「Linuxカーネル2.6解読室」(以降、旧版)出版後、Linuxには多くの機能が追加され、エンタープライズ領域をはじめとする様々な場所で使われるようになりました。 それに伴いコードが肥大かつ複雑化し、多くのエンジニアにとって解読不能なブラックボックスとなっています。 世界中のトップエンジニア達の傑作であるLinuxカーネルにメスを入れ、ブラックボックスをこじ開けて、時に好奇心の赴くままにカーネルの世界を解読する「新Linuxカーネル解読室」プロジェクト。
本稿では、ネットワーク機能の受信処理におけるEthernetドライバについてカーネルv6.8のコードをベースに解説します。
執筆者 : 須田 哲志、稲葉 貴昭
※ 「新Linuxカーネル解読室」連載記事一覧はこちら
はじめに
前回まではソケットインターフェースについて解説してきました。 今回からはデバイスが受信したパケットをソケットに配送するまで、すなわちパケットの受信処理について解説していきたいと思います。 今回と次回はEthernetドライバにおけるパケット受信処理を見ていきます。 (もともと1本の記事の予定でしたが、とんでもなく長くなってしまったため2回に分けることになりました。)
前提条件
パケットの受信処理は、ネットワークデバイスドライバ、プロトコルおよびカーネルパラメータなど様々な組み合わせがあり、それらの組み合わせによって通るロジックが異なるため、すべてを調査するのは非現実的です。 そこで、本記事より複数回に渡って解説するパケットの受信処理では以下を前提として話を進めます。
- アプリが
recvfrom(2)でUDP/IPv4のパケットを受信する際のカーネルの流れを追うことをメインとする - 異常系・エラー系のパスは対象外とする
- NICはIntelのNIC(e1000eドライバ)を1枚だけ搭載
※割り込み方式はMSI(Message Signaled Interrupts)を想定 - パケットの受信処理を追うことに集中するため、以下の機能についてはまた別記事で解説する
- GRO/LROなどのoffload機能
- RSS/RPS/RFSなどのマルチキュー関連機能
- VLAN
- チェックサム
- どの程度使用されているか不明な機能や、近年使用されることが少なくなっている機能(IPフラグメントなど)についてはスコープ外とする
また、IPv6、TCP、ルーティングなどの重要な機能は将来的に解説する予定です。
1. 概要
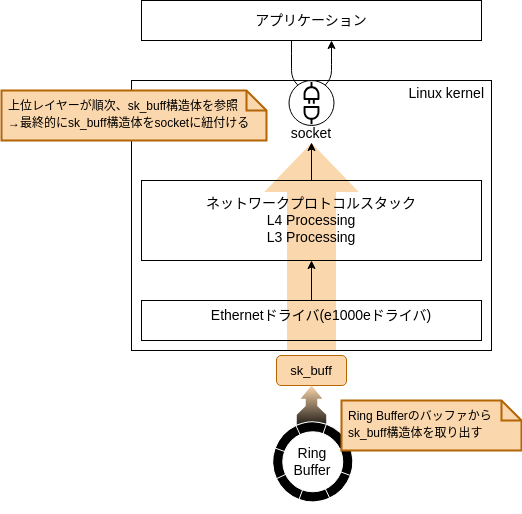
今回の記事ではデバイス(NIC)がパケットを受信し、パケットがIPレイヤーに渡るまでの過程を概観していきます。 まずはパケット受信時の全体の流れを大まかに見てみましょう。 NICが受信したパケットを、アプリケーションまで配送する流れは図1のようになります。

図1中の番号の処理は以下のようになります。
1. NICにパケットが到着
2. NICが受信したパケットをリングバッファに書き込む
3. NICが割り込みを発行し、ハード割り込みコンテキストに処理が移る
4. 割り込みハンドラでポーリングのスケジューリングを要求し、ソフト割り込みをキックする
5. ポーリングハンドラ*1でポーリングを行い、順次リングバッファに保存されているパケットを受信する
6. 受信したパケットを上位レイヤーに配送する
7. ソケットインターフェースに受信データを配送する
8. アプリケーションがrecvfrom(2)システムコールを呼び出した際に、受信データをアプリケーションに渡す
図1では大まかな流れを示しましたが、実際には非同期で動いている部分もあるため、図中の①〜⑧をすべて順次処理するとは限りません。 そこで、今度は図1の流れをシーケンスとして見てみましょう。

図2中の①〜⑦は図1中の番号と対応しています。(⑧の処理はユーザ空間からのシステムコール呼び出しのため割愛しました。) 大きな流れとして「ハード割り込みコンテキスト」→「ソフト割り込みコンテキスト」と処理が移っていることがわかります。 また、当然ですが図2の通り、Linuxカーネルが受信処理をしている間にも、デバイス(NIC)にはパケットが到着し、逐次リングバッファにデータが書き込まれます。 この逐次リングバッファに書き込まれる受信データを実際に取り出して、ソケットインターフェースまで配送しているのは「ソフト割り込みコンテキスト」で動く処理(図1,2の⑤〜⑦)が担っています。 そのため、デバイス(NIC)からの割り込み要求(IRQ)を検知し、ソフト割り込みをキックすることが割り込みハンドラ(in「ハード割り込みコンテキスト」)の重要な役割になります。
ところで、なぜパケットの受信処理が「ハード割り込みコンテキスト」と「ソフト割り込みコンテキスト」に分かれているのでしょうか。 パケットのポーリングによる受信処理ではNAPI(New API)と呼ばれる仕組みが利用されており、このNAPIの導入背景がまさにこの理由を物語っています。 NAPIについては弊社の過去の技術ブログで解説していますので、今回はそちらから引用したいと思います。
NAPI とは New API の略で、パケットの受信処理で利用されている仕組みです。
"New" とは言っていますが、そもそも登場したのが v2.5(後に、v2.4 にバックポートされた)で、全く「新しく」はありませんが、それ以前は、パケットを受信する度に割り込みを上げてその割り込み処理により受信処理を行っていました。この方法では、ネットワークの負荷が軽い場合はパケットを高速に処理できるというメリットもありますが、ネットワークの負荷が上がると CPU が割り込み処理により高負荷となり、システムの応答性が悪くなるという問題がありました。
NAPI では、パケットの到着の通知(割り込み)とパケットの受信処理を分離して、
* パケットが到着するとソフトウェア割り込みを raise し、受信処理はソフトウェア割り込み処理として行う。
* 受信処理中にパケットを受信しても、通知(ソフトウェア割り込みを raise)しない。
* 受信処理では NIC のキューを polling する(なので通知する必要がない)。
というふうに、割り込みによる通知と polling のハイブリッドな実装とすることで上記の問題を解決しています。
次章から、割り込みハンドラとポーリングハンドラにおける処理をそれぞれ追っていきます。
2. 割り込みハンドラにおける処理
それでは割り込みハンドラの処理から見ていきましょう。 前章で見たとおり、割り込みハンドラはNICから割り込み要求(IRQ)を受信した際に「ハード割り込みコンテキスト」で実行する処理になります。

パケットを実際に受信する処理は、ポーリングハンドラを入口とする「ソフト割り込みコンテキスト」の処理が担っていますが、割り込みハンドラはそのお膳立ての処理をしていると言えます。 このお膳立ての処理として以下の3つが重要になります。
NICの割り込み禁止
ポーリングによってパケットを受信するため、以降のパケット受信時の割り込みを禁止します。NAPIポーリングのスケジューリング
「ソフト割り込みコンテキスト」に処理が移り、パケットの受信処理を実行した際に、デバイス(NIC)をポーリングするように、ポーリングのスケジューリングを要求します。NET_RX_SOFTIRQのraise
ソフト割り込みをキックし、「ソフト割り込みコンテキスト」に処理が移った際に、パケットの受信処理を実行することを要求します。
それでは、これら3つの処理をどのように実装しているのか、実際のソースコードを見てみましょう。
今回の例(e1000eドライバ)では、割り込みハンドラとして以下のe1000_intr_msi()を実行します。
*2
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static irqreturn_t e1000_intr_msi(int __always_unused irq, void *data) { ... u32 icr = er32(ICR); // 筆者コメント: 割り込み禁止 ... if (napi_schedule_prep(&adapter->napi)) { ... __napi_schedule(&adapter->napi); // 筆者コメント: ポーリングのスケジュールとNET_RX_SOFTIRQのraise } ... }
まずはNICの割り込みを禁止する処理です。
一見、e1000eドライバでは明示的に割り込みを禁止する処理が無いように見えますが、er32(ICR)を実行すると自動的に割り込みも禁止されます。
NICのICR(Interrupt Cause Read)レジスタは割り込みの原因を示すレジスタであり、er32(ICR)はICRレジスタの値を読み出す処理です。*3
(上記のソースコードでは省略してしまっていますが、e1000_intr_msi()ではICRレジスタを参照してリンクステートの状態をチェックする等しています。)
このときNICの仕様によりICRレジスタを読み出すと、自動的にNICが割り込み禁止状態になります。*4
続いてポーリングのスケジューリングとNET_RX_SOFTIRQのraiseについて見ていきましょう。
これらの処理は__napi_schedule()が呼びだす____napi_schedule()で実行します。
(e1000_intr_msi()を起点とした呼び出し関係を整理すると以下のようになります。)
e1000_intr_msi()
└── __napi_schedule()
└── ____napi_schedule()
それでは____napi_schedule()を見てみましょう。
(/net/core/dev.c)
static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi) { ... list_add_tail(&napi->poll_list, &sd->poll_list); // 筆者コメント: NAPIポーリングのスケジューリング要求 ... if (!sd->in_net_rx_action) __raise_softirq_irqoff(NET_RX_SOFTIRQ); // 筆者コメント: NET_RX_SOFTIRQをraise }
上記ソースコードの最後に__raise_softirq_irqoff(NET_RX_SOFTIRQ)でNET_RX_SOFTIRQをraiseしていることがわかります。
NET_RX_SOFTIRQをraiseしておくことで、後にソフト割り込みがキックされた際にNET_RX_SOFTIRQソフト割り込み(net_rx_action())を実行することになります。
そして、ポーリングのスケジューリングについてですが、前述のとおりLinuxカーネルではパケットの受信処理にNAPI(New API)という仕組みを利用してポーリングを行います。
list_add_tail(&napi->poll_list, &sd->poll_list)ではsoftnet_data構造体のpoll_listにドライバのnapi構造体を繋げています。
これにより、処理がNET_RX_SOFTIRQソフト割り込みコンテキストに移った際にNAPIがポーリングを実行します。
ハード割り込みコンテキストからソフト割り込みコンテキストへの切り替わりについては過去のブログでも解説しています。興味のある方や、より詳細を知りたい方は参照してみてください。
ここまで「ハード割り込みコンテキスト」で動作する割り込みハンドラの処理を見てきました。 割り込みハンドラでは「ソフト割り込みコンテキスト」のためのお膳立てをしているだけで、パケットの受信に関する処理はほとんど何もしていないことがわかったと思います。 次章ではいよいよ受信処理の入口となるポーリングハンドラの処理を見ていきます。
3. ポーリングハンドラ(NAPI)による受信処理
3.1 前提知識: sk_buff構造体
受信処理の解説をする前にsk_buff構造体という重要なデータ構造を紹介しておきます。 sk_buff構造体は今回の記事だけでなく、今後、ネットワーク関係の記事でも出てくることになります。
Linuxがパケットを送受信する際、パケットのデータは当然ですが、あるメモリ領域に保存されています。 sk_buff構造体は、パケットのメタデータであり、パケットのデータを保存するメモリ領域を指し示しています。
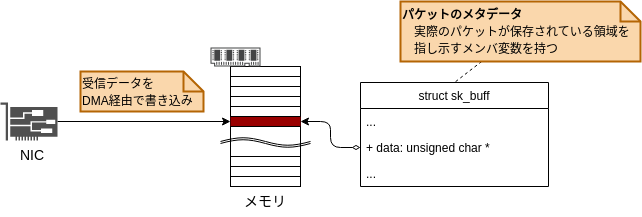
各種処理でパケットを操作したり参照する場合には、このsk_buff構造体を介します。
sk_buff構造体のメンバ変数は非常に多く、ここですべてを解説することはできません。 sk_buff構造体の各種メンバ変数や操作関数といったものは、解説が必要になったタイミングで都度、触れていきたいと思います。
3.2 概要
本章ではポーリングによるパケットの受信処理を見ていきます。 図2のシーケンス図からポーリング処理部分を抜粋してみます。

loopで囲んでいる部分がポーリングによるパケットの受信処理に該当します。
リングバッファから順次、複数のパケットを読みだしてからまとめて上位のネットワークプロトコルスタックにデータ(=受信パケット)を渡している(=ip_list_rcv()を呼び出している)ことがわかります。
また、上位のネットワークプロトコルスタックがデータを処理するまでは次のデータ読み取りを開始しない、つまりリングバッファからのデータ読み取りとネットワークプロトコルスタックでの処理が同期してしまっていることがわかります。
実際のソースコードを見てみましょう。これらの処理は図6中にも記載しているとおりe1000_clean_rx_irq()関数で行います。
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static bool e1000_clean_rx_irq(struct e1000_ring *rx_ring, int *work_done, int work_to_do) { ... while (staterr & E1000_RXD_STAT_DD) { struct sk_buff *skb; ... skb = buffer_info->skb; // 筆者コメント: リングバッファのバッファからskbを取り出す(データ読み取り) ... e1000_receive_skb(adapter, netdev, skb, staterr, rx_desc->wb.upper.vlan); // 筆者コメント: skbのリスト作成 or 上位ネットワークプロトコルスタック処理 next_desc: ... buffer_info = next_buffer; // 筆者コメント: 参照先を次のバッファにセット ... } ... }
whileループでリングバッファのバッファから順次sk_buff構造体を取り出し、e1000_receive_skb()関数を経由して最終的に上位ネットワークプロトコルスタックの処理を呼び出します。
一見すると1パケット読み取るごとに、上位ネットワークプロトコルスタックの処理を呼び出しそうですが、実際には複数のパケット(sk_buff構造体)をリストにまとめ、リストが一定の長さを超えたタイミングで上位ネットワークプロトコルスタックに送っています。
次回はこのe1000_receive_skb()関数以降の処理を深堀していきます。
本節の最後に割り込み禁止の解除について触れておきたいと思います。
割り込みハンドラでは、ポーリングによってパケットを受信するためにNICからの割り込みを禁止にしていました。
そのため、ポーリングによるパケット受信処理が終了した段階でNICからの割り込みを再度有効にする必要があります。
それを行っているのが、e1000_clean_rx_irq()の呼び出し元であるe1000e_poll()(=ポーリングハンドラ)です。
net_rx_action() // NET_RX_SOFTIRQソフト割り込みの起点
└── napi_poll()
└── e1000e_poll() // ポーリングハンドラ: ポーリング処理の呼び出し、終了処理(割り込み禁止解除)
└── e1000_clean_rx_irq() // ポーリング処理(本節で解説していた関数)
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static int e1000e_poll(struct napi_struct *napi, int budget) { ... adapter->clean_rx(adapter->rx_ring, &work_done, budget); // 筆者コメント: ポーリングによる受信処理(e1000_clean_rx_irqの呼び出し) ... if (likely(napi_complete_done(napi, work_done))) { // 筆者コメント: ポーリング終了処理 ... if (!test_bit(__E1000_DOWN, &adapter->state)) { ... else e1000_irq_enable(adapter); // 筆者コメント: 割り込み禁止解除 } } ... }
e1000e_poll()では先程まで解説していた、e1000_clean_rx_irq()を呼び出した後にポーリング終了処理として、e1000_irq_enable()で割り込みを有効化(=割り込み禁止解除)していることがわかります。
これにより、NICが再度パケットを受信した際には割り込みが上がるようになります。
4. sk_buff構造体の生成
前章で見てきたように、sk_buff構造体はLinuxカーネルがパケットを扱う上で、パケットと組になる非常に重要なデータ構造です。 本記事の最後では、このsk_buff構造体を生成する流れを見ていきたいと思います。
4.1 リングバッファのバッファ構造
受信処理において最初にsk_buff構造体が登場するのはリングバッファのバッファから受信データを読み取るところでした。 それではリングバッファはどのような構造になっているのでしょうか。 リングバッファの各バッファはe1000_buffer構造体として図7に示す構造となっています。
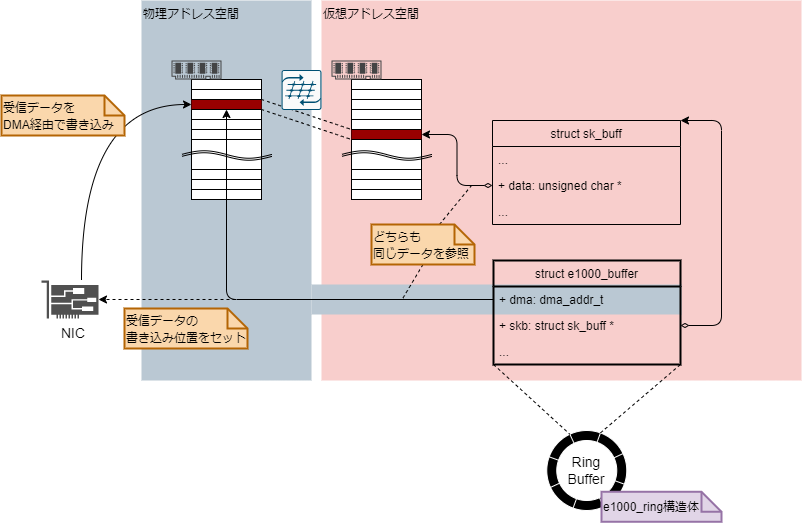
e1000_buffer構造体ではsk_buff構造体とセットでdmaというメンバ変数を持っていることがわかります。
これは受信パケットの書き込み位置の物理アドレスを示しています。
sk_buff構造体でもdataというポインタ型変数で受信データの書き込み位置を保持していますが、これは仮想アドレスになります。
NICはDMAによって受信パケットをメモリに書き込みますが、NICが解釈できるのは物理アドレスのみになります。
そのため、e1000_buffer構造体ではNICに受信パケットの書き込み位置を指示するための物理アドレスの情報として、dmaというメンバ変数を持っています。
(厳密にはNICが解釈できるのはバスアドレスですが、ここでは話を簡単にするために「バスアドレス=物理アドレス」としています。)
ところでNAPIポーリングで受信処理を実行した直後のバッファ状態はどのようになっているのでしょうか。 実際にソースコード見てみましょう。
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static bool e1000_clean_rx_irq(struct e1000_ring *rx_ring, int *work_done, int work_to_do) { ... while (staterr & E1000_RXD_STAT_DD) { struct sk_buff *skb; ... skb = buffer_info->skb; // 筆者コメント: リングバッファからskbを取り出す(データ読み取り) buffer_info->skb = NULL; // 筆者コメント: リングバッファからskbを切り離す ... buffer_info->dma = 0; // 筆者コメント: 書き込み位置(物理アドレス)をクリア ... e1000_receive_skb(adapter, netdev, skb, staterr, rx_desc->wb.upper.vlan); // 筆者コメント: skbのリスト作成 or 上位ネットワークスタック処理 next_desc: ... buffer_info = next_buffer; // 筆者コメント: 参照先を次のバッファにセット ... } ... }
バッファからsk_buff構造体を取り出した後、バッファのskb(sk_buff構造体へのポインタ)にはNULLをセットし、バッファからsk_buff構造体を切り離していることがわかります。
また、バッファのdmaにも0を代入し、受信パケットの書き込み位置をクリアしていることがわかります。
この状態を図示すると図8のような状態になります。
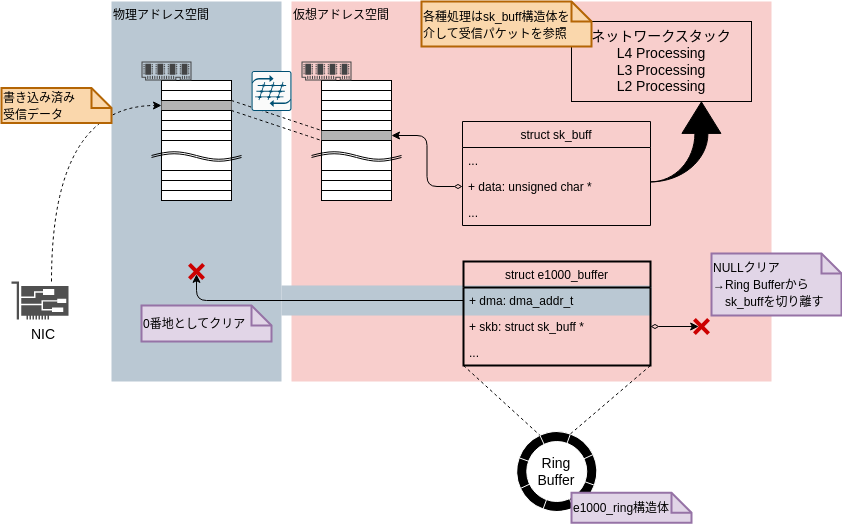
したがって、この受信処理が終わったタイミングでsk_buff構造体を生成(=メモリ確保)し、再度、図7の状態にバッファを戻す必要があります。
それを行っているのが、以下のwhileループを抜けた後に行っているadapter->alloc_rx_buf(rx_ring, cleaned_count, GFP_ATOMIC);です。
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static bool e1000_clean_rx_irq(struct e1000_ring *rx_ring, int *work_done, int work_to_do) { ... while (staterr & E1000_RXD_STAT_DD) { // 筆者コメント: ポーリングによる受信処理 ... } ... if (cleaned_count) adapter->alloc_rx_buf(rx_ring, cleaned_count, GFP_ATOMIC); // 筆者コメント: 受信バッファ追加確保(skbの生成) ... }
adapter->alloc_rx_bufは関数ポインタになっており、これにはe1000_alloc_rx_buffersを登録しています。*5

次節ではこのe1000_alloc_rx_buffers()の処理について見てみます。
4.2 sk_buff構造体の生成
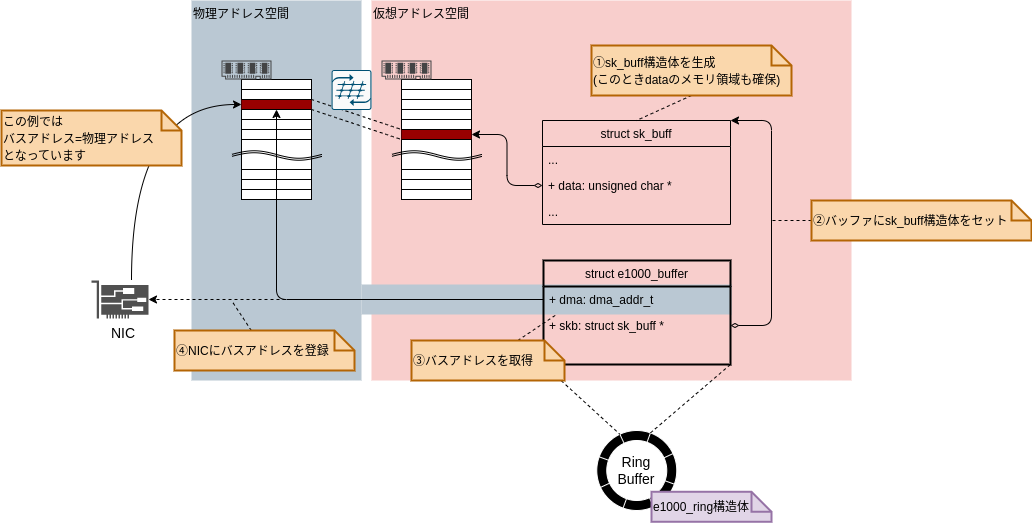
e1000_alloc_rx_buffers()ではsk_buff構造体を生成(=メモリ確保)し、NICが再度、当該バッファに書き込める状態にしています。
(要するに図8の状態から図7の状態にする処理を行っています。)
まずはソースコードを見てみましょう。
(/drivers/net/ethernet/intel/e1000e/netdev.c)
static void e1000_alloc_rx_buffers(struct e1000_ring *rx_ring, int cleaned_count, gfp_t gfp) { ... struct sk_buff *skb; ... while (cleaned_count--) { ... skb = __netdev_alloc_skb_ip_align(netdev, bufsz, gfp); // 筆者コメント: data含めskbのメモリ領域を確保 ... buffer_info->skb = skb; // 筆者コメント: バッファにskbを登録 map_skb: buffer_info->dma = dma_map_single(&pdev->dev, skb->data, adapter->rx_buffer_len, DMA_FROM_DEVICE); // 筆者コメント: バスアドレスを取得 ... rx_desc->read.buffer_addr = cpu_to_le64(buffer_info->dma); // 筆者コメント: NICに書き込み位置(バスアドレス)を登録 ... } ... }
__netdev_alloc_skb_ip_align()関数で、受信パケットを書き込むdataのメモリ領域も含めて、sk_buff構造体全体のメモリ領域を確保します。
そして確保したsk_buff構造体(skb)をバッファ(buffer_info->skb)にセットします。
dma_map_single()関数はskb->dataからNICが解釈できる物理アドレス(バスアドレス)を取得しています。
*6
最後に取得した物理アドレス(バスアドレス)をNICにセットすることで、NICが当該バッファに受信データを書き込める状態となります。
これらの流れを図示すると図10のように表現できます。
本章ではポーリングによる受信処理後の受信バッファの追加確保(sk_buff構造体の生成)の流れを説明しましたが、
受信処理開始前、すなわちデバイスがアップした直後の初期化処理でもe1000_alloc_rx_buffers()により受信バッファを確保しています。
次回予告
今回は「Ethernetドライバ 概要編」として、NICがパケットを受信するところから、パケットがIPレイヤーに渡る部分までを俯瞰して見てきました。 次回は本記事の3章「ポーリングハンドラ(NAPI)による受信処理」で解説したポーリングハンドラの処理を深堀していきます。 ポーリングハンドラはパケットの受信処理の入口にあたる処理を担っていますが、ここでは上位ネットワークスタックへパケットを配送するための関数呼び出しをなるべく減らすような工夫がなされています。 またGeneric XDP処理へ入っていくためのフックなども埋め込まれています。 次回の内容は今回に比べて、かなり細かい話が多くなると思いますが、楽しみに待っていただけると幸いです。
*1:解説対象であるe1000eにおけるポーリングハンドラはe1000e_poll()になります。
*2:e1000eドライバでは、割り込みハンドラとしてe1000_intr()、e1000_intr_msi()、e1000_intr_msix()を用意しています。前提条件に記載していますが、今回は割り込み方式がMSIであることを想定しているため、本記事ではMSIに対応したe1000_intr_msi()を解説対象としています。
*3:各種レジスタの仕様についてはこちらを参照ください。https://www.intel.com/content/dam/www/public/us/en/documents/manuals/pcie-gbe-controllers-open-source-manual.pdf
*4:読み出し時に割り込みを禁止するには、事前にIAM(Interrupt Acknowledge Auto Mask)レジスタやCTRL_EXTレジスタ(Extended Device Control Register)のIAME(Interrupt Acknowledge Auto-Mask Enable)フィールドを設定する必要がありますが、これらはe1000_configure_rx()で設定しています。
*5:デバイスがUPしたときに実行する初期化関数(e1000e_open->e1000_configure_rx)の中で、adapter->alloc_rx_bufにe1000_alloc_rx_buffersを登録します。
*6:この辺りはDMAの話なので詳細は割愛しますが、NICが解釈できるアドレスは厳密にはバスアドレスと呼ばれるもので、物理アドレスと異なることがあります。受信パケットが書き込まれる物理アドレスはskb->dataからも計算できますが、バスアドレスが物理アドレスと異なる可能性があることや、DMA固有の処理(バウンスバッファの確保など)を実施するためにdma_map_single()を呼び出す必要があります。