラスはFAIR(EEVDF:Earliest Eligible Virtual Deadline First)*7, RT(RealTime), DL(DeadLine)の3つで、以下のような特徴があります。
- FAIR
- デフォルトのスケジューリングクラス。
- 割り当てられるCPU時間がタスク間で公平(nice値による調整有)となるように制御する。
- RT
- FIFOとRRの2種類が存在する。
- FIFO: 明示的にCPUを明け渡さない限り、当該タスクがCPUを使用し続ける。
- RR: 一定時間毎にタスクをround-robinで切り替える。
- DL
- 3つのパラメータ(period, deadline, runtime)でタスクのスケジューリングを制御する。
- 具体的には、一定時間(period)内のdeadlineまでに、runtimeだけのCPU時間が割り当てられるように制御する。
1.2.2 ユーザAPIとの関係
タスクのスケジューリングクラスは、chrt(1)コマンドやsched_setscheduler(2)/sched_setattr(2)システムコールで変更する事ができます。
これらのAPIで指定するpolicy(SCHED_*)とカーネル内のスケジューリングクラスの対応は以下のようになっています*8。
| API policy | スケジューリングクラス |
|---|---|
| SCHED_OTHER, SCHED_BATCH, SCHED_IDLE | FAIR |
| SCHED_FIFO, SCHED_RR | RT |
| SCHED_DEADLINE | DEADLINE |
1.2.3 スケジューラコアとスケジューリングクラス
タスクスケジューラは、(主に)kernel/sched/core.cで実装されるコア部分と、スケジューリングクラス固有の部分(例えばFAIRの場合だとkernel/sched/fair.c)に分けて実装されています。
多少例外はあるものの基本的な構造としては、スケジューリングクラス固有の処理が必要になった際に、sched_class構造体のハンドラ(説明の都合上、クラスハンドラと呼称します)を呼び出す事で連携しています。
クラスハンドラの呼び出し方には大きく2つの方法があります。
1つめは、スケジューリングクラス毎のクラスハンドラを(前述の優先度順に)呼び出していく方法です。例えば、次に実行すべきタスクを選択する__pick_next_task()を抜粋すると以下のように、各スケジューリングクラスのpick_next_task()ハンドラを呼びだしていって最初に見つかったものを返すようになっています。
(kernel/sched/core.c)
6052 for_each_class(class) { 6053 p = class->pick_next_task(rq); 6054 if (p) 6055 return p; 6056 }
もう1つの方法は、タスクのスケジューリングクラスのクラスハンドラを呼びだす方法です。例えば、タスクをランキューにenqueueするenqueue_task()では、当該タスクのスケジューリングクラスのenqueue_task()ハンドラを呼びだします。
(kernel/sched/core.c)
2118 p->sched_class->enqueue_task(rq, p, flags);
クラスハンドラの種類や、スケジューラコアからどういったタイミングで呼び出されるのか、その役割については、必要に応じて都度解説していきます。
1.3 データ構造
1.3.1 sched_class構造体
前述の通り、スケジューリングクラス毎にsched_class構造体が定義されていますが、
これには、DEFINE_SCHED_CLASS()マクロが使用されます。
(kernel/sched/sched.h)
2335 /* 2336 * Helper to define a sched_class instance; each one is placed in a separate 2337 * section which is ordered by the linker script: 2338 * 2339 * include/asm-generic/vmlinux.lds.h 2340 * 2341 * *CAREFUL* they are laid out in *REVERSE* order!!! 2342 * 2343 * Also enforce alignment on the instance, not the type, to guarantee layout. 2344 */ 2345 #define DEFINE_SCHED_CLASS(name) \ 2346 const struct sched_class name##_sched_class \ 2347 __aligned(__alignof__(struct sched_class)) \ 2348 __section("__" #name "_sched_class")
例えば、FAIRスケジューリングクラスのsched_class構造体は以下のように定義されています。
(kernel/sched/fair.c)
13118 /* 13119 * All the scheduling class methods: 13120 */ 13121 DEFINE_SCHED_CLASS(fair) = { 13122 13123 .enqueue_task = enqueue_task_fair, 13124 .dequeue_task = dequeue_task_fair, 13125 .yield_task = yield_task_fair, 13126 .yield_to_task = yield_to_task_fair, ...
上記の例からもわかる通り、sched_class構造体には色々なクラスハンドラ(スケジューラコアから呼び出されます)が定義されています。
主要なクラスハンドラとその役割は以下の通りです(スケジューリングクラスにより実装されていないクラスハンドラもあります)。
| クラス ハンドラ | 役割 |
|---|---|
enqueue_task() |
タスクをランキューにenqueueする。 |
dequeue_task() |
タスクをランキューからdequeueする。 |
pick_next_task() |
後述する、put_prev_task() と pick_task()、 set_next_task() の処理をまとめて行う。 |
put_prev_task() |
タスクを【実行状態】から遷移させる際に呼び出される。 |
set_next_task() |
タスクを【実行状態】へと遷移させる際に呼び出される。 |
pick_task() |
次に実行すべきタスクを選択する。 |
select_task_rq() |
タスクを起床する際、どのCPUで動作させるかを選択する。 |
task_tick() |
tick毎に呼び出され、タスクの実行時間を更新するなどする。 |
また、DEFINE_SCHED_CLASS()マクロの定義からもわかる通り、各スケジューリングクラスのsched_class構造体は、以下のように定義されているセクションに配置されます。
(include/asm-generic/vmlinux.lds.h)
122 /* 123 * The order of the sched class addresses are important, as they are 124 * used to determine the order of the priority of each sched class in 125 * relation to each other. 126 */ 127 #define SCHED_DATA \ 128 STRUCT_ALIGN(); \ 129 __sched_class_highest = .; \ 130 *(__stop_sched_class) \ 131 *(__dl_sched_class) \ 132 *(__rt_sched_class) \ 133 *(__fair_sched_class) \ 134 *(__idle_sched_class) \ 135 __sched_class_lowest = .;
これにより、for_each_class()といったマクロを使って、スケジューリングクラスの優先度順(STOPが最も高くIDLEが最も低い)に処理を行う、といった事が可能になっています。
1.3.2 rq構造体
CPU毎に定義されているランキューを表す構造体です。
(kernel/sched/core.c)
119 DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
メンバが多くここでは全ては説明しませんが、この構造体に直接タスクがqueueingされるわけではなく、rq構造体はスケジューリングクラス毎のランキューをメンバとして持っており、タスクは自身のスケジューリングクラスに応じたランキューにqueueingされます。
(kernel/sched/sched.h)
1015 struct cfs_rq cfs; 1016 struct rt_rq rt; 1017 struct dl_rq dl;
1.3.3 task_struct構造体
既に何度か登場している、タスク毎に定義されている構造体ですが、前述のrq構造体同様、task_struct構造体にもスケジューリングクラスに応じた「実体(entity)」となるメンバが存在します。
(include/linux/sched.h)
797 struct sched_entity se; 798 struct sched_rt_entity rt; 799 struct sched_dl_entity dl;
前述の、スケジューリングクラス毎のランキューは、厳密に言えば、タスクそのものを管理するのではなく、この「実体(entity)」の方を管理する作りになっています。
2. __schedule()が実行されるタイミング
本章では、__schedule()が実行される契機やその流れを解説したいと思います。
2.1 タスク自らCPUを明け渡す場合
タスク自身の処理により、__schedule()が実行されるケースとして以下のような物が上げられます。
- cond_resched()
- 何らかの待ち合わせ処理
cond_resched()が使われるよくあるパターンとしては、(カーネルスレッドに多いのですが)kernel内のループ処理でループの度に呼び出して、当該処理がCPUを使い続けないようにするために使われたり、排他制御の出口で呼ばれたりもします*9。
もう1つの待ち合わせ処理の詳細については、別途まとめたいと思いますが、待ち合わせる側の基本的な流れとしては、
- 待ち合わせの準備(例:待ち行列に追加)をする。
- タスクの状態をTASK_INTERRUPTIBLE(or TASK_UNINTERRUPTIBLE)にする。
- __schedule()を呼ぶ。
となっています。
いずれにしても、タスク自身がその処理の中で__schedule()を呼び、タスクスケジューラが何かするわけでもないので、ここではこれ以上触れません。
2.2 タスクスケジューラによりCPUを明け渡す場合(プリエンプション)
2.2.1 TIF_NEED_RESCHED
前節ではタスク自身が__schedule()を呼んでCPUを明け渡す場合について触れましたが、本節ではタスクスケジューラの処理により__schedule()を呼ばされる(プリエンプションされる)場合について説明したいと思います。
ここで重要となるのは、TIF_NEED_RESCHEDというフラグです。
どういうタイミングでこのフラグが立てられるかは次節以降でいくつか例を挙げますが、まず、このフラグが立っていた場合に、なぜ__schedule()が呼ばれる事になるのかを説明します*10。
その仕組みはそれ程複雑ではなく、ユーザプロセスがシステムコールや例外処理等のためカーネル内で処理を行った後、ユーザ空間に戻る際に呼ばれるexit_to_user_mode_prepare()でこのフラグが立っていると、exit_to_user_mode_loop()を呼びだしますが(①)、
(include/linux/entry-common.h)
65 #define EXIT_TO_USER_MODE_WORK \ 66 (_TIF_SIGPENDING | _TIF_NOTIFY_RESUME | _TIF_UPROBE | \ 67 _TIF_NEED_RESCHED | _TIF_PATCH_PENDING | _TIF_NOTIFY_SIGNAL | \ 68 ARCH_EXIT_TO_USER_MODE_WORK) ... 307 /** 308 * exit_to_user_mode_prepare - call exit_to_user_mode_loop() if required 309 * @regs: Pointer to pt_regs on entry stack 310 * 311 * 1) check that interrupts are disabled 312 * 2) call tick_nohz_user_enter_prepare() 313 * 3) call exit_to_user_mode_loop() if any flags from 314 * EXIT_TO_USER_MODE_WORK are set 315 * 4) check that interrupts are still disabled 316 */ 317 static __always_inline void exit_to_user_mode_prepare(struct pt_regs *regs) 318 { … 326 ti_work = read_thread_flags(); 327 if (unlikely(ti_work & EXIT_TO_USER_MODE_WORK)) 328 ti_work = exit_to_user_mode_loop(regs, ti_work); ①
この、exit_to_user_mode_loop()のなかで__schedule()が呼ばれ(②)、強制的にCPUを明け渡す、という流れになります。
(kernel/entry/common.c)
84 __always_inline unsigned long exit_to_user_mode_loop(struct pt_regs *regs, 85 unsigned long ti_work) 86 { 87 /* 88 * Before returning to user space ensure that all pending work 89 * items have been completed. 90 */ 91 while (ti_work & EXIT_TO_USER_MODE_WORK) { 92 93 local_irq_enable_exit_to_user(ti_work); 94 95 if (ti_work & _TIF_NEED_RESCHED) 96 schedule(); ②
2.2.2 tick
tickとはCONFIG_HZの周波数で割り込みを発生させ、定期的に様々な処理(例:jiffiesの更新)を行うための機能です*11。
tickの処理で呼ばれる関数の1つにscheduler_tick()があり、そこから、実行中のタスクのスケジューリングクラスのtask_tick()ハンドラが呼ばれます*12。
(kernel/sched/core.c)
5652 /* 5653 * This function gets called by the timer code, with HZ frequency. 5654 * We call it with interrupts disabled. 5655 */ 5656 void scheduler_tick(void) 5657 { 5658 int cpu = smp_processor_id(); 5659 struct rq *rq = cpu_rq(cpu); 5660 struct task_struct *curr = rq->curr; ... 5675 curr->sched_class->task_tick(rq, curr, 0);
スケジューリングクラスがFAIRだった場合、task_tick_fair() -> entity_tick() -> update_curr() -> update_deadline() の以下の処理により、
(kernel/sched/fair.c)
995 /* 996 * The task has consumed its request, reschedule. 997 */ 998 if (cfs_rq->nr_running > 1) { ① 999 resched_curr(rq_of(cfs_rq)); 1000 clear_buddies(cfs_rq, se); 1001 }
実行中のタスクが与えられたタイムスライスを使い切っていて(そうでなければこの処理まで来ない)、且つ、他にも実行可能なタスクが存在する場合(①)、resched_curr()によりTIF_NEED_RESCHEDフラグが立てられます(②)。
(kernel/sched/core.c)
1041 void resched_curr(struct rq *rq) 1042 { 1043 struct task_struct *curr = rq->curr; 1044 int cpu; ... 1053 if (cpu == smp_processor_id()) { 1054 set_tsk_need_resched(curr); ② 1055 set_preempt_need_resched(); 1056 return; 1057 }
スケジューリングクラスがRTだった場合、task_tick()ハンドラはtask_tick_rt()となりますが、
(kernel/sched/rt.c)
2588 static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued) 2589 { 2590 struct sched_rt_entity *rt_se = &p->rt; ... 2597 /* 2598 * RR tasks need a special form of timeslice management. 2599 * FIFO tasks have no timeslices. 2600 */ 2601 if (p->policy != SCHED_RR) ③ 2602 return; 2603 2604 if (--p->rt.time_slice) ④ 2605 return; 2606 2607 p->rt.time_slice = sched_rr_timeslice; 2608 2609 /* 2610 * Requeue to the end of queue if we (and all of our ancestors) are not 2611 * the only element on the queue 2612 */ 2613 for_each_sched_rt_entity(rt_se) { 2614 if (rt_se->run_list.prev != rt_se->run_list.next) { 2615 requeue_task_rt(rq, p, 0); 2616 resched_curr(rq); ⑤ 2617 return; 2618 } 2619 } 2620 }
- SCHED_FIFOだと何もしない(③)。
- タイムスライスを1減らして、まだ残っている場合も何もしない(④)。
ため、SCHED_RRのタスクがタイムスライスを使い切った場合に限りresched_curr()が呼ばれる(TIF_NEED_RESCHEDが立てられる)事になります(⑤)。
2.2.3 高優先度タスク
タスクがプリエンプションされるもう1つのケースとして、実行中のタスクより高優先度のタスクが実行可能になる(起床される)ケースも見てみましょう。
スケジューリングクラスには前述の通り、[FAIR] < [RT] < [DEADLINE] という優先度が設定されているので、FAIRのタスク実行中にRTのタスクが起床したとします。タスクの起床にはttwu_do_activate()が使われますが、
(kernel/sched/core.c)
2239 void wakeup_preempt(struct rq *rq, struct task_struct *p, int flags) 2240 { 2241 if (p->sched_class == rq->curr->sched_class) 2242 rq->curr->sched_class->wakeup_preempt(rq, p, flags); 2243 else if (sched_class_above(p->sched_class, rq->curr->sched_class)) ③ 2244 resched_curr(rq); ④ ... 3774 static void 3775 ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags, 3776 struct rq_flags *rf) 3777 { ... 3795 activate_task(rq, p, en_flags); ① 3796 wakeup_preempt(rq, p, wake_flags); ②
タスクをenqueue(①)後に実行されるwakeup_preempt()(②)でスケジューリングクラスの優先度の比較が行われ(③)、FAIRよりRTの方が優先度が高いため実行中のタスクがプリエンプションされる事になります(④)。
最後に
本稿ではタスクスケジューラの基本的な考え方と、__schedule()が実行される契機について解説しました。
次回以降の記事では、本稿では解説しきれなった実行するタスクの選択ロジックやタスクを動作させるCPUの選択ロジックについて解説できればと思っています。
*2:もちろん、別のCPUに移る事もできます。
*3:ちなみに、fork(2)などによって生成された直後のタスクもこの状態です。
*4:コードパス上は【実行状態】⇒【待機状態】でもput_prev_task()は呼ばれますが、タスクがdequeueされていると多くの処理がスキップされるため、先程の図の中には書いていません。
*5:説明の都合上、これらの関数で【実行可能状態】⇔【実行状態】の遷移が行われるように書きましたが、厳密には、「状態遷移に伴いこれらの関数が実行される」くらいに考えてください。
*6:v6.12では新たなスケジューリングクラスとしてEXT(Extensible scheduler)が追加されました。
*7:EEVDFになったのはv6.6からで、それまではCFS(CompleteFairScheduler)と呼ばれるアルゴリズムが使われていました。骨格的な部分ではあまり変わっておらず、ソース上でも"CFS(cfs)"という表現が多く残っています。
*8:紛らわしいですが、SCHED_IDLE policyがIDLEスケジューリングクラスになるわけでははありません。
*9:voluntary preemptionとも呼ばれます。
*10:前述のcond_resched()でもこのフラグはチェックされるので、プリエンプション専用のフラグというわけではありません。
*11:tickの仕組みについては別記事にて解説したいと思いますが、ここでは「定期的に処理が行われるもの」と考えてください。
*12:このクラスハンドラはHRTICKというスケジューラの機能(/sys/kernel/debug/sched/features参照)を有効にすれば別のパスでも呼ばれますが、デフォルトで無効な機能なため、ここでは触れません。