執筆者 : 小田 逸郎
※ 「OS徒然草」連載記事一覧はこちら
VFS
UNIXが登場した当初は、ファイルシステムと言えば、ローカルファイルシステムだけで、それもただ一種類だけでした。ファイル関連のシステムコールを発行すると、ストレートにローカルファイルシステムの操作をすることになり、コードの構造としては、単純なものでした。その状況が変わったのは、NFSの登場がきっかけです。筆者は、自身が開発に携わっていたOS(UNIX System V release 2ベース)にNFSを実装した経験があります。スクラッチから開発した訳でなく、米国のどこやらの研究機関からソースコードを買ってきて移植したのですが、NFSのプロトコル処理部や、下位層のSUN RPC・XDRなどは、まあ大体そのまま使える訳ですが、大変だったのはファイル管理本体の改造です。それまでは、ローカルファイルを管理するinodeだけを扱えば良かったのですが、リモートファイルを管理するrnodeというものも扱う必要がでてきたため、それらを統括するvnode*1というものが導入されました。ローカルファイルかリモートファイルかに関わらず、ファイルを管理する制御表は、vnodeであり、ファイルシステムのタイプに依存しない部分(共通部分)は、vnodeで完結し、ファイルシステムのタイプに依存する部分(固有部分)は、inodeかrnodeに処理を振り分けるという構造になったのです。システムコールのエントリ部分から、vnodeに置き換えたり、ファイル管理本体の処理もvnodeの使用とinode/rnodeへの振り分けに改造するなど、結構大変な思いをした記憶があります。
少し時が経ち、OSのベースをUNIX System V release 4に移行した*2際には、ファイル管理の共通処理部分は、VFS(Virtual FileSystem)層として整備された形になっており、NFSも標準でサポートされていたし、ローカルファイルシステムも複数のファイルシステムタイプを同時に使えるようになっていました。ひとつをふたつに増やすのは大変でしが、ふたつを沢山にするのは、そう大した手間ではないですからね。VFSという形で整理されたという訳です。VFSの導入で印象的に感じたのは、関数ポインタセットによるテクニックです。
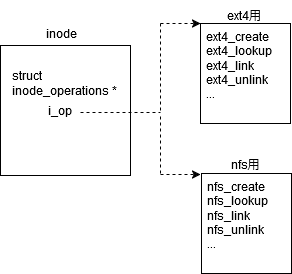
例えば、Linuxだと、inode_operationsというのがありますよね。これは、inodeに対する一連の操作を定義している訳ですが、実際に行う処理は、ファイルシステムのタイプにより異なります*3。そのため、ファイルシステムタイプごとにinode_operationsを定義しておき、inodeからは、それに応じたセットをポイントするようにしておきます。こうしておくことにより、VFS層では、ファイルシステムタイプを意識することなく、ファイル作成時には、inode->i_op->create を実行すればよい、ということになります。こうしたテクニックは、キャラクタデバイス・ブロックデバイスのドライバなどで大昔からあったのではありますが、多用されるようになったのは、VFSが導入されたあたりからである気がします。それにしても、現在では、このテクニックは、ファイル管理に限らず、Linuxの至るところで、無茶苦茶多用されていますよね。筆者は、このテクニックの有用性は理解しているものの、コードを解析する際、関数の呼び出しを追いづらいので、好きではありません。弊社の若手が取り組んでいる新解読室のネットワーク編とか見ると、関数ポインタを多用している上にネストが無茶苦茶深く、もうほんと解析が大変そうです。最近のLinuxはトレース機能も充実してきているので、そうしたツールを活用して、実際に動かして調べるのが良さそうで、弊社の若手も活用しているようです。筆者は、読んで分からず、動かしてみないと分からないというのは、なんか負けた感がありますし、コードは読んで分かる規模に収めるべきではないかとも思うのですが、もう、Linuxはツールの力を借りないと理解できないレベルに肥大化してしまっていると言えるでしょう。最近は、ツールに頼るというよりは、AIに頼ることになっていきそうな気配も感じていたりします。
閑話休題。
さて、VFSの導入により、複数のローカルファイルシステムを扱えるようになったとは言え、実際に提供されていたローカルファイルシステムは1種類だけでした。しかし、筆者は、特定用途に尖った特性を持つファイルシステムがいろいろ出来て、用途に応じて使い分ける世の中が来るのではないかと興奮したものです(まだ若かったものですから)。そこで早速、大きなファイルを高速にアクセスすることに特化したファイルシステムを開発したものです。当時、標準で提供されていたローカルファイルシステム(ufs)は、ちょっとユニーク(良い意味では使ってません)で、シリンダーグループなど、ディスクのレイアウトを意識した管理構造が特徴でした。シリンダーと言ってもピンとこないかもしれませんね。ディスクというのは、何枚か円盤があって、グルグル回っていて、アームと呼ばれる半径方向に動く可動部分(円盤の枚数分あるが動作としてはひとつ)が磁気記録を読み取るになっています。昔のディスクは、実際に円盤が回っていてアームがガシャガシャ動くのを実際に見れたものです。シリンダーというのは、アームを動かさなくてもアクセスできる範囲のことです。同じファイルのブロックを同じシリンダーに割り当てるようにすれば、アームを動かさなくてもアクセスできるので、効率が良いだろうとか、そんなことを考えながらブロック割り当てをするようになっていました。回転速度を考慮したブロック割り当てなんかもしていました。ただ、レイアウトを意識しているといっても、ファイルシステムの作成時にパラメータをユーザが指定しないといけなくて、面倒過ぎましたし、いくら割り当てを考慮するといっても、一人だけが使用しているワークステーションならいざ知らず、多くのユーザが使用しているサーバで複数のファイルアクセスが行われたときに効果があるかというと疑問で、筆者は、この設計には非常に懐疑的でした。まあ、普通に使う分には、何も問題ありませんし、パラメータ指定による性能差など識別できないので、これはこれで、標準のファイルシステムとして使用していたのですが、当時開発していたOSは、スパコンもプラットフォームだったので、大量のデータを高速にアクセスできるファイルシステムが求められていました。そのため、その用途に特化したファイルシステムを作ろうと考えたのです。ファイルブロックの事前割り当て、ファイルブロックの連続領域割り当て、キャッシュを経由しない直接転送などの特長を持ったファイルシステムでした。実はこのファイルシステムの開発には苦い思い出があります。当時の技術計算のアプリはほとんどFORTRANで書かれていて、しかもスパコンの特長であるベクトル計算のためには、FORTRANを使用する必要がありました。ところが、このFORTRANのファイルアクセスがイケてなくて、レコードというものを意識するようになっていて、そのレコードというのが、最初にレコード長が記録されていて、その後にデータが続くという形式でした。すなわち、最初にレコード長を読み、しかる後にデータを読むということをやっていたのです。折角、ドッカンと大量にアクセスできるようにしたのに、言語側でそれを生かすような作りになっていなかったということが後で発覚した訳です。FORTRANコンパイラをメインフレームOSからUNIXに移植した際にメインフレームOSのファイル構造をそのまま持ち込んだのではないかと想像しますが、言語は専門外なので的外れかもしれません。言語屋にも言語屋の事情があるのでしょうが、UNIXのファイルシステムの特性を考慮してくれても良いのではないかと思ったものです。まあ、こちらが、言語側の実装を理解していなかったのが悪かったことには変わりありません。当時は、C言語を使ったプログラムしか動かしてなくて、FORTRANプログラムを動かしてみれば気がついたはずでした。自分の専門外でもある程度は理解が必要であるとか、システム全体を通してどうなのかを確認する必要があるとか、いろいろ気付きはありました。
開発した高速大容量ファイルシステムは、特徴的な機能を持つもののコードはシンプルで規模も小さいものでした。筆者としては、何にでも対応できる複雑なファイルシステムを作るより、特徴的な機能を持つがシンプルなファイルシステムを使い分ける時代が来るのではないかと思っていたのですが、まあ、これは、シンプルなコードを好む筆者のバイアスが掛かった予想だったようで、全く当たりませんでした。実際のところ、現在に至るまで、様々なローカルファイルシステムが開発されていますが、みな長大な汎用ファイルシステムで、何でもいいから自分だけを使えばよい、他のローカルファイルシステムなど使う必要はない、という思想のものばかりのようです。VFS導入の効果としては、むしろ、様々な種類の疑似ファイルシステムが作られる方向に働いているようです。procfs、sysfsのあたりは旧解読室時代にもありましたが、現在は、なんなんでしょう、debugfs、tracefsなどなど、気が付かないうちに随分増えています。もうやりたい放題ですね。
ページキャッシュ
OSのベースをUNIX System V release 4 に移行した際に最も衝撃を受けたのは、ページキャッシュの登場で、これまで、独立だったメモリ管理とファイル管理が密接に関係するようになったことです。そんなこともあり、筆者は、メインはファイル管理担当でしたが、メモリ管理にも深く関わるようになりました。その経験を活かして、旧解読室では、メモリ管理の章とファイル管理の章を担当しました。当時はまだ弊社に入りたてで、Linuxについてはまだ経験が浅かったのですが、OS屋として、メモリ管理やファイル管理で何をしないといけないのかは十分承知している訳で、Linuxでは、それをどう実装しているんだろうという観点で調べて、その結果を整理したのが旧解読室の記事だったのです。
閑話休題。
そもそもの発端は、mmapという機能の出現になります。これは、ファイルの一部をあたかもプロセス空間の一部として、メモリアクセスにより、アクセスできるようにしようというものです。mmapの実装を少し考えてみましょう。まずは、復習のため、通常のread/writeのデータの様子を図にしてみます。(以降、あくまでもイメージ図です。ファイルシステムのブロックサイズは2KiB、ディスクキャッシュのサイズも2KiBとしています。)
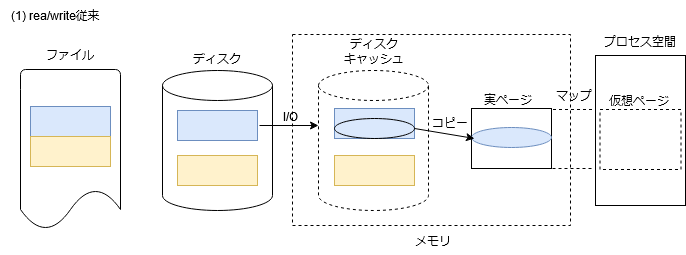
ファイルのデータは、ディスクキャッシュ経由でアクセスされます。プロセス空間とディスクキャッシュ間のデータコピーは、read/writeの契機に行われます。
ここで、ディスクキャッシュを使用して、素朴にmmapを実装した場合を考えてみます。(簡単のため、mmapするプロセス空間側の領域もファイル側の領域もページサイズ(4KiB)境界に合っているということを前提条件とします。)
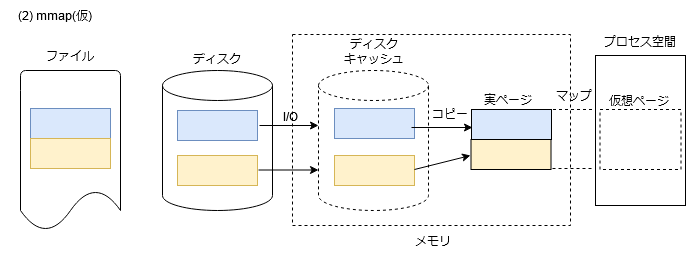
プロセス空間とディスクキャッシュ間のデータコピーはOSが制御することになります。読み込みの契機としては、メモリアクセスによるページフォルト、書き出しの契機としては、msyncの実行などが考えられます。
ここで、この図を見て良く考えてみると、わざわざディスクキャッシュを経由する必要ないんじゃないか、ということに気が付きます。そして、実ページにファイルデータを載せたものをキャッシュとして管理すれば良いという発想に至ります。
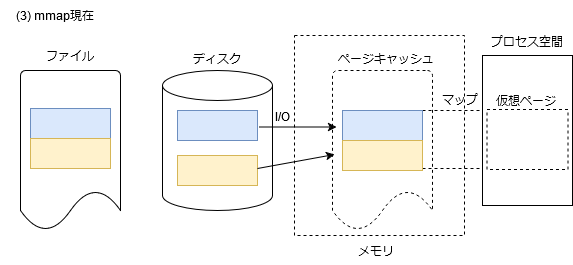
かくして導入されたのがページキャッシュとなります。バックとなるファイル・オフセットが記録されたページ、これこそがページキャッシュの実体です。上の図は、ページキャッシュを使ったmmapの実装になります。
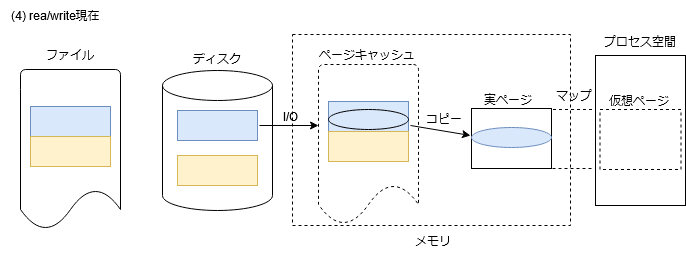
read/writeにしても、ページキャッシュを使用することに何ら支障ありません。現在はディスクキャッシュというものはなくなって、ページキャッシュ経由となっています。ファイルのデータではない領域、例えばファイルシステムの管理データのアクセスはどうすれば良いのでしょうか。考えてみれば、ディスクだってファイル(ブロック型特殊ファイル)です。ページキャッシュに記録されたファイルがブロック型特殊ファイルだというだけのことです。
実ページが枯渇してくると、プロセス空間に割り当てられたページをスワップデバイス*4に退避して、空きページを作るページングという処理が実行されます。さて、mmapされたページというのは、バックとなるファイルがあるわけですから、ページを追い出すのに、わざわざスワップデバイスの領域を割り当てる必要がありません。ページを追い出すときはバックとなるファイルに書き戻し、ページを復活させるときは、そのファイルから読めばよいだけです。スワップデバイスもファイルのひとつですから、結局のところ、プロセス空間の仮想ページで、実ページがページングされているものは、バックとなるファイル・オフセットを記録しておけばよいということになります。
ページキャッシュを複数のプロセスからmmapすることもできます。共有メモリとしての使用が出来る訳です。書き込みOKの場合は、プロセス間で同期を取るなど、共有メモリとしてのお作法を守る必要がありますが、read only のファイルであれば、特に難しいことを考えなくても、単純に皆で共有すれば良いだけなので、そうした方が効率が良くなります。そうやって考えていくと、プロセスのテキスト領域は、OSがプログラムファイルから読み込む訳ですが、mmapしたのと同じ扱いにして、ページを共有すれば良いと言うことになっていきます。プロセス空間の仮想ページにプログラムファイルとオフセットを記録しておけば言い訳ですね。ページングする際にスワップデバイスの領域を割り当てる必要はないですし、書き戻す必要なく、単に解放すれば良いことになります。戻すときは、また元のファイルから読めば良い訳です。
今となっては、ページキャッシュは当たり前過ぎて、元からそんな設計だったのかと思われるかもしれませんが、そうではなかったのです。これまでの説明は、かなり単純化してますし、実際にそうだったのかと言うよりは、筆者が自分なりに理解していった流れに基づく説明ですので、その点はご留意ください。ともかく、当時は、とても良く設計されていることに感心したものです。
従来のディスクキャッシュでは、キャッシュのディスクへのI/Oは、そのまま、デバイスドライバを実行すれば良かったのですが、ページキャッシュの場合、記録しているのはファイル・オフセットなので、一旦、ファイル管理に渡って、どのデバイスブロックがI/Oの対象なのか割り出す必要があります。良く設計できているとは言ったものの、このようにどんどん階層が深くなって、コードも肥大化していく訳で、その点は筆者の好むところではありません。ページサイズとファイルシステムのブロックサイズが一致している訳ではないという点も複雑化を招いています(前図は、それを表現するため、ファイルシステムのブロックサイズを2KiBとしています)。ページキャッシュのI/O中、構成しているファイルブロックの一部がI/Oエラーになった場合、どうしたらいいのでしょうか。Linuxの現実装がどうなっているかには触れませんし、どう実装すべきかも論じませんが、OS屋としては、そうしたケースを予め想定し、設計・実装を行うことが肝要である、とは言っておきたいです。筆者は、面倒なことを考える必要性を少しでも減らすため、ファイルシステムのブロックサイズはページサイズ(4KiB)と一緒にしておく、という前提をスクラッチから開発するのであれば、採用しそうです。現状のコードは、後方互換(既存のファイルシステムを使用可能とする)のため、変えることはできませんが、新規にファイルシステムを作成する場合は、ブロックサイズを4KiBとすることを推奨するようにしますし、現実的にも大体4KiBが採用されているのではないでしょうか。無用なトラブルを避け、メンテナンスコストを下げるためにはそうしておく方が良いと思います。
最後にページキャッシュの管理について少し触れておきます。ディスクのアクセスは、メモリのアクセスに比べて非常に遅いので、ファイルのアクセス性能向上のためには、如何にキャッシュヒット率を上げるかがポイントとなってきます。 昔からあるテクニックとして、先読みと呼ばれるものがあります。ファイルがシーケンシャルにアクセスされていると思ったら、指定された領域の少し先まで、非同期にI/Oを発行して、キャッシュにデータを載せておきます。実際にアクセスされたときには、既にキャッシュに載っているという寸法です。ファイル管理では、ファイルディスクリプタに対してファイルオフセットを管理しているので、そうしたアクセスパターンの予測もある程度はできますが、なかなか一般的な予測は難しいものがあります。アクセスパターンをアプリの方からOSに教えてあげる、fadvise というシステムコールというものも用意されています。ただ、すべてのアプリがこれを使ってくれている訳ではありませんし、また、これはファイル単位での話であって、システム全体として、どのページキャッシュを残すかというような制御も考えなければなりません。筆者の昔の記憶では、Linuxは、実ページが空いているだけ、ページキャッシュとして使用するようになっていました。巨大なファイルをアクセスした後は、そのファイルのキャッシュばかりになってしまい、折角先読みしておいた他のファイルのキャッシュが失われてしまう羽目になるような状況だったと思います。実ページの空きがなくなり、ページキャッシュを解放する際は(、これはメモリ管理の話題になるかもしれませんが)、LRU(least recently used)などの制御で行っていたと思いますが、どのキャッシュが近い将来使われるかの予測として、果たしてどのくらい有効なのでしょうか。現在のLinuxの実装がどうなっているのか知らずに言いますが(もしかして素晴らしいものになっているかもしれませんが)、どのキャッシュを残すかとか予め載せておくとかの判断は、AIの活用のしどころのひとつではないかと思います。AIによりキャッシュのヒット率が向上すれば、システム全体の性能改善に役に立つことでしょう。
あとがき
ファイル管理の話題はこんなところです。また思い出したら何か書くかもしれません。本年(2024年)度は、これで最後です。ネタはまだありますし、少し構想を整理して、また4月以降に再開したいと思います。ではまた次回。