執筆者 : 小田 逸郎
※ 「OS徒然草」連載記事一覧はこちら
仮想化
今ではすっかり、仮想化は日常のものとなってしまいました。筆者が開発で使用しているLinuxマシンでは、仮想マシン(Virtual Machine、VM)やコンテナを動かす方が普通になってますし、オフィス作業用PC(Windows OS)ですらWSLを使ってますしね。VMが盛り上がりを見せだしたのは、2000(00)年代後半くらいからでしょうか。筆者は2007年のVMWorldに参加したのですが、ものすごい人数と熱気に驚いた記憶があります*1。VM自体は、メインフレームでは、40年前から普通に使われて、昔からあった技術ではありました。高価で性能が高いからこそ、VMで何台ものマシンに見せかけるという発想が生まれたのだと思います。x86系マシンでは、性能が向上してきて、それまで複数台で行っていたワークロードが1台でも賄えそうだというところまで来て、ようやく議論の俎上に上がって来たということでしょう。CPU単体のクロック向上が頭打ちになり*2、ハード屋さんがCPUを増やす方向に舵を切ったのに対し、そのユースケースとして、VMがハマったということも盛り上がるきっかけになったかと思います。
ところで、ハイパーバイザーの開発は、何屋の仕事でしょうか。それは、OS屋の仕事です。OSの開発もハイパーバイザーの開発も必要な技術に違いはありません。OSの開発が出来るのであれば、ハイパーバイザーの開発に何ら支障ありません。弊社でも2006年から数年間 Xen ハイパーバイザーの開発に参加していたり*3、セミナーを開いたりもしていました。なお、現在でもXenは、弊社の守備範囲です。
エミュレータ
VMを実装する最も手っ取り早い方法は、エミュレータです。ここで言うエミュレータとは、CPUの命令セットの動作をソフトウェアで実現するものです。Linuxでは、qemuという立派なエミュレータがあって大活躍しています。以下、それをイメージして、読んで貰えればよいかと思います。CPUの命令セットというものは、ざくっと言ってしまえば、結局のところ、メモリとレジスタ*4の状態をどう変えるかを規定しているものと考えることができます。したがって、基本的にエミュレータがしているのは、メモリとレジスタ(にあたるもの)を内部的に用意し、ip*5で示されるメモリから命令を読み出し、メモリとレジスタの状態を変えるということを繰り返しているだけです*6。メモリとレジスタをマシン起動時の状態に初期化し、OSのバイナリをメモリに配置して、そのエントリポイントから命令実行を始めれば、VMとして動作したことになるのではないでしょうか。基本的なアイデアとしては、正にその通りです。ただ、それだけでは外部とのやり取りが何もできないので、まともなVMとするためには、CPUに加えて、デバイスのエミュレーションも行う必要があります。
OSがマシンに載っているデバイスを認識するのは、PCIのコンフィグレーション空間を読んだり、なんらかのI/O命令を実行して行います。エミュレータは、そうした命令が実行された際、あたかも本当のデバイスが付いているように見せかけます。また、デバイスの操作も、どこかのメモリアドレスにマップされたデバイスレジスタを読み書きしたり、なんらかのI/O命令をして行う訳なので、エミュレータとしては、そうした命令が実行された際、実際に操作しているように見せかければ良いことになります。実際にI/Oされたデータをどう取り扱うかですが、例えば、ディスクI/Oに関しては、ホスト上の通常ファイルを実際にデータを読み書きする領域として用意し、エミュレータはこれをあたかもSCSIディスクのパーティションであるとして、VMで動作しているOSには、SCSIディスクが付いていると見せかけます。エミュレータは、SCSIディスクに対するI/O命令が実行されたら、それを通常ファイルへの読み書きに変換して実行します。ネットワークに関しては、例えば、VMには、e1000 NICが付いていると見せかけ、そのデバイスに対する操作をエミュレーションします。パケットの送信命令が実行されれば、エミュレータは、パケットをtunデバイスに送信し、tunデバイスから受信したパケットをあたかもe1000 NICが受信したように見せかける(より詳細には、受信したパケットの内容をデバイスのリングバッファにあたる領域に書き、あたかも割り込みが上がったようにCPUのステートを変更し、割り込みベクタに定義された命令に飛ぶ)というようなことを行います。少し実装の話になりますが、ひとつのCPUの命令実行をひとつのスレッドで行うようにし、そうしたスレッドを複数実行することにより、MPシステムが実現できます。また、それ以外にもI/O処理をバックエンドで行うスレッドを実行し、そのI/O処理と連携して、CPUスレッドで割り込みを発生させるというようなことを行います。ここまで来れば、立派にVMとして使えるでしょう。後、コンソールだとか細々したデバイスのエミュレーションも行っています。注意しておくのは、あくまでもエミュレータが対応しているデバイスのみがVMから見えるということです。大体、どのOSにもドライバが存在しているメジャーなデバイスが対応デバイスとして選ばれていると思います。現在のハードウェアは、CPUとデバイスというだけでは言い表せなくなってきています。例えば、qemuのx86系の対応としては、q35チップセットをエミュレーション、のようにチップセットまで指定しての対応になっています。
エミュレータの実装は、CPUの命令セット(や、それに加えてデバイス)を完全に再現しないといけないので、結構面倒です。ちょっと自分では実装しようという気にはなりません。それでも、実際に回路を設計したり、FPGAで(例えば、RISC-V)CPUを実装したりするのに比べれば、ソフトウェアで実装する方が簡単そうな気がします。それは筆者がソフトウェア側の人間でハードウェア側のことは良く知らないからなのかもしれませんが。まあ、面倒と言っても、通常のソフトウェアシステム(基幹系とか)に比べれば、ずっと易しそうですけどね。要件が曖昧だということもないし、途中で要件の追加変更とかもないですから。まあ、こちらも基幹系の開発経験とかないので、単なる感想に過ぎませんが。それはともかく、エミュレータの開発がOS屋の仕事かと言うと、そうではないですね。どちらかというとハード屋の範疇なのかと思います。OS屋としては、エミュレータを使用する側としてお世話になっています。エミュレータは、ホストのアーキテクチャと異なるアーキテクチャのOSを開発する上では非常に重宝します。弊社ブログの別の連載でもRISC-VのOSを作るプラットフォームとして、qemuを使用しています。筆者が昔、スパコン用OSを開発していたときもエミュレータにお世話になりました。その当時、全く新規のアーキテクチャのスパコンを出そうとしていました。全く新規のアーキテクチャであったため、そもそも実機が存在しておらず、エミュレータを使うしかなかったわけです。エミュレータはハードウェア側が用意してくれてました。ところで、メインフレーム(、スパコン)の世界では、発売日に物が手にはいるわけではないということをご存知でしょうか。普通の製品であれば、発売日には、買って物を手に入れられると思うのが当然でしょう。ところが、発売日というのは、お客さんが買えるようになるのは確かなのですが、それとは別に出荷日というのがあって、実際に出荷、すなわち実際に物が出るのは、発売日の半年後だったりするのです。我々開発者は、ハードウェア側もソフトウェア側も発売日が過ぎたのにまだ鋭意開発中だったりする訳です。新しいアーキテクチャなので、コンパイラも開発中のもので、OS屋は、開発中のコンパイラでコンパイルして、エミュレータの上で動作確認している状況だったのです。後に実機が出てきても、当然顧客に出荷する分が優先なので、開発部隊には最小限の構成のものしか割り当てられません。大規模構成のシステムテストを顧客に出荷されるものを借りて、出荷直前に行うというようなことをしていました。なかなかカオスな状況でした。
閑話休題。
エミュレータでは、一つ一つの命令をソフトウェアで実行するため、実機よりもかなり遅くなります。実機では、1命令の実行で済むところが、十数命令から数十命令費やして実行されることになります。実装を工夫することにより、ある程度は軽減できるとは思います。ただ、遅いといっても、現在のCPUは、例えば、先に話題が出たスパコンに比べても、30倍以上速くなっています*7。それを考えると、少なくとも当時使用していたマシンと同等には使える訳なので、普通に使う分には違和感なく使用できるかもしれません。
ハイパーバイザー
ハイパーバイザーの実装を説明しようとすると、いくら紙面があっても足りませんし、内容が難しくなるので、ここでは行いません。代わりにハイパーバイザーがどんなものか、イメージし易くなるよう、ひとつ思考実験をしてみましょう。ひとつのプロセスをVM(以下、VMプロセス)と見立て、OSのバイナリをロードして、そのまま実行することを考えてみます。ホスト上で動作しているOSをハイパーバイザーと見立てます。VMプロセス上で動作するOS(以下、ゲストOS)のコードを実行するのに、どんな問題があって、どんな対処が考えられるでしょうか。OS屋であれば、以下の4つがまずは思い浮かぶかと思います。
一つ目。ゲストOSはユーザモードで動作しているので、特権命令を実行しようとすると、例外が起きてしまいます。これはこれで好都合です。例外が起きて、ハイパーバイザーに制御が移りますので、その命令をエミュレーションすることにしましょう。例えば、CPUのステートを変える命令であれば、ハイパーバイザーがVMごとのステートを管理しておき、それを変更すると言うようなことです。
二つ目。ゲストOS上のプロセスがシステムコールを発行したり、例外を起こしたらどうしましょう。これもハイパーバイザーに制御が移るので、ハイパーバイザーが、あたかもゲストOSに対し、システムコールや例外が上がったようにお膳立てして、ゲストOS上の然るべきエントリに実行を移せば良いでしょう。
三つ目。これが一番面倒ですが、ゲストOS上のプロセス実行時のページテーブルをどうするか、です。ゲストOS上のプロセスのページテーブル(下図左側)は、ゲストOSが管理しています。これは、ゲストOS上のプロセスの仮想アドレスを実アドレスに変換するものですが、ここでの実アドレス(下図x、y、z)は、ゲストOSが実アドレスだと思っているだけで、実際は、VMプロセスの仮想アドレスです。ページテーブル自身のアドレスもゲストOSが実アドレスだと思っているだけで、実際は、VMプロセスの仮想アドレスであり、真の実アドレスではありません。
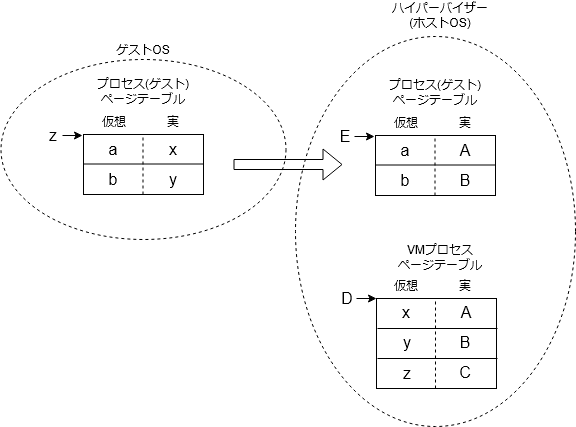
これでは、そのまま、そのページテーブルを設定してもまともに動きません。そもそもページテーブルの設定は特権命令なので、ゲストOSが実行しようとすると、例外となり、ハイパーバイザーに制御が移ります。ハイパーバイザーでは、プロセス(ゲスト)用のページテーブルをもう1セット用意し(上図右上)、ゲストOSが設定しようとしていたページテーブル(上図左)とVMプロセスのページテーブル(上図右下)を参照して、プロセス(ゲスト)仮想アドレスと物理アドレスの変換を行うようにします。そして、そのページテーブルを設定します。つまり、ゲストOSがページテーブルの切り替えを行う度にハイパーバイザーが真のページテーブルに置き換えて設定するということです。
四つ目は、I/Oをどうするかです。これはとりあえず、エミュレータがやっていたように、ハイパーバイザーがデバイスをエミュレーションすることにしておきましょう。ゲストOSがデバイスのレジスタ領域をマップしているアドレスにアクセスしたとき、例外が発生し、ハイパーバイザーに制御が移るようにしておきます。
こうしてみると、何となくハイパーバイザーが実装できそうな気がして来ませんか。実際にはもっと複雑で綿密に考える必要があるでしょうが、実際のハイパーバイザーのコードを解析する際は、上記の観点から実装がどうなっているのか調べてみると良いかと思います。なお、最近のCPUでは仮想化支援機能を備えるものが増えてきて*8、ユーザモードとスーパバイザモードだけでなく、ゲストOSを実行することを想定したゲストスーパバイザモード(ここだけの呼称)とも言うべきモードを持てるようになってきています。ゲストスーパバイザモードでは、一部の特権命令の実行に制限がありますが、大半の特権命令が実行できます。ゲストOSをゲストスーパバイザモードで動作させれば、上記二つ目に関しては、ハイパーバイザーの介入の必要がなくなりますし、一つ目に関しても、ハイパーバイザーの介入は一部のものだけになります。また、三つ目に関してですが、実アドレス(ゲストOS)を実アドレス(真)に変換する、従来のページテーブルと別レベルのページテーブルを持てるようになっているものもあります。ハードウェアはプロセス(ゲスト)アドレスを実変換するために、2つのページテーブル(「プロセス(ゲスト)アドレス→実アドレス(ゲストOS)」「実アドレス(ゲストOS)→実アドレス(真)」)を引くことになります。上図で言うと、ハードウェアが左のページテーブル(z)と右下のページテーブル(D)を引いてくれて、ハイパーバイザーがわざわざ右上のページテーブル(E)を作る必要がなくなったということです。こうした仮想化支援機構により、ハイパーバイザーの実装も楽になってきました。
実在のハイパーバイザーの実装を極簡単に紹介しておきましょう。まずは、KVMです。KVMは、Linuxカーネルの機能の一部で、Linuxカーネルがハイパーバイザーとなります。KVMでは、ゲストスーパバイザモードの存在が前提となります。KVMでは、qemuプロセスが、VMプロセスに当たります。qemuにKVM対応を追加した形になっており、CPU命令の実行に関しては、qemuがエミュレーションするのではなく、そのまま実行することにするのですが、その際に必要な一切合切をKVMに任せます(この際、qemuプロセス空間のどの領域をゲストOSの実メモリと見なしているかをKVMに通知します)。上記、一つ目(一部)、三つ目はKVMで処理されることになります。I/Oに関しては、依然、qemuのデバイスエミュレーションを使用しています。KVMでは、I/Oがあれば、qemuに制御を戻し、qemu従来のデバイスエミュレーションが実行されます。
次にXenです。Xenは、KVMよりも歴史が古く、仮想化支援機構がないCPUにも対応しているのが特徴ですが、最近のCPUは大体装備しているので、今となってはあまり意味がないかもしれません。Xenは、独立したハイパーバイザーとして実装されています。機能としては、実メモリ管理、VMの仮想空間管理、VMのスケジューラ、割り込み関連など、OSのサブセットのような感じで、通常のOSに比べるとかなりコンパクトになります。Xenでは、dom0と呼ばれる特殊なVM*9が動作しています。dom0では、Linuxが動作しており、VMの管理やホストに付いているデバイスのI/Oを担当しています*10。Xen自身には、デバイスドライバはありません。dom0のLinux上でqemuが動作しており、VMには、qemuがエミュレーションしているデバイスが見えることになります。すなわち、VMのI/Oは、dom0上のqemuに任せているという訳です*11。もう、qemuが大活躍ですね。ホストをVM専用マシンとして使用するのであれば、ハイパーバイザーとして、Linuxを使用するのはオーバスペック過ぎます。その点、Xenはコンパクトでいいな、と思いきや、結局、dom0でLinuxを動作させるので、その分のメモリリソースとCPUリソースを使用してしまうことになり、ちょっとがっかりです。
virtio
VMのI/Oをデバイスエミュレーションで行うのは如何にも効率が悪そうです。そこで編み出されたのがvirtioです。virtioは、ゲストOSのメモリ上にデータをやり取りするためのリングバッファを設け、それを通して、ホストOSとのデータをやり取りするプロトコルを定義しているもので、そのプロトコルに対応したネットワークデバイス(、ドライバ)やディスクデバイス(、ドライバ)(等)が作られました。デバイス自体は、VMからは、PCIデバイスに見えていて、そのお膳立ては、(依然)qemuが行っています。(下記は、ゲストOS上で、lspciした例)
$ lspci ... 00:03.0 Ethernet controller: Red Hat, Inc. Virtio network device 00:04.0 SCSI storage controller: Red Hat, Inc. Virtio block device ...
バックエンド(ホスト側のファイルやtunデバイス)へのアクセスは、依然qemuに制御を移して、qemuが行いますが、デバイスのエミュレーションをする必要はないので、オーバヘッドは少なくなります。また、qemuに制御を移さず、バックエンドへのアクセスをカーネルが行うタイプのドライバ(ex. vhost-net)もあり、さらにオーバヘッドを減らすことができます。ここまで来ると、I/Oについても一安心と言ったところです。
VMのI/Oに関しては、もう一つ、パススルーという方式が考えられます。パススルーとは、デバイスのアクセスをVMに移譲し、ゲストOSのドライバが直接実デバイスにアクセスする形態です。PCIパススルーというPCIデバイスをパススルーするのが良く知られています。どのデバイスをどのVMが使用しているかはホスト側が管理する必要があります。パススルーで最も考慮が必要なのは、DMA転送です。デバイスによってはDMAと言って、直接メモリにアクセスすることができますが、VMにパススルーされたデバイスでは、実アドレス(ゲストOS)ではなく、実アドレス(真)を意識する必要があり、ゲストOS側にもなんらかの対処が必要となります。最近のハードウェアでは、これに対してもIOMMUという支援機構がサポートされてきています。IOMMUというのは、デバイス毎にアドレス変換テーブル(実アドレス(ゲストOS)→実アドレス(真))を持てるようにしたもので、これにより、ゲストOS側での対処が必要ない上、他のゲストOSのメモリを誤って破壊する危険が減って、大変便利になりました。デバイス(PCIe)側でもSR-IOVと言って、一つのデバイスを複数に見せかけられるような機能も出てきました。これでデバイスの数の問題が緩和し、VMにパススルーし易くなってきました。
ちなみに、昔のメインフレームの仮想化は、パススルー方式でした。デバイスをVMに割り当て、そのデバイスをVMが占有する形態です。ディスク装置はVMの数(以上)分ないといけませんが、磁気テープ装置のように常時使うものではないデバイスは、必要になったときにVMに割り当てて使用していました。運用中の割り当てや解放ができました。デバイスはチャネルI/Oといって、I/O用のプロセッサが別にあるようなタイプで、そのプロセッサに対するコマンドを(ゲストOS上の)メモリに置いてそのアドレスを指定する形でした。ハイパーバイザーの実装は把握していませんが、アドレス変換処理がどこかで行われていたはずだと思います。
コンテナ
仮想化として、VMと同じかそれ以上に話題に上るのがコンテナでしょう。Linuxを例に取ると、コンテナを実現するための技術としては、名前空間とかcgroupとかが使用されています。機能自体はそれなりに便利だと思いますが、OS屋としての技術的関心はそこまでで、はいお終いです。
コンテナが使用されるメインの理由はアプリケーションの独立性かと思います。動的ライブラリが登場した当時はそれなりに便利な機能かと思いました。libcなんかは全てのアプリケーションが使用する訳で、共有した方がリソース効率が良いですもんね。しかし、今はライブラリの数が増えすぎて大変なことになっています。プロセスの仮想空間のマップ*12を見るとセグメント数の多さに驚いてしまいます。OSの制御構造にも影響を与えているようです*13。ディストリビューションは、ライブラリ間の整合性を保証しているのが、その価値であり、そのためコンテナごとにディストリビューションを抱え込むようにしているのかと思いますが、筆者なんかは、静的リンクすればいいじゃんと思ってしまいますし、もう少しましな方法がありそうに思います。
コンテナがよく使用されるようになると、今度はそれを管理するソフトウェア(ex. Kubernetes)が出てきます。コンテナ(Pod)ごとにIPアドレスを振って、ネットワーク的に独立した物として扱うため、それを制御するソフトウェアも必要となってきます。ただ、結局のところ、Kubernetes含め、それらのソフトウェアで行っていることは、アプリケーションで本当にやりたいことからすると、オーバヘッドにしか過ぎません*14。昔は、OSの上にアプリケーションという単純な階層構造でした。OSはオーバヘッドなんだから、できるだけ軽くせよと言われたものです。最近はOSのオーバヘッドも増えている気がしますが、それ以上にOSの上、その上とどんどんアプリケーションに至るまでのオーバヘッドの階層が積みあがってきている気がします。筆者は、パーキンソンの法則という言葉がふと頭をよぎりました。CPUの性能が上がり、数も増えましたが、その分、すべて新たなオーバヘッドで食いつぶされているのではなかろうかと。
あとがき
筆者のネタも尽きて来たので、OS徒然草は、今回で一旦終了です。またネタを思いついたら、単発で何か書くかもしれません。
OS徒然草は、特定のOSを仮定したものではありませんでしたが、次は、Linuxを具体的な対象として新シリーズを開始するつもりです。OS徒然草は、どうでもよい話が多かった(というか、そちらがメインのつもり)ですが、今度は(どちらかと言うと)テクニカルな方に比重を置く予定です。ではまた新シリーズで。
*1:VMwareのカンファレンス。1万人以上の参加者に200以上のセッション。セッション資料の準備だけでもどんだけ工数掛かってるんだ、と思いました。
*2:2003年くらいからもう向上していません。それまではものすごい勢いで向上していたのですが。
*3:IA64アーキテクチャ依存部分の開発をしていました。一時期、IA64アーキテクチャのメンテナを務めていたこともあります。今では、IA64アーキテクチャはサポートされていませんが。
*4:汎用レジスタだけでなく、コントロールレジスタ等、CPUのステートを管理するものを含めてすべてのもの。
*5:instruction pointer。次に実行すべき命令のアドレスが格納されたレジスタ。
*6:まあ、それが正にCPUがしていることなので、当然と言えば当然ですが。RISC-Vの仕様書では、仕様に従って動作するものをhartと呼んでおり、それはハード的なプロセッサだけでなく、ソフトウェアによるエミュレータも含んでいます。
*7:90年代初頭。100MHzくらいでした。ただし、1クロックあたり複数演算できたり、ベクトル計算機構があったりとかで、クロックだけで性能は語れません。なお、スパコンの世界では、FLOPS(秒あたりの浮動小数点演算数)が指標となっていて、クロック周波数はあまり表にでてこないです。
*8:RISC-Vもその一例。弊社ブログRISC-V ハイパーバイザーを作ろうも参照。
*9:Xenでは、VMのことをdomainと呼んでいます。
*10:正確には、Linux以外のOS(ex. NetBSD)でも良いですが、Linuxが一般的です。
*11:XenのVMには準仮想化というタイプもあり、デバイスエミュレーションではなく、ゲストOSとdom0上のLinuxが連携してI/Oを行う形のドライバもあります。
*12:Linuxでは、/proc/{pid}/maps。
*13:Linuxでは、maple treeを導入した。
*14:ここに書いたことは、そのままVMにも当てはまりますが、割愛しました。