執筆者 : 小田 逸郎
※ 「OS徒然草」連載記事一覧はこちら
マルチプロセス
複数プログラムの実行
昔は、CPUが高価だったので、極力遊ばせずに使い倒そうという考えになるのは自然なことでした。単純にひとつのプログラムを実行し、それが終わってから、次のプログラムを実行するというのでは、何が問題なのでしょうか。普通、プログラムにはデバイスに対するI/Oが付き物です。例えば、プログラムでディスク上のファイルにアクセスすれば、ディスクへのI/Oが発生します。以下のようなコードを考えてみましょう。
ret = read(fd, buf, sizeof(buf)); /* read(2)システムコール実行 */
... /* bufに読み込んだデータに対し、何らかの処理 */
このコード例では、bufにデータが格納されるまで、プログラムは待つしかありません。read()の延長でOSが何をしているのか想像してみましょう。最も単純には、以下のような処理が考えられます。
/* どこかのアドレスのどこかのビットを見れば、I/Oの完了が分かるという想定 */
volatile uint32_t *status_reg = (uint32_t *)STATUS_REG_ADDRESS; /* ex. 0x1060 */
... /* ディスクに対するI/O(DMA転送)指示 */
while (!(*status_reg & 0x1)) ; /* I/O 完了するまでループ */
... /* I/O完了後の処理 */
I/Oが完了するまで、延々とアドレスに対するロードと値のチェックを行う命令を繰り返すというものです。この方式をポーリングと言います。ひとつのプログラムを実行するだけなら、まあ考えられなくもないですが、CPUを浪費しているのは勿体ないです。最近のCPUは、クロックがns(ナノ秒)のオーダでディスクI/Oはms(ミリ秒)のオーダなので、相当無駄にしていることになります。昔のCPUはそれほどには速くなかったですが、それでもディスクI/O*1に比べるとかなりの差がありました。
そこで、ポーリングでCPUを無駄遣いするより、I/O完了待ちの間、別のプログラムを実行しようという発想が生じます。ここで割り込みの出番となります。上の例では、敢えてポーリングをしましたが、通常のデバイスでは、I/Oの完了時(とか発生時)に割り込みを上げるという機能が備わっています。割り込みを使用した基本戦略としては、デバイスに対するI/O発行後、別のプログラムの実行を行い、I/O完了割り込みが上がったら、元のプログラムの実行に戻すというものが考えられます。図示すると、以下のようなイメージです。
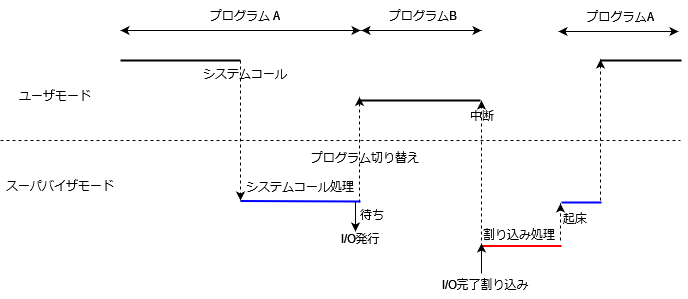
プログラムAのI/Oが完了する前にプログラムBが待ちに入るケースもあります。その場合はまた別のプログラムを実行します。
さて、OSがCPUで実行する単位として管理する対象をプロセス*2と言います。プログラムを実行すると、そのCPUでの実行を管理するためのプロセスが生成されるということになります。同じプログラムを複数実行することも可能で、その場合、プロセスとしては別々のものになります。同じプログラムといっても、データやスタックは別ですからね。仮想空間もプロセスごとに別となります。上の図では、プログラムと言う用語を使用していますが、OSの観点では、プロセスという用語を使う方が自然です。今後は、プロセスという用語を使用することにします。
UNIXが登場したとき、マルチプロセス・マルチユーザシステムというのが売り文句でした。今では、プロセスを複数実行できるというのは当たり前すぎますが、当時はそれが売りになったんですね。UNIXを使用していると、知らず知らずに内に上図のような状態を実現していたりすることがあります。
$ command1 | command2
こんな感じで、よくパイプというものを使うことがあると思いますが、このとき、command1とcommand2は同時に動いています。例えば、command1がファイルから読み込んだ内容を加工して出力し、それがcomman2の入力となって、command2が処理するとしましょう。command1がファイル入力、処理、出力を繰り返すパターンであれば、command1がファイルからの入力待ちになったときに、command2が動けますのでいい感じにCPUを有効活用できます。
バッチとTSS
筆者が始めて触れたコンピュータはメインフレームだったのですが、その使用形態として、パッチとTSS(タイムシェアリングシステム)の2種類がありました。
バッチというのは、プログラムの実行を依頼したら、後は結果が出るまで待つという形態です。バッチでのプログラム実行をジョブと呼んでいて、ジョブコントロール言語(JCL)という簡易言語で、実行するプログラムやその入力デバイスなどを記述して、コンピュータに読み込ませていました。プログラムはひとつだけでなく、一連のプログラム実行の記述やプログラムの実行結果により、後続のプログラムを変えるなどの制御もできました。ジョブの実行依頼を行うことをジョブを投入すると言ったりします。昔はジョブの投入をカードで行っていました。JCLやプログラムコードをカードにパンチして、カードリーダでコンピュータに読み込ませるのです。今の人はカードなんか見たことないですよね。筆者が始めた頃は既にジョブの投入を端末から行うようになっていたのですが、カードパンチャーやカードリーダはまだ残っていて、使おうと思えば使えるようになっていました。プログラムの出力は、大体ラインプリンタに出力するようになっていました。ジョブを投入した後、まじめな人なら別の仕事をするところでしょうが、結果出るまで、ちょっとコーヒーブレイクというのが典型的な行動パターンだったと言えるでしょう。
TSSの方は、対話的にコンピュータとやりとりする形態です。端末からコマンドを入力すると、端末に何か出力されるといった具合です。バッチとTSSのどちらか一方の形態しか使えないということはなくて、両方の形態を同時に使用可能です。バッチとTSSの使用割合がどうなっているのか統計情報が出てきたりしていましたが、OSの制御がどうなっていたのかは、よく分かりません。
筆者のOS屋としてのキャリアは、メインフレームにUNIXを載せようという、まだ始まったばかりのプロジェクトに配属されたときから始まっていて、以降、ずっとUNIX畑を歩いてきたので、メインフレーム純正OSの方は、ユーザとして数年使った経験があるだけで、中身の方は分かりません。メインフレームOSのコードは、ガチでプロプラで、普通の人は見る機会がないものなので、それを見ることができなかった*3のは、非常に残念ではありますが、メインフレームOSの方は当時既に保守主体となっており、UNIXの方は、規模も小さく*4、全体が把握できた上に、移植とは言え、一から自分たちで作っている感があって、UNIXプロジェクトに配属されたことは、非常にラッキーだったと思っていました。そんなわけで、本ブログは、UNIX系OSを前提とした話になってしまいますが、ご了承ください。
UNIXは、TSSを前提としています。端末からコマンドを入力して、端末からその応答を得るというのが基本的な使い方ですね。それを実現しているのは、実はシェルという(OSではなく)アプリケーションプログラムなのですが、UNIXという(実行環境も含めた広義の)OSとしては、シェルの使用を前提としています。シェルスクリプト(あるいは単にコマンド)をバックグラウンドで実行することで、バッチ的なことも出来るとは言えます。ただ、OS内部のプロセスの扱いとしては違いはありません。UNIX系OSは、スパコンの世界でも結構使用されることが多かったです*5が、そこではバッチ的な使用が合っていそうです。ジョブという言葉も結構使われている気がします。シェルによる対話的使用ではなく(あるいはそれに加え)、ジョブスケジューラと呼ばれるアプリを導入して、ジョブの投入を行うといったことをしていたりします。
TSSの真髄は、多くのユーザがあたかも自分だけがコンピュータを使っているように錯覚させるというところにあります。誰か(別の人でも自分でも)が、時間が掛かるプロセスを実行していると、端末の応答が帰ってこない、というような状況だと使い物になりません。それを防ぐため、タイムスライスと呼ばれる短い時間が定められていて、その時間ごとにプロセスを切り替えるということを行っています。貴重なCPU時間を皆でシェアするので、タイムシェアリングシステムという訳ですね。タイムスライスは典型的には、ミリ秒のオーダをイメージしておけば良いかと思います。
TSSの実現には、タイマー割り込みを使用します。どんなコンピュータにも指定した時間後に割り込みを発生させることができるタイマーというものがあります。OSの典型的な実装としては、定期的に割り込みを発生させ、時限的な処理を行うようなことをしています。タイマー割り込み発生時、もし、割り込まれたプロセスが、タイムスライスを超えて実行を継続していたら、割り込み処理完了後、別のプロセスに切り替えればよいことになります。図にすると、以下のようなイメージです。
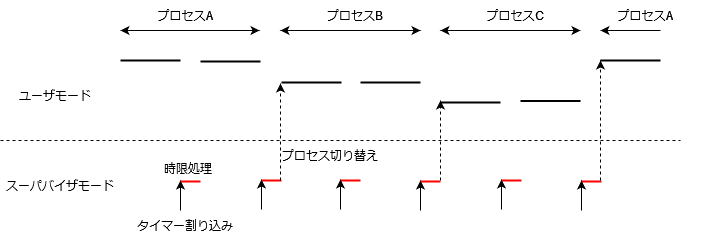
上の図では、3つのプロセスがタイムスライスごとに切り替わる様子を示しています。対話的なプロセスでは、タイムスライスが切れる前にI/O待ちで他プロセスに切り替わるケースが多いでしょう。CPUを消費するプロセスがバックグラウンドで実行されていても、タイムスライスごとに切り替わることにより、対話的なプロセスの応答性が確保されることが期待できます。
スケジューラ
ここまでのところで、OSのプロセス管理と呼ばれる分野の基本要素がいくつか見えてきたと思います。まず、プロセスの状態(state)を管理する必要があって、少なくとも、「実行可能」なのか、何らかのイベントが発生しないと実行できない、「待ち」なのかの区別が必要ですし、それに加え、まさに今CPUで「実行中」という3つの状態を持つことが分かります。そして、実行可能なプロセスの中から、どれを実行するか選ぶ必要があって、それを行うのがスケジューラ*6ということになります。待ち状態のプロセスは、イベントが発生したら、実行可能状態に移行すればよいことになります。そのプロセスがイベント発生後、すぐに実行されるかどうかは、スケジューラ次第です。
プロセスに優先度という属性を付けて、優先度の高いものを選択するというのが、典型的な実装になります。優先度をどう付けるかがポイントとなりますが、すぐに思いつくのが、CPUをたくさん使っているプロセスの優先度を下げて、CPUをあまり使っていないプロセスの優先度を上げるというものです。対話的なプロセスの方が使用するCPU時間が少なく、応答性が高い方が望ましいので、こんな単純な方法でも結構いい感じになるかと思います。筆者が最初に見たUNIXコードでは、1秒ごとにタイマー割り込みを発生させ、全プロセスの優先度を計算し直すということをしていました。そんなのんびりでいいんかい、と思わず突っ込んだ記憶があります。優先度計算のアルゴリズムなど詳しいことは記憶にないのですが、突っ込んだ記憶だけは印象が強かったのか残っています。
スケジューラというものは、昔から議論が尽きないものです。コンピュータの使われ方がいろいろだというのも一因でしょう。Linuxを例に取ると、今や組み込みシステムからスパコンまで広範に使われていますもんね。リアルタイムな応答性を要するケース、例えば、外部装置からの信号に短い時間で処理、応答が必要なケースに関しては、リアルタイムクラスという絶対的な優先度が高いスケジューラクラスが用意されています*7。通常のプロセス実行中にリアルタイムクラスの優先度を持つプロセスが実行可能になった場合、即座にプロセス切り替えが実行されるというような制御が行われます。こうした特殊なケースにはそれなりの手段が用意されているので良いとして、個人的な使用に関しては、あまり凝ったアルゴリズムにする必要はないので、実際のところ議論になるのは、大規模なシステム向けということになります。
Linuxでは長らくCFS(Completely Fair Scheduler)スケジューラがデフォルトでした。複数のプロセスが実行している場合、各プロセスに割り当てるCPU時間を均等にしようというのがコンセプトのようです。カーネルのドキュメント*8によるとデスクトップ向けと書いてありますね。大規模向けではないと予防線を張ってるのかな。それはさておき、大規模向けになると、何をゴール(優先事項)にするかが様々であり、そこも議論を招くポイントである気がしています。CFSの場合、均等になるのはプロセス単位なので、ユーザ単位で見ると、沢山プロセスを実行しているユーザが得なような気がしますよね。それに関しては、課金することにより、ユーザ自身の自制に期待したり、ユーザごとにクォータを設定したりと、別のメカニズムに委ねることも考えられます。課金といえば、高いグレードの課金ユーザのプロセスを優先するというポリシーも考えられると思います。その場合のゴールとしては課金収入の最大化になるでしょう(実際にあるかどうか分かりませんが)。最近は、消費電力というステークホルダーも出現してしまっているようです。
最近は、コンピュータシステムも複雑化していて、考慮する要素が多く大変です。プロセッサも複数になってきて、どのプロセッサでプロセスを実行するかも考えないといけません。メモリ、ネットワーク、アクセラレータ等の割り当ても考える必要があって、プロセスのスループット最大をゴールにするにしても消費電力最小をゴールにするにしても、そのゴールを満たすための各種リソース配分(CPUも含む)を考えないといけません。その上にリソース隔離機能(例えば、Linuxでは、cgroups)の考慮も必要ということで、もう訳が分かりませんね。
実は筆者はスケジューラにはあまり興味を持っていません。これでスケジューラの話は、お終いです。ただ、一点最後に大事なことを言っておきますが、スケジューラは、プロセスの選択に時間を掛けてはいけないということです。そもそも、CPUを効率的に使用することが目的なのですから、スケジューラがCPUを浪費してしまっては本末転倒です。
課金
筆者がOS屋になった当時、メインフレームのUNIXというのは、大学の計算機センターで使用されることが多かったです。VMのひとつにUNIXを載せ、教育用に開放するといった感じですね。本格的な計算は依然メインフレーム純正OSのVMで実行されていて、メインフレームのVM管理機能を利用して、UNIXから純正OSにジョブを投入したり、ジョブの結果を取得したりする機能を開発していたりしました。
大学の計算機センターでの使用には、課金が付き物でした。当時のUNIXでは、課金情報が秒単位になっていたため、さすがに解像度が悪すぎて使い物にならないとの声が上がっており、ミリ秒単位の課金情報を出す、高精度課金なる機能開発があったりしました。現在のLinuxはマイクロ秒単位のようですね。カーネル内部ではもっと細かい精度で保持していると思います。
プロセスが消費したCPU時間は、課金に使われたり、スケジューラの判断に使われたりするわけですが、その計測は一筋縄ではいきません。消費したCPU時間は、ユーザモードでの使用とスーパバイザモードでの使用に分けて計測されています。ユーザモードで使用したCPU時間に関しては、はっきりそのプロセスが使用したものなので議論の余地はありません。問題は、スーパバイザモードでの消費時間です。スーパバイザモードの消費時間というのは、そのプロセスが発行したシステムコールのコンテキストで実行された時間を計測しています。システムコールというのは、そのプロセスがやりたいこと(例えば、ファイルアクセス)をOSが肩代わりして行っている訳なので、そのプロセスの消費時間として計上するのは自然です。ではありますが、他プロセスやシステムの状況により、結構ぶれが出てきます。例えば、メモリの使用状況によっては、メモリ不足によるページ解放処理(結構重い処理)がシステムコールコンテキストで走る場合があります。筆者の知る限り、その処理分を計上から差っ引くなどということはやっていなかったと思います。ファイルアクセス時にディスクキャッシュ(ページキャッシュ)にデータがあるかどうかでも違いが出てきます。データがキャッシュになかった場合、ディスクに対するI/Oを発行するまでが、システムコールコンテキストで実行されることになります。こうしたOSのオーバヘッド分をプロセスに付けてしまっていいかという問題ですね。逆の話もあります。Linuxの話になりますが、ネットワークI/Oに関しては、送信については、システムコールコンテキストで実行されますが、受信に関しては、NICで受信して、ソケットバッファに届くまでは、割り込みコンテキスト(およびsoftirqコンテキスト)で行われるので、プロセスには計上されていません。ソケットが分かった時点で、そのソケットを使用しているプロセスに付けてしまえ、とかは筆者の知る限りはやっていなかったはずです。割り込み処理では、複数のパケットを処理するケースがあって、個々のパケットごとに計上するのは難しそうですし、マルチキャストパケットだったらどうプロセスに付けるんだとか考え出すと難しそうです。とは言え、じゃんじゃん受信しているプロセスにCPU時間が計上されていないのは、なんだか不公平な気もしますよね。クラウド事業者はどうしているのでしょうね。VM単位の課金だとして、VMに割り振れない物理ホストでのオーバヘッド分が大きいと損する気がしますが、どうしているのか気になります。
と、つらつらと書きましたが、各種コンテキストに対し、正確な計測が出来ていることが前提となります。昔のLinuxは、タイマー割り込み時にsoftirq実行中だったら、softirq処理にtick分計上すると言った乱暴な計測が行われていて、あきれた覚えがあります。最近、Linuxの実装には疎くなってしまっているのですが、今は正確に計測されていると信じたいです。
昔は、OSの大事な資質として、オーバヘッドが少ないことが挙げられていました。OSはあくまでも黒子で、極力アプリケーションにCPUが割り当たることが望ましいということですね。今は、高機能化の方向に進み過ぎていて、オーバヘッドなんて重要視されていないのかしらと不安になってしまいますが、それはさておき、オーバヘッドが評価できるよう、どんな処理にどれだけのCPU時間を使っているか、きちんと計測することは大事だと思います。Linuxもそうですが、伝統的にUNIX系は、そのあたり弱い気がします。改善されることを期待しています。
あとがき
徒然と書き連ねていたら、結構な量になってしまたので、今回はここまでです。マルチプロセスの話題がもう少し続く予定です。ではまた次回。