「Linuxカーネル2.6解読室」(以降、旧版)出版後、Linuxには多くの機能が追加され、エンタープライズ領域をはじめとする様々な場所で使われるようになりました。 それに伴いコードが肥大かつ複雑化し、多くのエンジニアにとって解読不能なブラックボックスとなっています。 世界中のトップエンジニア達の傑作であるLinuxカーネルにメスを入れ、ブラックボックスをこじ開けて、時に好奇心の赴くままにカーネルの世界を解読する「新Linuxカーネル解読室」プロジェクト。
本稿では、ネットワーク機能におけるパケットの受信処理についてカーネルv6.8のコードをベースに解説します。
執筆者 : 須田 哲志、稲葉 貴昭
※「新Linuxカーネル解読室」連載記事一覧はこちら
はじめに
前回はデバイス(NIC)がパケットを受信し、パケットがIPレイヤーに渡るまでの過程を見ました。
今回は前回の3章で取り扱った「ポーリングハンドラ(NAPI)による受信処理」を深堀していきます。
前回の記事に比べるとかなり細かい話が多いですが、ぎっくり腰+腱鞘炎+捻挫の中頑張って書いたのでぜひ読んでいただけると嬉しいです。(涙)
(それほど過酷な労働環境というわけではなくボルダリング等で怪我をしてしまいました...。)
1. 前回のおさらい
最初に前回のおさらいを軽くしたいと思います。 前回はデバイス(NIC)がパケットを受信し、パケットがIPレイヤーに渡るまでの過程(図1における①〜⑥)を見ました。 (前提条件等は前回の記事をご覧ください。)
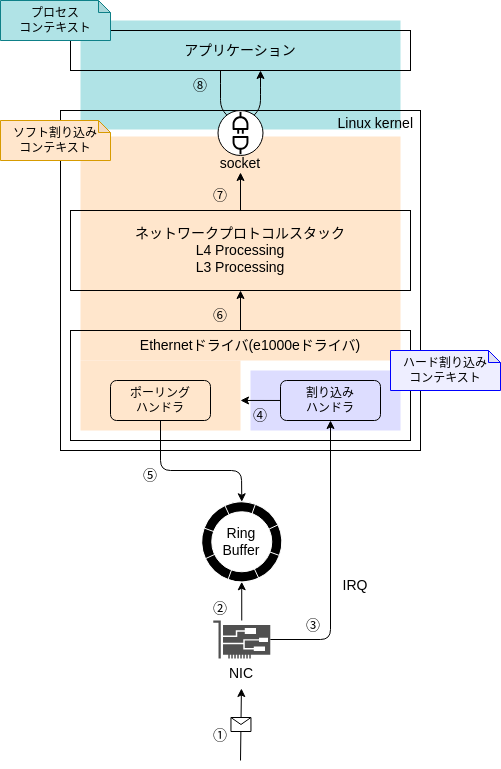
割り込みハンドラはNICからの割り込み要求(IRQ)を検知すると、パケット受信処理のためのお膳立てを行い、ソフト割り込みをキックします。 そして、「ソフト割り込みコンテキスト」ではポーリングハンドラを入口としてパケットの受信処理を開始するのでした。
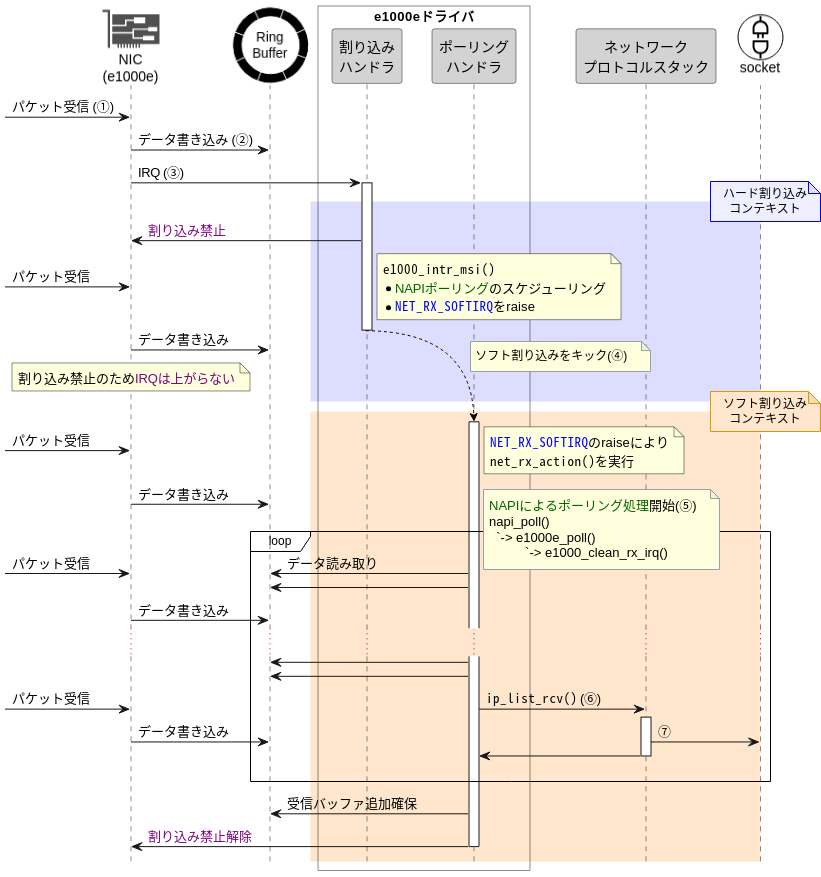
図2中のloop部分で、ポーリングを行い、複数のパケットをまとめて上位ネットワークプロトコルスタック(以降、上位レイヤ)へ配送することを繰り返しています。
これを実装しているのがe1000_clean_rx_irq()関数です。
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static bool e1000_clean_rx_irq(struct e1000_ring *rx_ring, int *work_done, int work_to_do) { ... while (staterr & E1000_RXD_STAT_DD) { struct sk_buff *skb; ... skb = buffer_info->skb; // 筆者コメント: リングバッファのバッファからskbを取り出す(データ読み取り) ... e1000_receive_skb(adapter, netdev, skb, staterr, rx_desc->wb.upper.vlan); // 筆者コメント: skbのリスト作成 or 上位レイヤ処理 next_desc: ... buffer_info = next_buffer; // 筆者コメント: 参照先を次のバッファにセット ... } ... }
上記ソースコードのe1000_receive_skb()関数で複数のパケットをまとめたり、上位レイヤに配送を行っています。
今回はこのe1000_receive_skb()関数を深堀していきます。
2. 上位レイヤへの配送: e1000_receive_skb()関数以降の処理について
2.1 前提知識: EtherTypeとpacket_type構造体
e1000_receive_skb()の解説に入る前にEtherTypeとpacket_type構造体について簡単に説明します。
Ethernetドライバ視点ではIPやARPなど、上位プロトコルの異なるパケットを順次受信することになります。
このとき、パケットごとに異なるプロトコルをどのようにハンドリングしているのでしょうか。
具体的には上位プロトコルと、それに対応したハンドラ(関数)をどのように特定しているのでしょうか。
まず、上位プロトコルの特定についてですが、これはパケットのEthernetヘッダからわかります。
Ethernetヘッダでは、上位プロトコルを示す「EtherType」というフィールドを用意しています。
そして、この「EtherType」の解析結果を、ポーリング時にsk_buff構造体の.protocolに記録します。
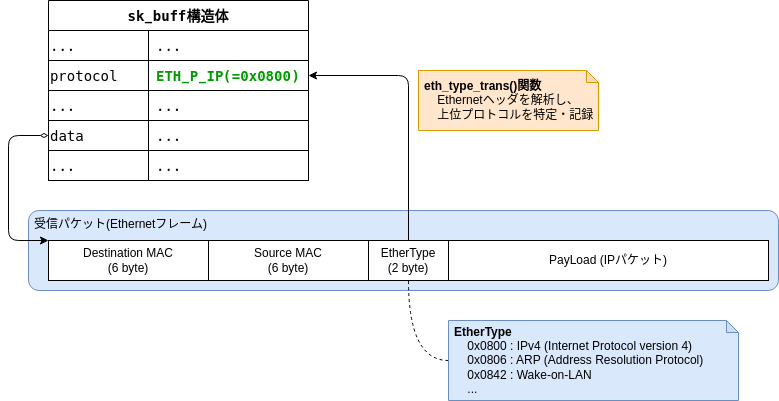
あとは、この「EtherType」(sk_buff構造体の.protocol)とハンドラ(関数)を紐付ける情報があれば、上位レイヤへパケットを配送できます。
この情報を保持しているのが、packet_type構造体です。
Linuxカーネルでは、EthernetTypeごとにpacket_type型のオブジェクトを生成し、ハッシュテーブル等で管理しています。
そして、図4のようにsk_buff構造体の.protocolとpacket_type構造体の.typeと比較することでハンドラ(.funcもしくは.list_func)を特定できます。

図4の例ではip_rcv関数(もしくはip_list_rcv関数)にパケット(sk_buff構造体)を渡せば良いとわかります。
すなわち、EtherTypeの異なる各パケット(sk_buff構造体)をそれぞれ適切なハンドラ(関数)を通して上位レイヤへ渡すためには、
パケット(プロトコル)に適したpacket_type構造体を参照すれば良いということになります。
また、このことから、ある2つのパケットが同じpacket_type構造体を参照しているとき、これら2つのパケットは同じEtherTypeであると言えます。 (すなわち、同じ上位プロトコルであると言えます。)
2.2 概要
それではパケットを上位レイヤへ配送する部分を見ていきましょう。
図4の上位レイヤへのハンドラを呼び出しているのは、e1000_receive_skb()関数の延長にある__netif_receive_skb_list_ptype()関数です。
e1000_receive_skb()関数から図4のpacket_type構造体に登録しているハンドラを呼び出すまでの流れは以下のようになっています。
*1
e1000_receive_skb() ├── eth_type_trans() // 受信パケットのEthernetヘッダを解析しEtherTypeを取得・記録。(図3参照) └── napi_gro_receive() ├── dev_gro_receive() // 結合可能なパケットをマージし、1つの大きなパケットにする。(次回以降の記事で解説予定) └── napi_skb_finish() └── gro_normal_one() // 受信パケット(=sk_buff構造体)をリストにつなぐ。リストが規定の長さ未満であればreturn。 └── gro_normal_list() └── netif_receive_skb_list_internal() └── __netif_receive_skb_list() └── __netif_receive_skb_list_core() // 各種フック関数の受信ハンドラを呼び出す。2.3節で解説。 └── __netif_receive_skb_list_ptype() // packet_type構造体に登録しているハンドラを呼び出す。(図4参照) └── ip_list_rcv() // 上位レイヤの処理
呼び出し関係が非常に深いですが、この間に処理性能向上のために以下の工夫を行っています。
(1) dev_gro_receive()
結合可能なパケットをマージし、1つの大きなパケットにする。
ただし本記事の前提であるUDPの場合、デフォルトではOFFである。
(2) gro_normal_one()
受信パケット列(=sk_buff構造体のリスト)を作成する。
これにより、後続の関数の呼び出しにかかるオーバヘッドを削減する。
(3) __netif_receive_skb_list_core()
同じ上位レイヤに渡せるパケットをサブリストにまとめることで、上位レイヤで時間のかかる処理(次回の記事で解説予定)を効率化するための下準備をする。
(1)についてはGRO(Generic Receive Offload)に関する機能であり、次回以降の記事で解説予定です。
(3)の__netif_receive_skb_list_core()は少々複雑な実装になっているため次節で解説します。
本節では最後に(2)のgro_normal_one()関数について簡単に解説します。
後述する__netif_receive_skb_list_core()関数では、受信パケット列(=sk_buff構造体のリスト)を処理しますが、受信パケットをリストにしているのが、このgro_normal_one()関数です。
gro_normal_one()関数は、処理負荷の削減を目的に複数の受信パケット(=sk_buff構造体)をリストにまとめています。
ここでは、リストが一定の長さ(8パケット分)を超過したタイミングで次の処理(gro_normal_list())を呼び出します。*2*3
このように複数の受信パケットをまとめることで、__netif_receive_skb_list_core()の呼び出し回数の削減効果や次回以降解説する後続処理の効率化といったメリットが得られます。

次節では(3)の__netif_receive_skb_list_core()関数の挙動を追っていきたいと思います。
2.3 __netif_receive_skb_list_core()関数の処理
先述のとおり、__netif_receive_skb_list_core()関数は、gro_normal_one()関数でリストにした受信パケットを
連続した同一EtherType(IPv4やARPなど)のパケットごとにサブリストに分割し、上位レイヤへ渡す準備をします。

実装方針
大まかな実装の流れとしては、受け取ったパケット列(=sk_buff構造体のリスト)のそれぞれに対し、
- 前のパケットと上位プロコトルが同一であれば、パケットをサブリストに繋ぎ変える
- 前のパケットと上位プロトコルが異なれば、サブリストを確定し上位プロトコルのハンドラにサブリストを渡す
(その後、サブリストをリセットしてから現在注目しているパケットをサブリストにつなぐ)
という流れになります。 このとき、前のパケットと同じ上位プロトコルかという判断には「packet_type構造体への参照(ポインタ)」を用います。 (「参照先のpacket_type構造体が同一」=「上位プロトコルが同一」ということを利用しています(図4参照))
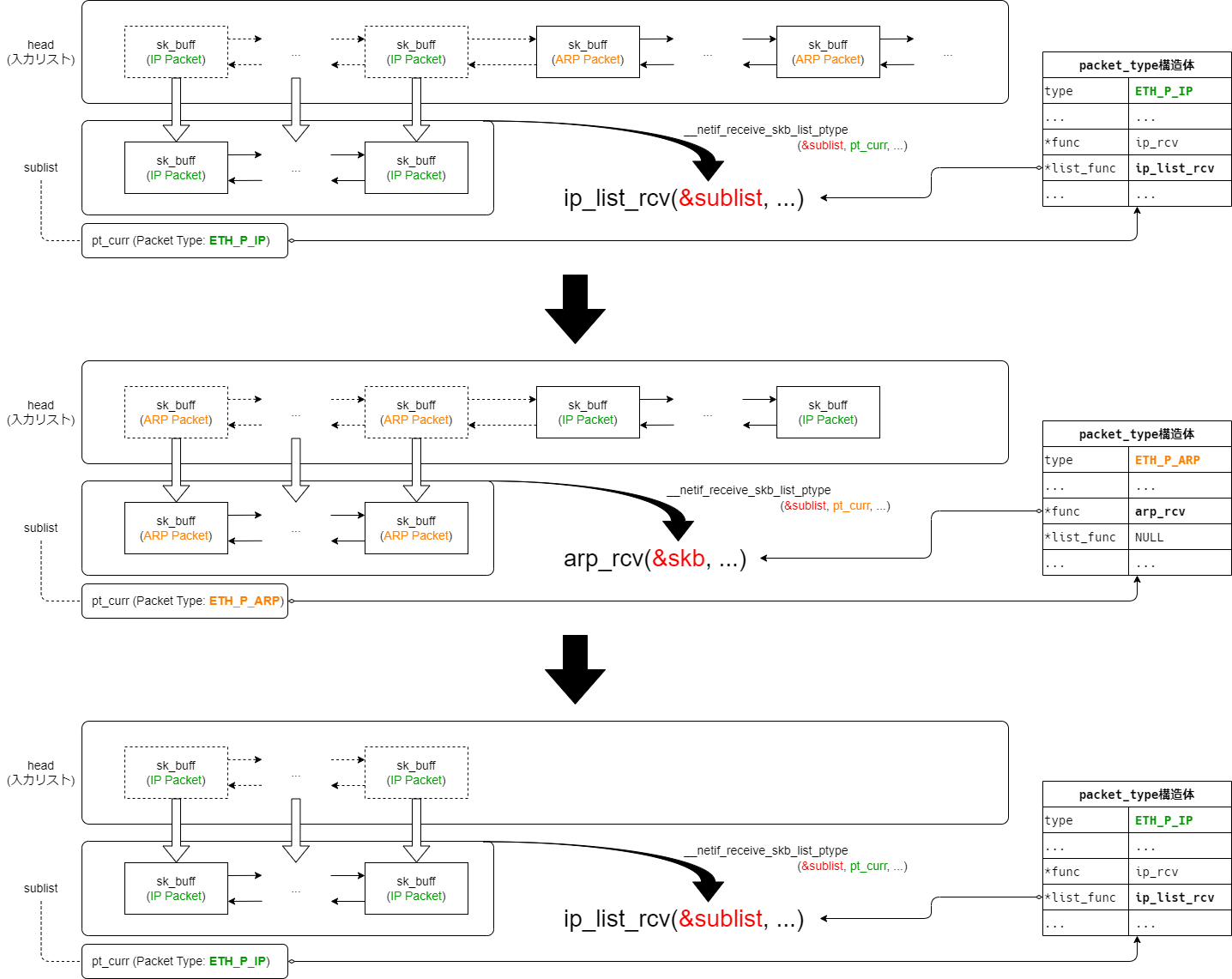
ソースコード解説
それでは実際のソースコードを見てみましょう。
(/net/core/dev.c)
static void __netif_receive_skb_list_core(struct list_head *head, bool pfmemalloc) { ... INIT_LIST_HEAD(&sublist); list_for_each_entry_safe(skb, next, head, list) { // 筆者コメント: skbのリストを走査 struct net_device *orig_dev = skb->dev; struct packet_type *pt_prev = NULL; skb_list_del_init(skb); __netif_receive_skb_core(&skb, pfmemalloc, &pt_prev); // 筆者コメント: パケットタイプ(pt_prev)を取得 if (!pt_prev) continue; if (pt_curr != pt_prev || od_curr != orig_dev) { // 筆者コメント: EtherTypeが変わった場合(pt_curr != pt_prev) /* dispatch old sublist */ __netif_receive_skb_list_ptype(&sublist, pt_curr, od_curr); // 筆者コメント: sublistを上位レイヤへ渡す /* start new sublist */ INIT_LIST_HEAD(&sublist); // 筆者コメント: sublistのリセット pt_curr = pt_prev; od_curr = orig_dev; } list_add_tail(&skb->list, &sublist); // 筆者コメント: sublistにつなぐ(=EtherTypeが同じ場合) } /* dispatch final sublist */ __netif_receive_skb_list_ptype(&sublist, pt_curr, od_curr); }
ここでポイントとなる変数は以下の4つです。
skb
現在着目しているパケットsublist
上位レイヤのハンドラに渡すためのパケット列(これまでサブリストと説明していたもの)。
先述のとおり、ここに繋がるパケットはすべて同一のEtherType値(=上位プロトコル)である。pt_curr
サブリスト内(=sublist)のパケットに対応したpacket_type構造体へのポインタ。
このpt_currの.funcもしくは.list_funcが上位レイヤのハンドラとなっている。pt_prev
現在着目しているパケットに対応したpacket_type構造体へのポインタ。
このpt_prevとpt_currを比較することで、前のパケットと同一のEtherTypeかを判断する。
(厳密には前のパケットと比較しているのではなく、sublistに繋がるパケットと比較している)
受信パケットのリスト(head)を走査し、パケットのEtherTypeが同一である間、パケットを1つずつsublistにつなぎ変えていきます。
sublistのEtherTypeと異なるパケットが出現した段階(pt_curr != pt_prev)でsublistを確定*4し、__netif_receive_skb_list_ptype()関数を通して上位レイヤへパケットを配送します。
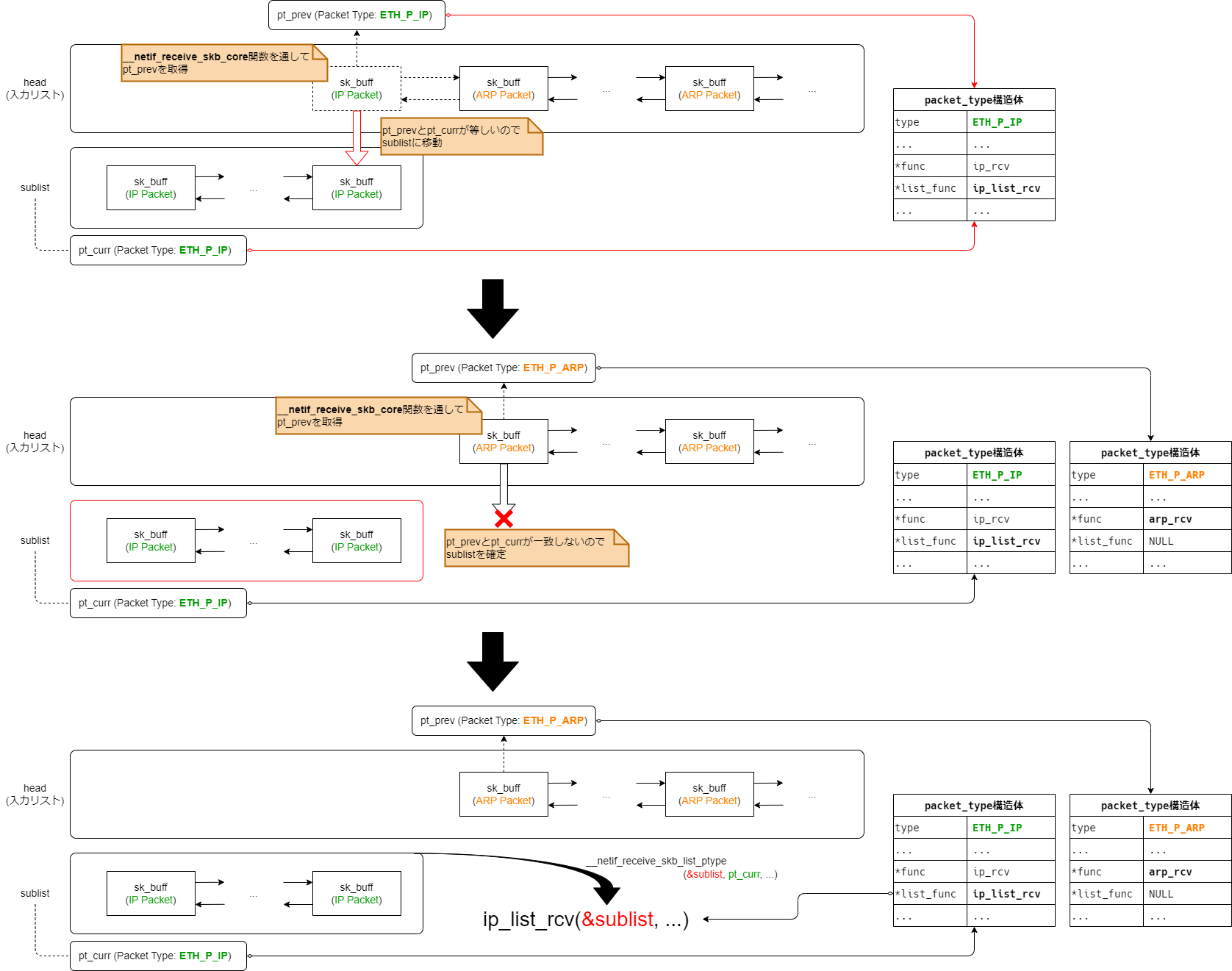
このときpt_prevは__netif_receive_skb_core()関数を経由して取得しています。(図8参照)
それでは、この__netif_receive_skb_core()関数はパケットのpacket_type構造体を取得するための関数なのかというと、そうではありません。
__netif_receive_skb_core()関数には、パケット(sk_buff構造体)を上位レイヤへ配送する前に実施する必要のあるフックポイントを集約しています。
次節では、この__netif_receive_skb_core()関数について簡単に紹介します。
2.4 __netif_receive_skb_core()の処理: フック処理とRAWソケットへの配送
前述のとおり、__netif_receive_skb_core()関数には、パケット(sk_buff構造体)を上位レイヤへ配送する前に実施する必要のあるフックポイントを集約しています。
具体的には以下の機能の受信処理をこの関数から呼び出します。
- Generic XDP
- TC ingress
- netfilter ingress
- Macsec
- MACVLAN
- IPVLAN
- MacVTap
- Teaming
- Bridge
- Bonding
また、socket(AF_PACKET, SOCK_RAW, ETH_P_ALL)のように受信したすべてのパケットを扱うRAWソケットへの配送はここで行います。
3 ポーリングの終了条件
3.1 e1000_clean_rx_irq()関数の終了条件
最後にNAPIによるポーリングの終了条件について簡単に解説します。
ここまで関数を深く辿ってきたのでポーリング部分について簡単におさらいしておくと、NAPIのポーリングはe1000_clean_rx_irq()関数内でおこなわれていることを説明しました。

loop部分がNAPIポーリングによるパケットの受信処理に該当します。
これはe1000_clean_rx_irq()関数において以下のwhileループに該当する部分です。
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static bool e1000_clean_rx_irq(struct e1000_ring *rx_ring, int *work_done, int work_to_do) { ... while (staterr & E1000_RXD_STAT_DD) { struct sk_buff *skb; if (*work_done >= work_to_do) break; (*work_done)++; ... // 筆者コメント: パケット受信処理 } ... }
つまり、このwhileループの終了/脱出条件がそのままNAPIポーリングの終了条件となりそうですね。
ソースコードからこのwhileループを抜ける条件は、以下の2つのどちらかを満たしたときとわかります。
staterr & E1000_RXD_STAT_DDが0となるとき*work_done >= work_to_doを満たすとき
条件 その1: staterr & E1000_RXD_STAT_DDが0となるとき
staterrはNICのレジスタの値を示しており、E1000_RXD_STAT_DDは受信データのバッファへの書き込みが完了していることを意味するフラグになっています。
whileループの継続条件であるstaterr & E1000_RXD_STAT_DDは受信データをリングバッファから取り出せる状態であることを意味しています。
つまり、リングバッファに受信データがない場合、staterr & E1000_RXD_STAT_DDが0となりポーリングを終了します。
条件 その2: *work_done >= work_to_doを満たすとき
work_doneはソースコードでインクリメントしている((*work_done)++;)ことからもわかるとおり、ポーリングにより受信処理した(=上位レイヤに配送した)パケット数を示しています。
*5
すなわち、*work_done >= work_to_doはポーリングによる受信パケット数が規定数(work_to_do)を上回った場合、whileループをbreakし、ポーリングを終了します。
この規定数となるwork_to_doは関数の引数として渡されており、何の値が入っているかは関数をいくつか遡る必要がありますが、結論としては64(NAPI_POLL_WEIGHT)という固定値がセットされます。
(napi_struct構造体の.weightの値が入ります。)
つまり、ポーリング処理で1度に受信できるパケット数は最大で64パケットとなります。
3.2 ポーリングの再スケジュール
前節で「ポーリング処理で1度に受信できるパケット数は最大で64パケット」と説明しましたが、NICが64パケット以上受信していた場合、その後の処理はどうなるのでしょうか。
前節のとおり、NICが64パケット以上受信していた場合でも、e1000_clean_rx_irq()関数自体はwhileループを抜けて終了します。
ところが、以下のように関数の呼び出し元を辿っていくと、実は__napi_poll()関数/napi_poll()関数で「未処理の受信パケットあり」と判定し、再度NAPIポーリングの再スケジューリングを行います。
net_rx_action() // 4. NAPIポーリングの再スケジュールとNET_RX_SOFTIRQのraise
└── napi_poll() // 3. NAPIポーリングの再スケジュールを要求
└── __napi_poll() // 2. 未処理の受信パケットありと判定
└── n->poll: e1000e_poll()
└── adapter->clean_rx: e1000_clean_rx_irq() // 1. 64パケット受信
このように、NICが64パケット以上受信していた場合でも、再度ポーリングによる受信処理を実行するようになっています。 それでは、NICがパケットを受信し続けていた場合、永遠とポーリングによる受信処理を繰り返すのでしょうか? もちろんそんなことなく、ある条件を満すと以降のポーリングによる受信処理をksoftirqdに移譲し、 CPUを解放することでパケットの受信処理がCPUを占有しないようにしています。 なお、ksoftirqdはスケジューラからCPUが割り当てられたタイミングで受信処理を再開します。
本章の最後では、ポーリングの再スケジューリングを含め、ポーリングまわりをもう少し俯瞰してみます。
今回のパケット受信処理に関する連載では、NICが1枚だけ搭載されていることを前提としていますが、今だけ複数枚のNICが搭載されている状況を考えます。
すると、図10*6に示すとおり、ポーリングによる受信処理は大きく3つのループ構造で実装されていることがわかります。
(図10中のloop*に付随する条件はループの継続条件です。各loop*に複数条件がありますが、すべてAND条件です。)

今回の記事で解説していた処理は主に図10中のloop3に該当します。
処理のシーケンスとしてはloop1→loop2→loop3と順次ネストしており、内側のループに行くほどパケットの受信処理に対する制約が厳しくなっていることがわかります。*7
これは、特定の処理に時間を割き過ぎないように「ソフト割り込みコンテキスト」(loop1)、「NET_RX_SOFTIRQ」(loop2)、「Ethernetドライバ」(loop3)の各レイヤーごとに処理時間や受信パケット数に制約を設けていると言えます。
*8
そして、loop1のループ継続条件を満たせなくなった時点で、ksoftirqdに処理を移譲します。*9
なお、loop1のループ継続条件はソフト割り込み処理全般の処理に対する制約であるため、当該ループ継続条件は「NET_RX_SOFTIRQ」に対してのみ適用するものではないことに注意してください。
つまり、NICがパケットを受信し続けたとしても、いずれはloop1のループ継続条件を満たせなくなり、ksoftirqdに残りの処理を移譲することになります。
最後にポーリングの再スケジュールの流れを図10と照らし合わせてみてみたいと思います。

各NICで発生したポーリングの再スケジューリング(loop3)は即座に実行するのではなく、loop1まで処理が戻ってから実行していることがわかります。
次回予告
前回と今回の2回でEthernetドライバにおけるパケット受信処理を見てきました。 次回からはIPレイヤーからsocketインターフェースまでの流れを追っていきたいと思います。
*1:「gro」という単語がいくつか見られますが、これは「Generic Receive Offload」の略で、次回以降の記事で解説する予定です。ただし、UDPではユーザが明示的に指定しない限り基本的に使われません。(Ethernetレイヤーにおいては重要な機能なので言及しています。)
*2:このリストの長さはプログラム内のgro_normal_batchという変数で決定しています。プログラムでは初期値が8となっているため、デフォルトで8パケットになります。実はこのgro_normal_batchはカーネルパラメータになっているおり、/proc/sys/net/core/gro_normal_batchから確認/変更ができます。
*3:ポーリングの結果、受信パケット数がgro_normal_batch未満であった場合、本記事とは別の経路で上位レイヤに配送します。具体的には、gro_normal_oneからそのままe1000e_pollまでreturnしていき、e1000_clean_rx_irq(=adaptor->clean_rx)の後に呼び出すnapi_complete_doneで上位レイヤに配送します。
*4:実際には「受信したデバイスが同一か」も判断基準になっていますが、ここでは話を簡単にするためにすべてのパケットが同じデバイスから受信しているものとします。
*5:work_doneポインタ変数を関数の引数として渡しますが、work_doneポインタの指す先は呼び出し元であるe1000e_poll()関数で0クリアしています。
*6:図10は複数のNICが搭載されているだけでなく、CPUのコアも1つだけという特殊な状況です。説明のために極端な状況を想定しました。通常はNICごとに割り込み先のCPUが変わる可能性が高いため、図10のように1つのコアが複数のNICの世話をするという状況はレアケースと思われます。図10の状況を再現する場合は、CPUのコア数より多くのNICを挿すか、割り込み先のCPUを固定する等の設定が必要になります。
*7:loop1によりパケット受信処理以外のソフト割り込み処理が公平に処理され、loop2により複数あるNICがそれぞれ公平に処理されるように工夫しています。
*8:図10中にも記載しているとおり、「NET_RX_SOFTIRQ」(loop2)レベルでの処理の制約条件についてはカーネルパラメータとなっています。そのため、これらの値は/proc/sys/net/core/netdev_budgetと/proc/sys/net/core/netdev_budget_usecsでそれぞれ確認/変更ができます。
*9:図10ではloop1の継続条件として2つの条件を記載していますが、厳密にはもう1つ条件があります。時間、回数の制約以外にスケジューリングが必要なプロセスが存在した場合には、ポーリングの再スケジューリングは行わずに、処理をksoftirqdに移譲します。