執筆者 : 小田 逸郎
※ 「OS徒然草」連載記事一覧はこちら
マルチプロセッサ
遂にマルチプロセッサ(MP)に触れるときが来てしまいました。これまでの内容は、CPUの数とは関係なく成り立つ話でした。元々、昔はユニプロセッサ(UP)しかなかった訳ですし、UPでもMPでもOSとしてやるべきことはあまり変わりありません。今回は、MPならではのお話です。MPというのは、OSのコードの複雑化や肥大化を招いた元凶のひとつで、主役級と言ってよいかと思います。今や、MPが当たり前、ラズパイすらもMPですから、避けては通れません。
コンピュータの構成(改)
初回に示したコンピュータの構成要素の図を更新するときが来ました。
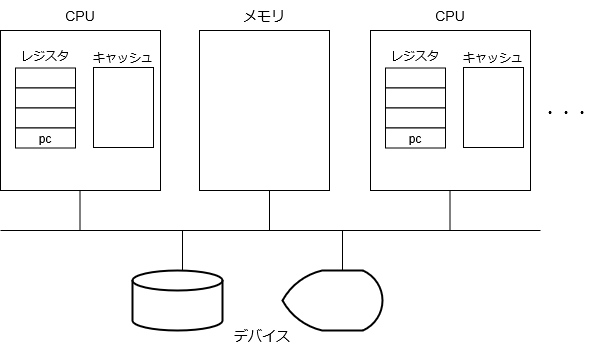
CPUが増えました。各CPUは基本的に同等で、メモリやデバイスを共有します。このようなシステムを正確には、SMP(Symmetric Multi Processor)と言いますが、最近は、MPと言えばSMPしかないので、単にMPと呼ぶことにします*1。各CPUでメモリを共有しているため、CPU間のデータのやり取りが非常に便利である一方、共有しているが故に発生するやっかいな問題もあります。CPU内にキャッシュという構成要素を追加しています。
少し補足しておきます。最近は、ハードウェアも複雑化してきており、ハードウェアの構成を正確に書こうとすると、却って分かりづらくなってしまうので、筆者がとりあえずこうモデル化しておけば十分と考えているレベルで単純化しています。ここでのCPUとは、OSが論理的にスレッドをスケジューリングする対象として認識するもので、物理的には、プロセッサ、コア、ハイパースレッディング等であったりと違いがありますが、ここでは全てプロセッサ*2と呼んでいます。キャッシュは、UPにも存在していたのですが、ソフトウェア(含OS)から意識する必要がなかったため、無視していました。まあ、意識すると性能改善に繫がるという側面はありましたが、少なくとも処理結果に違いが出ることはありません。MPになると、より性能面を考慮する必要が出てきた上に、処理結果に違いが出ることもある(!?)ので否応なしに意識せざるを得なくなり、構成要素に追加しています。キャッシュにしてもハードウェア的な構成は非常に複雑で、CPUの中にあるのかという突っ込みもあるかもしれませんが、ここでは、CPUごとにキャッシュがあり、それを意識する必要があることを示すアイコンとして捉えてください。
OSレベルスレッド
以前の回*3でマルチスレッドの話をしました。そこでは、UPが前提であったため、マルチスレッドの目的は、CPUを遊ばせないようにするためであったり、プログラムの分かり易さのためであったりしました。MPになると、プロセスを動作させられるCPUが複数になるので、当然システム全体のスループット向上が期待できますが、それに加えて、マルチスレッドプログラムの各スレッドを別々のCPUで同時並行動作させて、そのプロセス単体で見たときの、処理時間を短縮したいと考えるのは自然なことです。プロセス自身では、動作させるCPUを制御することはできませんので、OSがなんらかのサポートしてあげる必要があります。
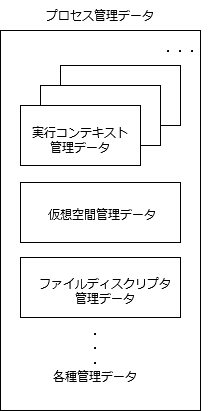
そんな訳で、MP対応を謳うOSでは、OSレベルスレッドを生成するシステムコールが存在しています。OSレベルスレッドというのは、OSがCPUをスケジュールする対象として認識するスレッドのことです。従来は、OSがCPUをスケジュールする対象は、プロセスでした。と言うのは、ひとつのプロセスにつき(OSの認識する)スレッドは、ひとつだったからです。それが、ひとつのプロセスにつき、(OSの認識する)スレッドを複数持つことができるようになり、OSがCPUをスケジュールする対象が、スレッドになったということです。プロセスの起動時*4は、main関数から始まるひとつのスレッド*5だけが存在している状態で、他のスレッドの生成はプロセス起動後に明示的に行います。複数のスレッドが存在していてもプロセスとしてはひとつであり、同じ仮想空間上で動作します。すなわち、全てのスレッドでメモリを共有します。また、動作時のプロセス属性、例えば、ファイルディスクリプタであるとか、実効ユーザ・グループとか、カレントディレクトリとかも共通となります。どれかのスレッドがこれらの属性を変更(例えば、ファイルのオープン・クローズ)すると、他のスレッドにも見えることになります。OSのプロセスを管理するデータ構造としては、従来のものから、実行コンテキストを管理する部分だけ、複数持てるようにしたと考えれば良いです。
スレッドのAPIと仕様に関しては、POSIXスレッド(pthread)が使われることが一般的でしょう。pthread_create(3)の内部でスレッド生成システムコールが使用されることになります。いっそのこと、pthread_createをシステムコールとして実装することも十分考えられます。以前、UPシステム上で、POSIXスレッドをユーザレベルで苦労して実装したという話をしましたが、OSレベルスレッドがあれば、実装が非常に楽だったと思います。と言うか、MPをサポートしていたら、OSレベルスレッドを実装する側に回っていたかもしれないので、それはそれで別の苦労があったでしょうね。
さて、上に示したプロセスを管理するデータ構造の図は、筆者がこう考えると分かり易いと思ってモデル化したもので、実際分かり易いと思っているのですが、Linuxのデータ構造は、ちょっと違っています。これから、Linuxの実装を調べようとしたときに、このモデルを念頭に置くと混乱させてしまうかもしれないので、Linuxの実装がどうなっているのか、補足資料に簡単ですが少し説明してあります。参考にしてください。
スピンロック
マルチスレッドプログラムでスレッドを別々のCPUで並列で動作させることにより、プログラムの処理時間を短縮できるようになりました。実のところ、スレッドよりもMPだということが本質で、複数の(シングルスレッド)プロセスを別々のCPUで動作させ、共有メモリを使用して連携しても同じことができますが、マルチスレッドプログラムにした方がプログラミングの手間が少ないと言えます。とは言え、実際に性能向上させるのはそれほど簡単ではありません。アムダールの法則というのをご存知でしょうか。性能向上は、並列化できる割合によるという話で、例えば、並列化できる部分がプログラム全体の2割しかなければ、その部分をいくらがんばって並列化しても、全体として2割以上の改善になることは決してない訳です。また、スレッドがまったく独立に動作できるのであれば良いですが、通常は、データのやり取りが発生します。共有メモリのアクセスには、非常に注意が必要です。以前(第5回)、競合状態の説明しましたが、そのときは、UP前提だったので、コンテキストの予期せぬ切り替えだけを気にしていれば良かったのですが、MPになると、正に複数のCPUから、同時に同じメモリ領域にアクセスするという状況を考慮する必要が出てくるのです。その際、クリティカルセクションを排他するなど対処が必要であり、スレッドのスムーズな実行が妨げられることになるため、その点も性能向上の阻害要因となります。
さて、苦労するのはマルチスレッドプログラムを作る人だけだろ、で済めば良かったのですが、そうは問屋が卸しません。そもそも、OSって、マルチスレッドプログラムじゃありませんか。MPになって、真っ先に苦労するのがOSだったのです。
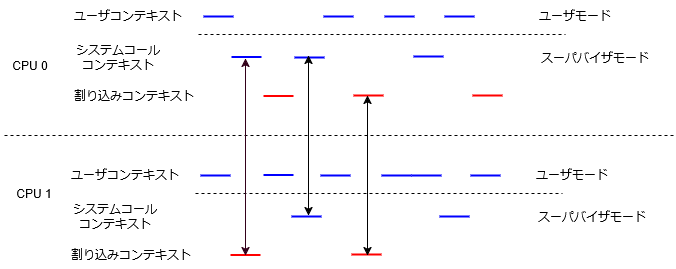
複数CPUでのコンテキスト切り替えの様子を図にしてみました(ユーザコンテキストでは、複数のプロセスのスレッドが動作しますが、図では区別していません)。OSは割り込みドリブンで動作するという話をしましたが、それは、全CPUで真です。プロセスがシステムコールを発行すると、そのプロセスが動作しているCPUでOSのシステムコール処理が動作します。デバイスの割り込みに関しては、割り込みが上がるCPUを指定できたりしますが、時限処理のためのローカルタイマ割り込みのように全CPUで割り込みが上がるものもあります。OSの動作する仮想空間はひとつで、OSのスレッド全てがメモリを共有することになります。図の矢印で示している箇所のように、OSの処理(システムコール、割り込み任意の組み合わせで)が同時に実行される可能性があります。それらのスレッドが同じリソースにアクセスすることは十分考えられることです。例えば、空きページの獲得処理はどのスレッドで実行されてもおかしくありません。その際、クリティカルセクションの競合を避けるためのなんらかの手段が必要になります。ユーザプログラムであれば、排他のためのシステムコールを発行して、OSに排他を任せることもできるのですが、OSは自力でなんとかしなければなりません。
共有メモリのアクセスの競合を防ぐために最も良く使われるのが、スピンロック(spin lock)です。スピンロックの概念コードを以下に示します。
int lock; // 共有メモリ上の変数
// ロック
loop:
if (lock == 0)
lock = 1;
else
goto loop;
// クリティカルセクション実行
// アンロック
lock = 0;
lock変数が0であれば、誰もクリティカルセクションに入っていないということで、lockを1にして(ロックして)、クリティカルセクションに入ります。lockが1であれば、誰かがクリティカルセクションに入っているということなので、lockが0になるまでループします。待っている方のCPUは、lockが0かどうか判定する命令を延々と実行するだけになり(この部分がスピンという言葉の由来です)、CPUの無駄使いをしていることになるので、クリティカルセクションの部分は極力短くなるようにする必要があります。
さて、鋭い人は既に気が付いていると思いますが、上記のコードには重大な問題があります。そもそも、共有メモリ上のlock変数のアクセス自体がクリティカルセクションじゃないんかいと。その通りです。ロックの部分をアセンブリ言語で書くと以下のようになります。(以下、RISC-Vの命令セットを使用しています。詳しい説明は省きますが、コード中のコメントで意味は通じると思います。)
# a0には、lock変数のアドレスが格納されているとする
# a1には、1が格納されているとする
loop:
(A) lw t0, (a0) # t0 に a0 アドレスの内容(lock変数の値)をロード
bnez t0, loop # 0でなければ、loopにジャンプ
(B) sw a1, (a0) # a1の内容をa0 アドレスにストア(lock = 1)
このコード自体は、UPの場合にも問題ありで、(A)と(B)の間にコンテキストスイッチでスレッドが切り替わるとまずいのですが、UPの場合は、割り込みを禁止することより、競合を防ぐことができました。MPでは、割り込みを禁止したところで問題の解決にはなりません。だって、別のCPUからアクセスされちゃう訳ですから。lock変数が0の状態で、(A)の部分が複数のCPUで同時に実行されるかもしれません。そうしたら、それぞれのCPUで同時にクリティカルセクションに入ってしまいます。
それではどうしたらいいんだということですが、どのアーキテクチャでも、こうした同時アクセスの問題に対処するための命令が存在しています。筆者には、「compare and swap」とか「test and set」*6という命令が馴染み深いのですが、RISC-Vでは、それはなくて、LR/SC(load reserved/store conditional)という命令が用意されていました*7。LR/SC命令を使用して、ロックの部分を書き直すと以下のようになります。
# a0には、lock変数のアドレスが格納されているとする
# a1には、1が格納されているとする
loop:
(A) lr.w t0, (a0) # t0 に a0 アドレスの内容(lock変数の値)をロード。後でのストアを予約。
bnez t0, loop # 0でなければ、loopにジャンプ
(B) sc.w t0, a1, (a0) # a1の内容をa0 アドレスにストア(lock = 1)を試みる。t0に成功したかどうか格納。
bnez t0, loop # ストアに失敗(t0 != 0)したら、loopにジャンプ。最初からやり直し。
# ストアに成功(t0 == 0)
前のコードと違うのは、(A)でLR命令を使っていて、これは単にロードするだけでなく、後で同じアドレスに(SCで)ストアするための何らかの情報*8を予約することと、(B)でSC命令でストアしていることです。正確にはストアを試みているということで、予約した情報に変更がなければ、ストアが成功し、変更があれば、ストアが失敗します。成功したかどうかはレジスタ(上のコードではt0)に格納してくれます(成功したら0、失敗したら非0)。予約が変更されたというのは、誰かが同じアドレスに対して、SC命令を実行したということを意味します(なお、(B)で成功しても失敗しても予約は変更されます)。本コードであれば、lockが0の状態で、複数のCPUで、同時に(A)が実行されたとしても、(B)が成功するのはその中のひとつだけと言うことになります。
これで、複数のCPUによる競合を防ぐためのスピンロックの実装の目途が付きました。気を付けないといけないのは、スピンロックというのは、あくまでもCPU間の競合を防ぐためのものだと言うことです。同一CPU上のスレッド間の競合防止には使えません。もしあるスレッドが(スピンロックによる)ロックを保持した状態で、別のスレッドに切り替わって、ロックを取ろうとしたら、永遠にスピンし続けるだけになってしまいます。スレッド間の競合防止には、依然割り込み禁止も必要で、スピンロックと適切に組み合わせて使用する必要があります。
MPの罠
MPになると、OS(だけでなくマルチスレッドプログラム)を陥れようとする罠がいろいろとあります。OSの敵はひとつだけはありません。敵のひとつがコンパイラです。コンパイラ屋はコンパイラ屋で性能向上のため、日々最適化を考えています。それは結構なのですが、C言語は元々並列動作を想定していなかったためでしょうか、メモリが複数のスレッドからアクセスされることは想定されずに最適化されてしまいます。以下の簡単な例を考えてみましょう。
# a, b は共有メモリ上の変数。初期値 0。 a = 2; b = 1;
CPU0 で上記コードが実行されたとして、CPU1から変数a, bを参照したとしましょう。CPU1からしたら当然「もし、b==1だったら、a==2だよね」と思いますよね(aがなんらかのデータ、bがデータが有効化どうかのフラグと考えれば、ありそうなシナリオでしょう)。ところが、上記のコードだけ見ると、aとbの代入順が逆でも問題はなさそうに思えますよね。実際、順序には意味がなくて、プログラマがたまたまその順でコーディングしただけだったなのかもしれません。コンパイラも順序に意味があることは認識できないので、この順序を逆にしてしまう可能性があります。実際に機械語に変換された命令列が「b=1; a=2」の順だったらどうなるでしょうか。CPU1からb==1を観測できたとしても、そのタイミング(a=2の実行直前)によっては、a==2とは限りません。これは意図したことではないので、コンパイラによる最適化を防ぐ必要があります。一例として、以下の対処を紹介します。
#define WRITE_ONCE(var, val) (*((volatile typeof(val) *)(&(var))) = (val)) WRITE_ONCE(a, 2); WRITE_ONCE(b, 1);
本例では、変数をvolatileであると示すことにより、最適化を防いでいます。すなわち、この文が省略されることがない、メモリから必ずアクセスされる、順序変更がされない(volatile同士なので)、ということが実現できます。
コンパイラによる最適化を免れ、意図した通りの命令列が生成されたとして、それで安心してはいけません。新たな敵、それも最強の敵が待ち受けています。それは、ハードウェアです。仮にCPU0で「a=2; b=1」の順で実行されたとしても、CPU1からその順で観測されるとは限らないのです。どうしてそうなるかは、キャッシュが関係していて、ハードウェアの実装を詳しく知らないと分からないです。一応ハードウェアの名誉のために言っておくとこれは、性能向上のためには仕方ないことで、そんなCPU間のメモリ順序保証を無条件にやろうとすると遅くなりすぎてしまいますからね。無条件では保証しませんが、順序保証が必要なマルチスレッドプログラムのために、そのための命令が用意されています。RISC-Vでは、fence命令というのが用意されています。本例では、「a = 2; fence命令; b = 1;」のように間にfence命令を挟めば、CPU1側からもその順序で見えるようになります。なお、我々は必ずしもハードウェアの実装の詳細を知る必要はありません。例えば、RISC-Vの仕様書には、「順序保証はされないので、順序保証したければ、fence命令を使え」と明記されています*9。ですので、それに従って粛々と対処するだけです。
ハード屋もハード屋で性能向上のため、日々うまいことしようと企んでいます。最近(そう最近でもないか)では、分岐予測、投機実行などなど、複雑なことをしていて、ようやるなと思います。そうした複雑な機能のせいで「Spectre」のような脆弱性を引き起こし、ソフトウェア(特にOS)が尻ぬぐい(回避処置)をする羽目になったりもしています。本来、ソフトウェア側からはハードウェアの内部実装は隠蔽されていて気にする必要はないはずなのですが、時々染み出してきて、実装を把握する必要があったりするのは困ったものです。
さて、今回紹介したMPの罠は、もう本当にエントリレベルの話です。本ブログはお話が主体なので難しい話は避けましたが、実際のところは、もう魔境と言ってよい状況です。本格的に勉強したい方向けに良い参考文書を紹介しておきます。
その(どの?)*10界隈では有名な文書で、「perfbook」というキーワードを出せば、「通」だと思われること請け合いでしょう。これを見れば、MPが如何に魔境であるか良く分かるかと思います。それにしても、よくこんな文書書くよなと感心してしまいます。偉そうに紹介してますが、筆者も全部は読めてません。だって、量多すぎますもん。結構雑文も多いところが英語の苦手な筆者にはきついものがありますし、内容もパズルを解くような根気が必要で、読み進めるのは結構大変です。まあ、筆者も通ぶりたかったということですね。ただ、参考になることは間違いないです。
あとがき
MPの話題まで来ると、もう大昔の話ではなく、筆者がLinuxと関わり始めた(弊社に入社した2003年)以降の話になってきました。それでも今となってはそこそこ昔ですかね。当時はまだLinuxのMP対応も非常に頼りない状況でしたが、現在までにかなりエンハンスされて来たと言えるでしょう。その間苦労した結果がperfbookにまとめられているとも言えます。筆者もあらためて勉強し直す必要を感じています。
さて、次回も筆者のLinux以降時代の話題となりますが、仮想化についてお話しする予定です。ではまた次回。
*1:Linuxでは、SMPという用語で扱われています。
*2:RISC-Vの仕様書では、「hart」と言う用語を使っています。ちなみにhartはソフトウェアエミュレータでも構いません。
*4:fork & exec 直後。
*5:mainスレッドと呼びます。
*6:それぞれ、詳しくは説明しません。ググってみてください。
*7:RISC-V 仕様書(一般編)「8.2 Load-Reserved/Store-Conditional Instructions」参照。
*8:正確なことは、RISC-Vの仕様書を読んでも、筆者にはあまり要領を得ませんでした。
*9:RISC-V仕様書(一般編)「Chapter 14 RVWMO Memory Consistency Model, Version 0.1」参照。
*10: kernelハッカー界隈ですかね。