執筆者 : 小田 逸郎
※ 「OS徒然草」連載記事一覧はこちら
ファイル管理
OSの大切な役割として、ハードウェアの資源を管理し、抽象化して分かりやすいインターフェースでユーザーに提供するというものがあります。その典型的な例がファイル管理と言えます。計算には入出力データが付き物で、それらのデータを二次記憶装置(典型的にはハードディスク)に格納することが多いでしょう。ユーザー自身が直接ディスクを操作してデータを格納しないといけないとなると、それは面倒過ぎます。ハードウェアの仕様書を読んで、操作方法を把握する必要がありますし、ハードウェアによって、操作方法が異なりますからね。ディスクのどこの領域を使うか考えるのも面倒ですし、複数のユーザーがいるとき、領域が被らないよう、調整する方法を考える必要があります。そんな心配をOSがすべて解消してくれる訳です。OSがファイルという形でデータおよびデータへのアクセス方法を抽象化して提供してくれるおかげで、ユーザーはディスク(等)への操作方法やどこに格納されているかを気にすることなく、データにアクセスできるのです。素晴らしいですね、OSは。
そんな訳で今回は、ファイル管理にまつわるお話です。ファイル管理というのは、OSの中でも結構上位のレイヤに位置するものです。初回にCPUアーキテクチャの仕様書を紹介して、OS屋たる者、それを読む必要があると書きましたが、それで、びびってしまった方もいるかもしれません。実はファイル管理は、それに反し、アーキテクチャに無依存であり、アーキテクチャの仕様書を読む必要がありません*1。OSは、いろいろな階層、いろいろなコンポーネントから成り立っている大きなシステムです。興味に応じて、まずは、アーキテクチャに関係ない部分から読んでみるというのも良いかと思います。OS屋の現場でも、コンポーネントごとに担当グループを分けて開発が進められていました。筆者は、ファイル管理を結構長く担当していたので、ファイル管理にはかなりの思い入れがあり、語れることも多いかと思います。
ファイル管理は、直接ユーザーとインターフェースを持つ部分なので、システムコールの数も多いです。試しにシステムコールの中でファイル管理に関するものの数を数えてみるとその多さに驚くことでしょう。OSの中では一大勢力であると言えます。また、ファイル管理はOSとしての特徴が良く表れる部分でもあります。ファイルは、単なるバイト列で、何の構造も持っておらず、中身の構造を決めるのはアプリケーションである。と言うのは、今となっては当たり前過ぎて何の不思議にも思わないかもしれませんが、UNIXが出始めた頃は、UNIXならではの仕様ということで喧伝されていたものです。メインフレームOSでは、レコードの形式を指定して、ファイルを作成するようになっていました。固定長レコードか可変長レコードか、固定長であれば、レコードサイズはどれだけか、ということを指定してファイルを作成し、OSのインターフェースとしては、レコード単位のアクセスをサポートするといった具合です。大昔は、OSがファイルの構造を意識する方が一般的だったのかもしれません。
どんな言語やライブラリを使うにせよ、ファイルにアクセスするときに行う一般的な作法というものがあると思います。大体は、まず、ファイルをオープンする必要があり、オープンすると、何らかのハンドルが返され、以降はそのハンドルを指定して操作を行うというようになっているのではないでしょうか。今では、すっかり一般的になったパターンですが、UNIX(のシステムコール)がその走りではないかと思います。ただし、openシステムコールの場合、返されるもの(ファイルディスクリプタと言います)は、単なる数字というなんとも素朴なものです。実はこの数字、元々は、OS内部の(プロセスのオープンファイルを管理するための)構造体配列のインデックスでした。なんだか、OS内部の実装がユーザーインターフェースにまで染み出して来てしまっていたのですが、それだけ、OSとユーザーの距離が近かったとも言えそうです。当初は、配列の数(すなわち、プロセスがオープンできるファイル数)は、たったの20(固定値)でした。流石にそれは、少なすぎるのではないかと、筆者でも思います。今は、スペース効率も考え、ある程度は固定長で最初から確保されるが、それ以上になると可変長で増加していくという作りになっているのではないかと思います。筆者なんかは、コードがシンプルになる設計を好むので、今はメモリの搭載量も増えたので、固定値のままで、50くらいに増やしておけばいいじゃん、となりそうです。ところが、最近は、いくらでもオープンできることをいいことに、数千とかそれ以上のファイルをオープンするプログラムもいるみたいです。いや、流石にそれは設計が間違っているのでは、と思いますけどね。
通常ファイルだけでなく、ブロックデバイス(主にディスク)やキャラクタデバイス(端末など)、そしてソケットなんかも統一的に扱えるというのもUNIXらしさのひとつですね。それにしても、最近は、eventfdとか、timerfdとか、筆者の知らない間に、いろいろと、ファイルディスクリプタで扱う(けど、まったくファイルじゃない)ものが出てきていて、なんだか節操がなさすぎではないでしょうか*2。これもファイルディスクリプタ数増加の一因となっているのかもしれません。
UNIXのファイル管理の特徴を一々挙げていては切りがありませんので、このくらいにしておきます。その他の特徴についても折を見て触れることはあるかと思います。
参照カウント
OSのコードを読んでいると、これは良くあるパターンだな、と思うことが出てきます。そのひとつが、get/putパターンです。なんらかの制御表を参照(・更新)のため獲得する(制御表へのポインタを得る)ときにget、参照を終了するときにputを行います。とここで思わず、制御表という用語を使ってしまいました。ところで、皆さんは、OSの中で何らかの資源を管理するためのテーブル(例えば、task構造体)のことを何と呼んでいますか。筆者が最初にいたOS開発の現場では、制御表と言っていました。多分これは、その現場(かなり大きな組織ではありましたが)ローカルな用語だと思います。ですので、転職後は、ローカルな用語故に通じないといけないと思い、使わないようにしてきたのですが、どうもそれに代わるピッタリした用語がなくて、今に至るまでモヤモヤとしていたのです。このブログで、いろいろ昔の話を書いてきて、筆者にとっては、制御表が一番しっくりくるな、ということに気が付きましたので、もう堂々と制御表という用語を使うことにします。
閑話休題。
さて、制御表には参照カウントというものが付き物で、実は、getはそれをインクリメントすること、putはそれをデクリメントすることが主な処理になります。ただし、getの場合、制御表がなければ、前処理として制御表の作成(参照カウントは0に初期化)が、putの場合、参照カウントが0になったら、後処理として、制御表の資源開放が行われることになります。制御表から別の制御表をポイントしている(制御表のメンバに別の制御表へのポインタがある)ことも良くあることです。その際は、別の制御表をgetで獲得することになります。当の制御表もまた別の制御表からポイントされるためにgetされたのかもしれません。制御表の参照カウントは、他の制御表から参照されている数だけインクリメントされていることになります。
OSで使用する制御表の種類は膨大な数になりますし、その参照関係も複雑です。制御表の獲得、解放を個々の制御表ごとのget/putで参照カウントだけ見て行うというのは、非常に単純な考え方で、なるほどなあ、と思ったものです。ただ、これには注意が必要で、getとputの数がちゃんと合っていることが肝要です。putの数が少ないと、メモリリークとか、必要な処理がキックされないとかの不具合に繋がります。putの数が多いのは、メモリ破壊のような重大な障害に繋がる非常に危険なことです。まあ、我々ベテランのOS屋は、そんなことは重々承知で、そうならないようコードを作るのですが、人だからどうしてもミスはありますし、コードの静的解析で、対応関係の正しさをチェックするというのも難しそうです。OSの開発において、これに代わるパターンは思いつかないのですが、普通のアプリケーションを開発する際には、避けたいな、というのが筆者の最近の考えです。資源の獲得、解放は、いつどこで行われるのか、明示的で対応がはっきりしているのが、読んで分かりやすく、バグの少ないコードになると思います。
さて、ファイル管理に話を戻すと、ファイルの管理構造にもリンクカウントという、参照カウントに類するものがあります。リンクカウントというのは、そのファイルをポイントするディレクトリエントリの数です。UNIXには、link(ハードリンク)というシステムコールがあって、複数のディレクトリエントリから同一のファイルをポイントすることができます。ファイルの作成は、creatシステムコールで行いますが、不思議なことにファイルを削除するというシステムコールはありません。あるのは、unlinkというディレクトリエントリを削除するシステムコールです。ディレクトリエントリの削除により、結果、リンクカウントが0になったら、ファイルが削除される(使用しているiノード、ブロックが解放される)という仕組みになっています。この話には、続きがあって、実際にOSがファイル削除を行うのは、リンクカウントが0になるだけでなく、そのファイルのiノードに対応する制御表(Linuxでは、inode構造体)の参照カウントが0になったときです。unlink時も制御表(iノード用)のget/putが行われ、putで参照カウントが0になったら、ファイル削除が行われるわけですが、このとき、そのファイルがオープンされていたら、putで参照カウントが0にならないので、ファイルの削除は行われません。ファイルの削除が行われるのは、ファイルがクローズされたときになります。
この仕様を悪用して、ファイルをcreat(作成かつオープン)後、直ちにunlinkして、他から絶対に参照されないようにするという、一時ファイルのテクニックがありました(今も使われているのか?)。これのせいで、ファイルシステムのブロック使用量が全ファイルのブロック使用量の合計と合わない、とか言い出す細かい人がいたりして、面倒なんですよね。今となっては、代替はいくらでも考えられるし、ハードリンクの必要性もない*3ので、筆者が今設計するのであれば、linkはなし、ファイルの削除するシステムコール(ex. deleteシステムコール)を作成し、オープン中のdeleteはエラー、というようなすっきりした仕様にしそうです。中々広まってしまったものは変えられないというのが面倒ですよね。
(他にも参照カウントの悪用例をgithubに載せました。ご参照ください。)
キャッシュ
世間一般の人は、キャッシュと聞けば、現金のことを思い浮かべるでしょうが、我々OS屋は当然、別のものが先に頭に思い浮かびます。OS屋でなくても、IT関係者であればそうかもしれませんね。実際に口に出すと、イントネーションが違うので、区別が付くと思いますが、世間一般の人に我々の会話を漏れ聞かれると、この人たちは、キャッシュのイントネーションが変な人達だね、と思われてしまうかもしれません。
さて、キャッシュはいろいろな階層に存在しますが、ここで話題にするのは、ディスクキャッシュです。ディスクキャッシュは、ファイル管理を語る上で外せない、大事な構成要素となります。ディスクには、ブロック単位*4でしか読み書きできないという特性があります。1バイト変更するにも、まずブロック全体をメモリに読み込み、1バイト変更した上で、ブロック全体を書き戻す必要があるのです。さらにディスクアクセスはメモリアクセスに比べて非常に遅いので、1度メモリに読み込んだブロックをすぐには捨てずに活用しようというのは、極めて自然な発想で、これがディスクキャッシュ(以降、文脈上明らかな場合は、単にキャッシュ)ということになります。同じブロック上のデータの読み込みであれば、キャッシュから読めば良いので、速いですし、同じブロック上のデータの書き出しであれば、いちいちディスクに書き戻すのではなく、ある程度溜めてから、一度で書き戻せば効率が良くなります。
今は、Linuxにせよ、UNIXにせよ、メモリ管理のプロセス空間管理層と統合されて、ページキャッシュという形で取り扱われていて、素朴な形のディスクキャッシュというものはありません*5。ただ、これからお話する内容では、特に区別する必要はないので、ディスクのブロックをキャッシュしたものという理解で十分です。
そんな訳で、ファイルのデータにアクセスするときは、OSの管理するキャッシュ経由となります。read時は、キャッシュがなければ、ディスクからの読み込みを待つ必要がありますが、キャッシュがあれば、キャッシュからプロセス空間のメモリにコピーするだけで復帰します。write時もキャッシュがない場合は、一旦、ディスクからの読み込みを待って、キャッシュが出来るのを待つ必要があります*6が、キャッシュがあれば、プロセス空間のメモリからキャッシュにコピーするだけで復帰します。キャッシュをディスクに書き出すのは折を見てということになりますが、どんなタイミングで書き出すのかは、詳細な実装の話になってしまうので、今は触れません。大事なのは、writeシステムコールが復帰しても、ディスクには反映されてないのを意識しておくことです。
標準入出力ライブラリ(stdio)を使用すると、キャッシュがもう一段階使用されます。プロセス空間内のメモリをキャッシュとして使用します(バッファと言った方が一般的かもしれません)。書く方の話をしますが、fwriteを実行しても、プロセス内のメモリに書いて終わりで、writeシステムコールすら実行されません。1バイトメモリに書くのは(まあ大体)1命令で済むけど、システムコールを実行すると(少なくとも)数百命令は実行されることになるので、1バイトごとにwriteシステムコールを実行していては、CPUの使用効率が非常に悪くなります。そうしたアクセスパターンは端末のアクセスもそうですし、テキストファイルを編集しているときなんかもそうですね。writeシステムコールが実行されるのは、端末であれば、改行を書き込んだときであったり、通常ファイルであれば、バッファが一杯になるとか、fflushが実行されたときになります。
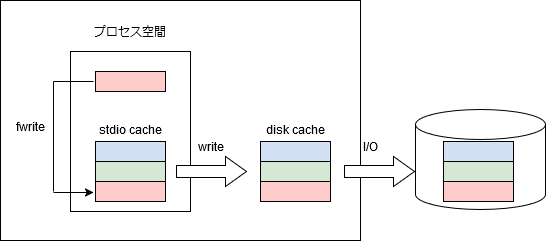
なるべくwriteを実行しないというのは効率は良いですが、その代わり、リスクもあって、ファイルにfwriteで書いても、プロセスが落ちてしまえば元も子もありません。さらにその上、プロセスが正常終了しても、OSが落ちてしまえば、ディスクには反映されていないかもしれません。普通のユーザーはあまり意識していないかもしれませんが、実は、2段階も心配事があったのですね。まあ、アプリケーション側で適宜、fsync*7を実行するなど、なんらかの対策はしていると思います。さて、標準入出力ライブラリのキャッシュは、OSから見ればアプリケーション側の話なので、今後の話は、OSの管理するキャッシュの話のみとなります。
信頼性
ディスクに書き出すのは、ファイルのデータだけではありません。ファイルシステムを管理するためのデータもあります。ファイルの構成を記録しているiノードや空きブロックを管理するためのデータなどです。管理データの書き出しには、なかなかデリケートな取り扱いが必要です。ファイルの操作による管理データの変更により、複数のディスクブロックの更新が必要となることは普通にあることです。一例として、ファイルのtrancateを行ったケースを取り上げると、iノードの更新(使用しているブロックの削除)と空きブロック管理データの更新(空きブロックに追加)が必要で、それぞれ別のブロックの更新が必要であることが考えられます。一方のブロックが書き出され、もう一方のブロックが書き出されないうちにOSが落ちてしまったケースを考えてみましょう。
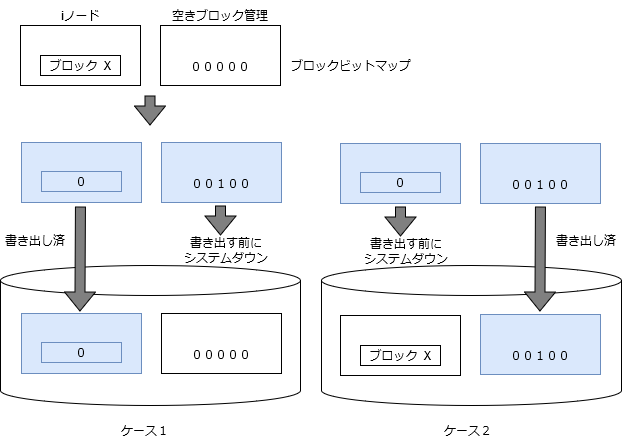
- ケース1: iノード書き出し済、空きブロック管理未書き出し
空きブロックがひとつ行方不明となる。 - ケース2: iノード未書き出し、空きブロック管理書き出し済
ブロックが2重管理されている。このままにしておくと、ブロックが他のファイルに割り当てられるかもしれず、非常に危険。
(図は、旧解読室からパクリました。筆者が書いた部分なので、勘弁してください。)
いずれにせよ、不整合は生じますが、ケース1の方がましなので、本ケースでは、iノードの方を先に書き出しておいた方が安全です。fsckでリカバリするにも、整合性の判断がし易く、回復し易い方に倒しておくべきでしょう*8。昔のUNIXは、このあたり何の考慮もされておらず、どちらのブロックもキャッシュに書くだけで、いつ、どんな順番でディスクに書き出されるかは分からないという状況でした。筆者は昔、信頼性を上げるため、すべての操作で管理ブロックの書き出し順序を考慮し、その上で、先行するブロックの書き出し完了を待ち合わせて、後続のブロックを書き出すようにする、という修正を苦労してしたことがあります。結構性能にインパクトがあるため、一応今言ったことはオプションとしましたが、順序の考慮と先行するブロックの書き出し要求発行は、デフォルトで行うようにしました。
話は飛びますが、筆者は、UNIXを開発していたとは言え、メインフレームのソフトウェア開発部隊の所属であり、検査部門も一緒なので、メインフレームOSと同等の信頼性を要求されて、苦労しました。メインフレームOSに関しては、開発経験はないので、実際のところは分かりませんが、一般的には信頼性高いと言われてますよね。止まらないシステム、というような売り文句が付くようなシステムは、大体メインフレームベースである気がします。ディスクを抜いても(ディクスのケーブルを抜くとか)、たまたま、そのディスク上のファイルをアクセスしたプロセスが異常終了するのは許容されるが、OSも他のプロセスも落ちるのは許されない、というのが検査部門の判断基準の一例で、実際にそんな試験をされるわけですが、まあ、当時のUNIXなんて、panicしておかしくないですよね。まあ、苦労はしましたが、鍛えられもしました。今では、LinuxやUNIXもかなり信頼性は上がってきているとは思いますが、クラウドの世界では、ソフトウェアは落ちることもあるという前提でシステムを構築することが一般的でしょう。OSSを生業とする弊社の者が言うのもなんですが、OSSはよく使われているとしても、信頼性に関して、信用しすぎるのは危険だと思います*9。落ちることもあるのを前提にシステムを構築するのは正しいと思います。
閑話休題。
今は、ファイルシステムも高機能化して複雑になってきており、整合性の問題は、ジャーナルなどの技術で解決するようになっているかと思います。今ではいろいろなファイルシステムが出てきてますよね。筆者なんかは、機能面ではなく、信頼性の確保をどう実装しているか、という方についつい目が行ってしまいます*10。異常時のケースを初めから考慮していないと、メインルートの設計もきちんとできないと、筆者は考えています。そんな観点で実装を見てみるのもいいのではないでしょうか。実のところ、このあたりの話は、昔から、DB屋*11ならお手の物だったことなのかもしれないな、とは思っています。そう言えば、昔は、ファイルシステムが信用されていなくて、DBをファイルに載せるのはもっての外で、ディスクパーティションをDBに割り当てるのが一般的でした。今では、DBをファイルに載せるのも当たり前に行われているし、仮想化環境では、ディスクパーティションを割り当てたつもりが、実はホスト上の通常ファイルだったりすることもありますしね。なんだか隔世の感があります。
あとがき
徒然と書いていたら結構な量となったので、今回はここまでです。もうしばらく、ファイル管理の話が続きます。ではまた次回。
*1:と言っても、ダンプ解析などのため、命令セットは把握せざるを得ないので、結局は、読む必要があるのですが。
*2:OS徒然草で取り上げるつもりはありませんが、これはこれでブログのネタにはなるかもしれません。
*3:ハードリンクは、ディレクトリに行うのは危険(ループの危険性とか)、ファイルシステムをまたげないなどの弱点があり、シンボリックリンクという機能ができました。また、名前の変更を行うrenameシステムコールも追加されました。
*4:典型的には、512バイト。
*5:ページキャッシュについては、本ブログで取り上げる機会があるかもしれません。
*6:書き出しのサイズとオフセットがブロック単位であれば、ディスクからの読み込みの必要がなく、キャッシュを作成できます。
*7:OSのキャッシュをディスクに書き出すシステムコールです。
*8:ルートディスクはどうするか問題もありますし。
*9:まあ、筆者の本音を言うと、OSSは信用できないことが多いです。
*10:目の付け所は本当の話ですが、最近のファイルシステムの実装を見てはいません。筆者のお眼鏡に叶う実装はあるのでしょうか。
*11:DBを使って何かする人ではなく、DBMSを開発する人。