執筆者 : 小田 逸郎
※ 「OS徒然草」連載記事一覧はこちら
はじめに
筆者は自分のことを OS 開発者 (OS屋) だと思ってます。最近は、OSにあまり深く関われていないのですが、筆者が若かりし頃に情熱を注いだものであり、筆者の基盤をなしているものであることには間違いないです。
筆者が OS (UNIX) の開発に携わり始めたのは、1986年のことなので、もう40年近く経ってしまいました。その間に OS の規模も随分大きくなってしまったようです。
筆者が始めた頃の UNIX は、デバイスドライバを除くと、20K行くらいだったと記憶しています。
全コードをラインプリンタで出力、コピー、製本し、皆で読み合わせて、勉強会をしたりしていました。そんなことができる分量だったのです。
今の Linux の規模はどれくらいでしょうか。筆者たちが「Linuxカーネル 2.6解読室」を連載していた頃 (20年くらい前) で、2M行以上 (※) あったようです。
う、当時もそんなにあったのか。
で、現時点最新の 6.9 では、8M行以上 (※) にもなるようです。かつての UNIX の 400倍以上!!
(※) デバイスドライバを除いています。また、arch は、x86系に限定しています。Linux 全体から見るとそれでもかなり小さいです。
こうなるともうコードを全部読むのは不可能 (ではないにしても、少なくともやる気にはなれない) ですし、そもそもどこから手を付けたら良いのか、分からないですね。
と言っていたら、弊社の若手達が「新Linuxカーネル解読室」 プロジェクトという無謀な挑戦を始めてしまいました。素直に賞賛を送るとともに、筆者もできるだけフォローしていきたいと思います。
解読室の方は、Linuxカーネルを読み解く上で大変参考になるかと思いますが、それでも背景となる知識がないと、中々理解するのは難しいのではないかと思います。
本ブログでは、OS がどんなものであるかを理解するための背景となる知識だとか、勉強の参考になる情報だとかをお話ししていこうと思っています。調べものというより雑談に近いものですので、「OS徒然草」と名付けてみました。気楽に読んで頂ければ良いかと思います。その上で、何らかの参考になれば幸いです。
コンピュータのアーキテクチャ
筆者も最初から OS屋だったわけではなく、最初は単なるユーザとして、OS を意識することなくコンピュータを使用していました。そのうちに、コンピュータの中では OS というソフトウェアが動いていて、OS がないとコンピュータが使えないのだと知って、俄然 OS に興味を持ったのがOS屋になったきっかけです。
OS に興味を持つのは、コンピュータをどう使うかということよりもコンピュータがどう動いているかに興味を持つ人種 (仕組み知りたがりクラスタ) と言えるでしょう。ちなみに、そのクラスタの中でも、ハード屋とソフト屋に分かれ、ソフト屋の中でも、OS屋と言語 (処理系) 屋に分かれる、と昔、知り合いが言っていました。
OS が取り扱うコンピュータとはどんなものでしょうか。コンピュータの構成は、以下の図に示すようなものとなります。
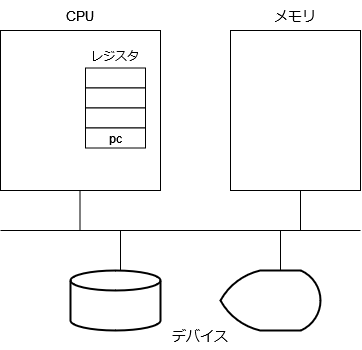
主役は、CPU ですが、これは、メモリに格納されたバイト列を CPU に与えられた命令だと解釈して、その命令を実行するようになっている電子回路です。
プログラムカウンタ (pc) と呼ばれる、実行すべきメモリ番地を格納する特殊なレジスタが存在して、CPU は、そのメモリ番地に格納された命令を実行するようになっています。
CPU にできること、すなわち用意されている命令は、基本的には以下に示すものです。以降、本ブログでは「基本命令セット」と呼びます。
基本命令セット:
- ロード、ストア
メモリからレジスタにデータを格納したり、レジスタからメモリにデータを格納したりする。 - 演算
レジスタの内容とレジスタの内容を演算した結果をレジスタに格納する。 - ジャンプ
次に実行する命令のアドレスを変更する。pc は、前記命令実行時は、自動的に次の命令を指すように変更されますが、ジャンプは明示的に pc を変更する命令と言えます。
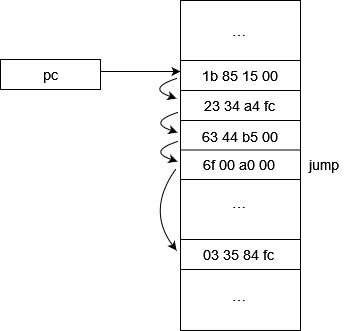
実際のところ、こんなに単純ではないですが、大体物事は正確に説明しようとすればするほど、却って分かりにくくなってしまうもので、適度な抽象化が必要です。これは、筆者の理解に基づき抽象化したものになります。当面、本ブログを読み進める上ではこれで十分です。
それは、それとして、OS屋たるもの、正確な仕様は、きちんと把握しておく必要があります。
CPU で実行できる命令一式を定義したものを ISA (instruction set architechture、単にアーキテクチャ) と言いますが、そのアーキテクチャごとに仕様書があるはずです。
例えば、筆者がこれまでの仕事で取り扱うことが多かった x86系としては、以下のものがあります。
参考:
- Intel® 64 and IA-32 Architectures Software Developer Manuals
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html 参照。
分冊や合本 (5000ページ以上!!) のPDFが取得できます。
表題に「Software Developer Manuals」とあるようにこれは、ハード屋がソフト屋に向けて、ハードウェアのインターフェースを記述した仕様書と言う位置づけになります。
それにしても5000ページですか (絶句)、これもなんか昔に比べて随分増えましたね。さすがにこれは全部把握するのは難しそうに思います。
前言を「OS屋たるもの、仕様書を手元に置いて、適宜参照できるようにしておく必要があります」にちょっと変更させてください。(とは言え、パラパラと見てみたところ、OS 作るためには、かなりの部分を読む必要がありそうです。)
これはちょっと量が多すぎるので、別のアーキテクチャを参照しましょう。x86 以外にメジャーな物としては、arm になるかもしれませんが、ここでは、今話題が増えている RISC-V を選択してみます。RISC-V の仕様書は、以下のものとなります。
参考:https://riscv.org/technical/specifications/
- Volume 1, Unprivileged Specification version 20191213
https://github.com/riscv/riscv-isa-manual/releases/tag/Ratified-IMAFDQC - Volume 2, Privileged Specification version 20211203
https://github.com/riscv/riscv-isa-manual/releases/tag/Priv-v1.12
(2冊で400ページ程度)
このくらいが適当ですよね。弊社の別の記事「RISC-V OSを作ろう」でも取り扱っていますし、筆者も本ブログを書くついでに RISC-V の勉強をしようかと思います。本ブログでも何か例を出すときは、RISC-V を参照することにします。
Linux のコードでは、arch というディレクトリの下にアーキテクチャ固有部分が分離しています。
Linux の大半はアーキテクチャに依存しない部分ではありますが、各アーキテクチャに共通な部分が抽出され、抽象化されている部分も多い訳なので、具体的なアーキテクチャについてもひとつは押さえておいた方が良いかと思います。
x86 は複雑すぎるので、RISC-V あたりを参照しておくのも良いかもしれません。
ところで、アーキテクチャによって、バイトの並び順の流儀が異なっていて、リトルエンディアンとビッグエンディアンという 2つの流儀があります。リトルの方は、アドレスの小さい方が低位バイトになるような順で、ビッグはその逆です。x86 がリトルエンディアンのため、最近はすっかり、リトルエンディアンを取り扱うことが多くなりましたが、個人的には、ビッグエンディアンが好みです。元々、最初に関わったアーキテクチャ (S360) がビッグエンディアンだったこともありますが、16進ダンプを見たときに分かり易い並びになるというのがその理由です。
例えば、4バイト整数 0xabcd0123 (10進で2,882,339,107) をダンプで見ると以下のようになります。
リトルエンディアン ビッグエンディアン 0000: 23 01 cd ab 0000: ab cd 01 23
sparc もビッグエンディアンだったと思います。TCP/IP でプロトコルをやりとりする際のネットワークバイトオーダーもビッグエンディアンです。
x86でプログラミングしていると、htons とかを忘れて、あれれ、となった経験がある方も多いかと思います。
struct sockaddr_in sin; sin.sin_family = AF_INET; sin.sin_port = htons(APP_PORT); ← ここ
最近は、どちらにもできるアーキテクチャもあるようで、RISC-V もそのようです。ところで、前記の RISC-V の仕様書に以下の記述がありました。
volume 1 の1.5:
We originally chose little-endian byte ordering for the RISC-V memory system because little- endian systems are currently dominant commercially (all x86 systems; iOS, Android, and Win- dows for ARM). A minor point is that we have also found little-endian memory systems to be more natural for hardware designers. However, certain application areas, such as IP networking, operate on big-endian data structures, and certain legacy code bases have been built assuming big-endian processors, so we have defined big-endian and bi-endian variants of RISC-V.
ふむ、筆者はソフト屋なので分かりませんが、ハード屋には、リトルエンディアンが自然なのですか。
ビッグエンディアンがマイナーなのは、ちょっと悲しいですが、実際のところ、どちらでもいい話なので、だからこそ、どちらかに統一されている方が幸せだったのにと思います。ハードにとっては余分な回路が必要ないし、ソフトにとっても無駄な変換が必要ないですからね。
もうひとつどうでもいい話をすると、メモリの図を書くのに、低位アドレス (ex. 0番地) を上にする流儀と下にする流儀があるようです。
「スタックは下から上に伸びます」というような表現をしたとき、イメージする上下関係の認識が合っていないと困りますので、どうでも良いわけではなかったかもしれません。筆者は、低位アドレスが上派です。ダンプを見たときとか構造体の図を書いたときとかを考えると低位アドレスが上の方が自然ですから。本ブログでも当然のように低位アドレスを上とします。
閑話休題。
プログラムの構造
OS と C言語は切っても切れない関係にあります。OS 自身が C言語で書かれているということもありますが、OS で取り扱うプログラムは、C言語で生成したものであることを前提としていると思われる節があるためです。
C言語が発明される前は、OS はアセンブラかそれに近い言語で書かれていました。アセンブラで書くのと C言語で書くのでは、生産性が雲泥の差です。筆者は、C言語の特長(存在価値)は、アセンブラの効率化であると捉えています。
C言語は、システムユーティリティ (sh、ls、cat のような基本的なコマンドやら、cc、yacc などの言語系等々) を書くのにも使われています。
元々、当時の言語事情としては、実用的なプログラミング言語としては、事務計算が COBOL、技術計算が FORTRAN で、他はない (なお、本物のプログラマは pascal を使わなかった *1
) という状況だったので、C言語を使うというのは自然ではあるのですが、今となっては、全然、C言語を使う必然性はないと思っています。大半のユーティリティは、Python や Ruby のようなスクリプト言語で十分だと思いますし、多少性能を気にするのであれば、Go言語で良いのではないかと思います。その方が、C言語で書くより、ずっと簡潔で読みやすく書けますから。
筆者が C言語を始めた頃は、K&R で勉強した (そもそも、それしか本が出てなかった) のですが、その後、C言語の仕様もどんどん大きくなってしまいました。正直言って、最近の仕様は、把握していないです。今となっては、制御系の特殊なプログラムしかC言語を使う必然性はないと思うので、あまり仕様をリッチにする必要はないんじゃないかと思っています。
ところで、世の中は、いろいろなプログラミング言語で溢れかえっています。命令型、関数型、オブジェクト指向など、いろいろな流儀があるようです。どんなプログラミング言語を使用したとしても、結局のところ、コンピュータで実行されるのは基本命令セット列でしかありません。筆者は、いつもプログラミング言語仕様と基本命令セットのギャップに戸惑ってしまっています。 (その点、C言語はギャップが小さいと言えます。)
プログラミング言語は、コンピュータにやることを指示する言語のように言われることもあるようですが、実際は、人間同士でやりたいことの意図を伝えるための言語である側面が強い気がします。人間、考え方も人それぞれですので、コンピュータ言語が溢れかえる結果になっているのでしょう。
それはそうと、筆者のこれまでの経験から見るところ、世の中の OSS の大半は、クソな他人に理解して貰う努力をしていないコードではないか、との印象を受けています。最近は、生成AI というのが大流行で、プログラミングの支援を行ってくれるものもあるようですが、世の中の OSS で学習しているとすると、それで大丈夫なのかとちょっと不安になります。
閑話休題。
C言語で生成したプログラムのメモリ上のレイアウトは、以下のようになります。
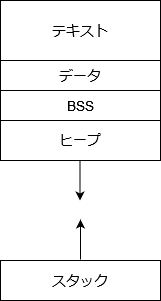
- テキスト
命令列が配置された領域。 - データ
初期値付きデータ。外部変数、static変数で初期値付きのデータが配置された領域。 - BSS
初期値なしデータ。外部変数、static変数で初期値なしのデータが配置された領域。なお、プログラムのロード時、データは、OS により、0クリアされることが保証されている。 - ヒープ
動的に確保されるデータ。mallocで確保したデータはこの領域に配置されている。プログラム実行中に動的に拡張され得る。 - スタック
関数のローカル変数や退避するレジスタの値を格納する領域。関数呼び出しのネストが深くなるごとに拡張される。
C言語では、プログラムは関数という単位で構成されており、関数呼び出しにより、プログラムが実行されていくわけですが、関数の実行にスタックという構造を使用しています。
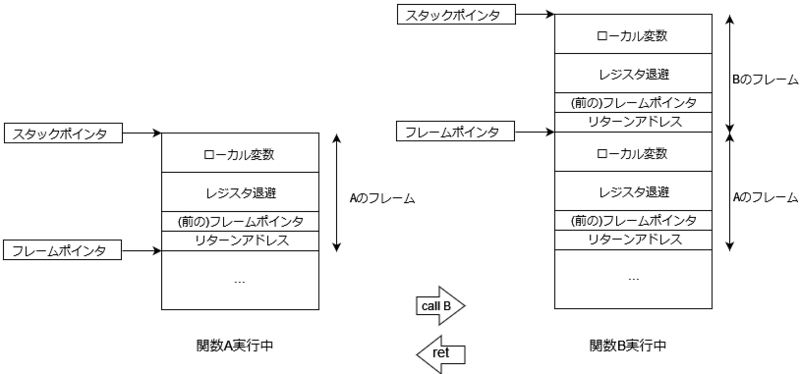
上の図はスタックの構造の一例ですが、関数A から関数B を呼び出した場合のスタックの変化を示しています。左が関数A の実行中 (関数B の呼び出し前、および復帰後) を示し、右が関数Bの実行中の状態を示しています。関数B の冒頭で、スタックの伸長、レジスタの退避などが実行され、復帰直前にレジスタの復元、スタックの縮退が実行されます。
関数を呼び出す際の決まり事があって、コーリングコンベンションと言っています。
コーリングコンベンションは、ABI (Application Binary Interface) と呼ばれるものの一部で、ABI は、各アーキテクチャごとに仕様書があるはずです (ないと、OS やコンパイラが作れないので)。レジスタの使い方だとか、引数の渡し方だとか、関数の開始、復帰時にやらないといけない事項だとかが書かれています。
RISC-V であれば、以下のドキュメントがそれに当たります。
参考:
- RISC-V ABIs Specification
https://d3s.mff.cuni.cz/files/teaching/nswi200/202324/doc/riscv-abi.pdf
OS の開発では、アセンブラで書かざるを得ない場合もあります。
C言語だけで開発している分には、先ほどの図の説明で書いた事項はコンパイラが自動的にやってくれるので、あまり意識する必要はないですが、アセンブラで書く際には、コーリングコンベンションを意識して、それに従って自分で書く必要があります。 (何をしなければいけないかは、仕様書読むより、実際に実際にコンパイラが吐き出したアセンブルコードを参照した方が分かり易いかもしれません。)
原理的には、ABI に従わないプログラムを書いたり、そうしたプログラミング言語を作ったりすることはできると思いますが、実際のところ、libc をリンクせずに済ますことは難しいですし、プログラミング言語によっては、C言語で書いたプログラムを呼び出すことが可能になっていたりと、ABI を意識 (遵守) しているはずです。
参考までにプログラムのファイル上の形式についても紹介しておきます。プログラムのファイル上の形式は、ELF (Executable and Linking Format) という規約に従っています。実行形式だけでなく、動的ライブラリであるとかコアダンプも ELF形式に従っています。
参考:
- SYSTEM V APPLICATION BINARY INTERFACE
https://www.sco.com/developers/devspecs/gabi41.pdf - System V Application Binary Interface - DRAFT - 10 June 2013
https://www.sco.com/developers/gabi/latest/contents.html
オリジナルは、UNIX System V なんですね。これは、筆者が最も働き盛りだったときに扱っていた OS なので、中々感慨深いものがあります。
今では、ELFは、Linux だけでなく他の OS でも広く採用されています。なお、形式が ELF だというだけで、その内容 (ABI) については、各 OS、各アーキテクチャで異なります。
ファイル上のプログラムをメモリ上に格納することも OS の役割なので、OS屋も当然把握が必要です。
とは言え、あまり深入りするつもりはないです。かなり仕様が複雑ですしね。このあたりは、言語屋の方が関係性が深いと言えます。 (仕組み知りたがりクラスタが好きそうな話題ではあります。バイナリクラスタと呼ばれる一派が存在していそうです。)
もうひとつ参考情報ですが、ELF の一セクションとして格納されるデバック情報の規格として、DWARF (Debugging With Arbitrary Record Formats) *2 というものがあります。
DWARFの仕様については、以下を参照。
参考:
- DWARF Version 5
https://dwarfstd.org/dwarf5std.html
ページ数多いな。これもオリジナルは、UNIX System V です。
こちらも、ダンプやコアの解析時にお世話になります。 (と言っても、DWARF セクションの解釈は gdb がやってくれるので、意識することは少ないとは思いますが。)
あとがき
結構な分量になったので、今回はここまでとします。OS を理解するための前提知識の話だけで終わってしまいました。次回からは、OS の話もしていきたいと思います。それではまた次回。
*1:参考:
http://www.pbm.com/~lindahl/real.programmers.html
https://dajya-ranger.com/software/real-programmers-dont-use-pascal/
今はなき「bit」、私も読んでました。参照されているbitの記事はリアルで読みました。
*2:ELFに掛けて名付けたみたいです(RPGゲームとかで良く出てくる種族)。