執筆者 : 岩本 俊弘
SmartNIC で遊んでみる
RDMA やその他の機能のついている NIC は新品で買うとわりと高価であるが、中古だと個人でも手の届きそうな価格で手に入る。archlinux の wiki にもそんなことが書いてある。
今回そういった NIC を2枚購入 (会社で) して、ちょっと遊んでみることにした。 スイッチも中古だと同様に手頃な値段で手に入るようだが、あまり面倒事を増やしたくなかったので今回は直結で。
選定
Mellanox 社のものが流通数も多く情報も充実しているようなのでそれから選んだ。 Linux には mlx4 と mlx5 という2つのドライバがあって、前者が ConnectX-2 と ConnectX-3、後者が ConnectX-4 以降に対応している。
ConnectX は型番の枝番が大量にあって、eBay 等で買う時は正しいものを選んでいるかよくよく確認したほうがよいと思われる。EDR (100Gbps) かつ Ethernet でも InfiniBand でも使えるという VPI と書いてあるものを 2枚買って 10万円強であった。 (ConnectX-3 でよければもっとずっと安く手に入るようである。)
インストール
今回実験台となった PC は以下の 2台である。カーネルバージョンはどちらも 5.4 である。
- cardamine (Core i5-6500, ubuntu focal)
- apricot (Core i7-7800X, ubuntu bionic, linux-hwe カーネル)
これらは ATX タワーケースであるが、ConnectX のヒートシンクはスロットから吸いこんだ空気で冷却されるような形になっており、マニュアルを見るとどれだけの airflow が必要といったことが書いてある。 1U とか 2U のラックマウントケースなら特別な配慮がいらないのかもしれないが、リモートワーク中に NIC が熱暴走とか勘弁してほしいので PCI スロットに取りつけられる冷却ファン (ここでは親和産業 SS-NPCIFSTY80PRO-F2 を使用) もあわせて取りつけた。
干渉するため隣接スロットにはファンが付けられないので結局以下の写真のような感じになって、カードを沢山挿したい人にはちょっとお勧めできない感じである。 手間がかけられるなら厚紙かもうちょっとちゃんとした素材でダクトを工作すればいいのかもしれない。

カードの認識
dmesg では以下のように認識された.これだけでは型番がよく分からない。
dmesg (click to expand)
toshii@apricot:~/mft-4.15.1-9-x86_64-deb$ dmesg|egrep 'mlx|0000:17' [ 0.269499] pci 0000:17:00.0: [15b3:1013] type 00 class 0x020000 [ 0.269674] pci 0000:17:00.0: reg 0x10: [mem 0xb2000000-0xb3ffffff 64bit pref] [ 0.269922] pci 0000:17:00.0: reg 0x30: [mem 0xb5e00000-0xb5efffff pref] [ 0.270482] pci 0000:17:00.0: PME# supported from D3cold [ 0.270818] pci 0000:17:00.1: [15b3:1013] type 00 class 0x020000 [ 0.270981] pci 0000:17:00.1: reg 0x10: [mem 0xb0000000-0xb1ffffff 64bit pref] [ 0.271262] pci 0000:17:00.1: reg 0x30: [mem 0xb5d00000-0xb5dfffff pref] [ 0.271795] pci 0000:17:00.1: PME# supported from D3cold [ 0.331132] pci_bus 0000:17: resource 1 [mem 0xb5d00000-0xb5efffff] [ 0.331133] pci_bus 0000:17: resource 2 [mem 0xb0000000-0xb3ffffff 64bit pref] [ 0.854247] iommu: Adding device 0000:17:00.0 to group 24 [ 0.854299] iommu: Adding device 0000:17:00.1 to group 25 [ 1.587351] mlx5_core 0000:17:00.0: firmware version: 12.23.1020 [ 2.427806] (0000:17:00.0): E-Switch: Total vports 1, per vport: max uc(1024) max mc(16384) [ 2.449738] mlx5_core 0000:17:00.0: Port module event: module 0, Cable unplugged [ 2.457040] mlx5_core 0000:17:00.1: firmware version: 12.23.1020 [ 3.344909] (0000:17:00.1): E-Switch: Total vports 1, per vport: max uc(1024) max mc(16384) [ 3.366631] mlx5_core 0000:17:00.1: Port module event: module 1, Cable unplugged [ 3.372930] mlx5_core 0000:17:00.0: MLX5E: StrdRq(0) RqSz(1024) StrdSz(1) RxCqeCmprss(0) [ 3.510210] mlx5_core 0000:17:00.1: MLX5E: StrdRq(0) RqSz(1024) StrdSz(1) RxCqeCmprss(0) [ 3.677615] mlx5_core 0000:17:00.1 enp23s0f1: renamed from eth1 [ 3.678245] mlx5_ib: Mellanox Connect-IB Infiniband driver v5.0-0 [ 3.705144] mlx5_core 0000:17:00.0 enp23s0f0: renamed from eth0 toshii@apricot:~/mft-4.15.1-9-x86_64-deb$ uname -a Linux apricot 4.15.0-91-generic #92-Ubuntu SMP Fri Feb 28 11:09:48 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
ファームウェア更新
ファームウェアが 2018年のもので古いので、ちょっとどきどきするが https://www.mellanox.com/support/firmware/update-instructions に従い更新することにする。
mst コマンド実行例 (click to expand)
$ sudo mst start
Starting MST (Mellanox Software Tools) driver set
Loading MST PCI module - Success
Loading MST PCI configuration module - Success
Create devices
Unloading MST PCI module (unused) - Success
toshii@apricot:~/mft-4.15.1-9-x86_64-deb$ sudo mst status
MST modules:
------------
MST PCI module is not loaded
MST PCI configuration module loaded
MST devices:
------------
/dev/mst/mt4115_pciconf0 - PCI configuration cycles access.
domain:bus:dev.fn=0000:17:00.0 addr.reg=88 data.reg=92 cr_bar.gw_offset=-1
Chip revision is: 00
mst start しておくと以下のように温度が見えるようになる。
$ sudo mget_temp -d /dev/mst/mt4115_pciconf0 35
web page の指示に従って PSID を取得すると LNV2190110032 と出てきたので、どうも Lenovo の OEM ということのようである。
psid を書き換えるオプションもあるようだが、mellanox.com の AI chatbot に聞いてみたら Lenovo OEM 用のファームウェアの在りかを教えてもらったので、結局以下のようにした。 このコマンドを実行してようやく手に入れたカードが本当に EDR 対応っぽいことが確認できた。
firmware 更新 (click to expand)
toshii@apricot:~$ sudo ./mlxfwmanager_LeSI_20B-OFED-5.1-1_build1
Querying Mellanox devices firmware ...
Device #1:
----------
Device Type: ConnectX4
Part Number: 00MM962_Ax
Description: ConnectX-4 EDR IB; dual-port QSFP28; PCIe3.0 x16
PSID: LNV2190110032
PCI Device Name: /dev/mst/mt4115_pciconf0
Base MAC: <redacted>
Versions: Current Available
FW 12.23.1020 12.28.1002
PXE 3.5.0504 3.6.0101
UEFI 14.16.0017 14.21.0016
Status: Update required
---------
Found 1 device(s) requiring firmware update...
Perform FW update? [y/N]: y
Device #1: Updating FW ...
接続
手元にあった direct attach cable で2台の ConnectX を繋いでみたが 1Gbps にしかならない。
ethtool や mlxlink コマンドでスピード設定をいろいろやってみたが 1Gbps 以外ではリンクアップもしない。
direct attach cable を使っているが、ただの銅線というわけではなく EEPROM に型番等が書き込まれている。
$ sudo mlxcables
Querying Cables ....
Cable #1:
---------
Cable name : mt4115_pciconf0.1_cable_1
>> No FW data to show
-------- Cable EEPROM --------
Identifier : QSFP28 (11h)
Technology : Copper cable unequalized (a0h)
Compliance : Unspecified
Attenuation : 2.5GHz: 4dB
5.0GHz: 6dB
7.0GHz: 8dB
12.9GHz: 11dB
25.78GHz: 0dB
OUI : 0xfc7ce7
Vendor : OPTCORE
Serial number : <redacted>
Part number : Q-100G-DAC-P2M
Revision : 5
Temperature : N/A
Length : 2 m
いろいろ検索してみると、ベンダーによっては型番ではじいて 3rd party のケーブルや QSFP モジュールが使えないといった情報もあり、Mellanox はどうもそれに該当するようである。 mlxlink でスピードを指定したりいろいろしていたら、結局以下のようにそれを示唆するエラーメッセージも出るようになった。
$ sudo mlxlink -d /dev/mst/mt4115_pciconf0.1 -c Operational Info ---------------- State : Disable Physical state : ETH_AN_FSM_ENABLE Speed : N/A Width : N/A FEC : N/A Loopback Mode : N/A Auto Negotiation : ON Supported Info -------------- Enabled Link Speed : 0xf8fc0000 (100G,50G,25G) Supported Cable Speed : 0xf8f1f1d3 (100G,56G,50G,40G,25G,10G,1G) Troubleshooting Info -------------------- Status Opcode : 1036 Group Opcode : MNG FW Recommendation : Connected wrong module type. Change to a different module type. Physical Counters and BER Info ------------------------------ Time Since Last Clear [Min] : N/A Effective Physical Errors : N/A Effective Physical BER : N/A Raw Physical BER : N/A Raw Physical Errors Per Lane : N/A
諦めて純正ケーブルを購入したら特になにも設定することなくあっさり 100Gbps でリンクアップした。一つ勉強になった。
mlxlink 出力 (click to expand)
toshii@apricot:~$ sudo mlxlink -d /dev/mst/mt4115_pciconf0.1 -c [sudo] password for toshii: Operational Info ---------------- State : Active Physical state : LinkUp Speed : 100GbE Width : 4x FEC : Standard RS-FEC - RS(528,514) Loopback Mode : No Loopback Auto Negotiation : ON Supported Info -------------- Enabled Link Speed : 0xfafc0003 (100G,50G,25G,1G) Supported Cable Speed : 0xf8f1f1d3 (100G,56G,50G,40G,25G,10G,1G) Troubleshooting Info -------------------- Status Opcode : 0 Group Opcode : N/A Recommendation : No issue was observed. Physical Counters and BER Info ------------------------------ Time Since Last Clear [Min] : 2.1 Effective Physical Errors : 0 Effective Physical BER : 15E-255 Raw Physical BER : 15E-255 Raw Physical Errors Per Lane : 0,0,0,0
VPI なので InfiniBand と Ethernet を切り替えて使用できるが、買った時は Ethernet モードになっていたので普通に ip addr でアドレスを付けてやれば通信できる。
MTU を 9000 にしておく。 (1割弱速くなる)
後との比較のため軽く iperf (TCP, 10秒間) で測定しておく。
4,5 列目は time コマンドの出力 (単位は秒) である。10秒の測定なので、1並列の場合はほとんど CPU が busy、4並列の場合は 2コア分ほど使っていることがわかる。
以降の測定との比較のため、数値は 8 で割って GB/sec で表にすると以下のようになる。
| 向き (client -> server) | 並列 | 帯域 (GB/sec) | client sys | server sys |
|---|---|---|---|---|
| cardamine -> apricot | 1 | 4.80 | 7.633 | 9.886 |
| cardamine -> apricot | 4 | 6.90 | 13.790 | 22.697 |
| apricot -> cardamine | 1 | 4.71 | 8.011 | 8.603 |
| apricot -> cardamine | 4 | 6.30 | 20.803 | 19.360 |
2ポートずつ付いてるから並列で動かせば速くなるのではと思われたかもしれないが、残念ながらこんな状況なのでケーブル 2本繋いで iperf を同時に動かしたところで別に速くはならない。
mlx5_core 0000:17:00.0: 63.008 Gb/s available PCIe bandwidth, limited by 8 GT/s x8 link at 0000:16:00.0 (capable of 126.016 Gb/s with 8 GT/s x16 link)
iperf ログ (click to expand)
toshii@cardamine:~$ time iperf -c 192.168.110.25 ------------------------------------------------------------ Client connecting to 192.168.110.25, TCP port 5001 TCP window size: 1.94 MByte (default) ------------------------------------------------------------ [ 3] local 192.168.110.23 port 54726 connected with 192.168.110.25 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 44.7 GBytes 38.4 Gbits/sec real 0m10.046s user 0m0.191s sys 0m7.633s toshii@apricot:~$ time iperf -s ------------------------------------------------------------ Server listening on TCP port 5001 TCP window size: 128 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.110.25 port 5001 connected with 192.168.110.23 port 54726 [ ID] Interval Transfer Bandwidth [ 4] 0.0-10.0 sec 44.7 GBytes 38.3 Gbits/sec ^C real 0m24.455s user 0m0.128s sys 0m9.886s
4並列
toshii@cardamine:~$ time iperf -c 192.168.110.25 -P 4 ------------------------------------------------------------ Client connecting to 192.168.110.25, TCP port 5001 TCP window size: 2.03 MByte (default) ------------------------------------------------------------ [ 5] local 192.168.110.23 port 54732 connected with 192.168.110.25 port 5001 [ 9] local 192.168.110.23 port 54734 connected with 192.168.110.25 port 5001 [ 4] local 192.168.110.23 port 54730 connected with 192.168.110.25 port 5001 [ 3] local 192.168.110.23 port 54728 connected with 192.168.110.25 port 5001 [ ID] Interval Transfer Bandwidth [ 5] 0.0-10.0 sec 13.6 GBytes 11.7 Gbits/sec [ 9] 0.0-10.0 sec 14.7 GBytes 12.7 Gbits/sec [ 4] 0.0-10.0 sec 17.5 GBytes 15.0 Gbits/sec [ 3] 0.0-10.0 sec 18.5 GBytes 15.9 Gbits/sec [SUM] 0.0-10.0 sec 64.3 GBytes 55.2 Gbits/sec real 0m10.057s user 0m0.417s sys 0m13.790s toshii@apricot:~$ time iperf -s ------------------------------------------------------------ Server listening on TCP port 5001 TCP window size: 128 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.110.25 port 5001 connected with 192.168.110.23 port 54728 [ 5] local 192.168.110.25 port 5001 connected with 192.168.110.23 port 54730 [ 6] local 192.168.110.25 port 5001 connected with 192.168.110.23 port 54732 [ 7] local 192.168.110.25 port 5001 connected with 192.168.110.23 port 54734 [ ID] Interval Transfer Bandwidth [ 4] 0.0-10.0 sec 18.5 GBytes 15.9 Gbits/sec [ 5] 0.0-10.0 sec 17.5 GBytes 15.0 Gbits/sec [ 6] 0.0-10.0 sec 13.6 GBytes 11.7 Gbits/sec [ 7] 0.0-10.0 sec 14.7 GBytes 12.6 Gbits/sec [SUM] 0.0-10.0 sec 64.3 GBytes 55.1 Gbits/sec ^C real 0m16.713s user 0m0.530s sys 0m22.697s
逆方向
toshii@apricot:~$ time iperf -c 192.168.110.23 ------------------------------------------------------------ Client connecting to 192.168.110.23, TCP port 5001 TCP window size: 325 KByte (default) ------------------------------------------------------------ [ 3] local 192.168.110.25 port 49032 connected with 192.168.110.23 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 43.9 GBytes 37.7 Gbits/sec real 0m10.034s user 0m0.072s sys 0m8.011s toshii@cardamine:~$ time iperf -s ------------------------------------------------------------ Server listening on TCP port 5001 TCP window size: 128 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.110.23 port 5001 connected with 192.168.110.25 port 49032 [ ID] Interval Transfer Bandwidth [ 4] 0.0-10.0 sec 43.9 GBytes 37.7 Gbits/sec ^C real 0m18.958s user 0m0.249s sys 0m8.603s
逆方向, 4並列
toshii@apricot:~$ time iperf -c 192.168.110.23 -P 4 ------------------------------------------------------------ Client connecting to 192.168.110.23, TCP port 5001 TCP window size: 325 KByte (defaul ------------------------------------------------------------ [ 4] local 192.168.110.25 port 49036 connected with 192.168.110.23 port 5001 [ 5] local 192.168.110.25 port 49038 connected with 192.168.110.23 port 5001 [ 6] local 192.168.110.25 port 49040 connected with 192.168.110.23 port 5001 [ 3] local 192.168.110.25 port 49034 connected with 192.168.110.23 port 5001 [ ID] Interval Transfer Bandwidth [ 4] 0.0-10.0 sec 21.2 GBytes 18.2 Gbits/sec [ 5] 0.0-10.0 sec 10.9 GBytes 9.40 Gbits/sec [ 6] 0.0-10.0 sec 10.8 GBytes 9.31 Gbits/sec [ 3] 0.0-10.0 sec 21.1 GBytes 18.1 Gbits/sec [SUM] 0.0-10.0 sec 64.1 GBytes 55.1 Gbits/sec real 0m10.035s user 0m0.301s sys 0m20.803s toshii@cardamine:~$ time iperf -s ------------------------------------------------------------ Server listening on TCP port 5001 TCP window size: 128 KByte (default) ------------------------------------------------------------ [ 4] local 192.168.110.23 port 5001 connected with 192.168.110.25 port 49034 [ 6] local 192.168.110.23 port 5001 connected with 192.168.110.25 port 49038 [ 8] local 192.168.110.23 port 5001 connected with 192.168.110.25 port 49040 [ 5] local 192.168.110.23 port 5001 connected with 192.168.110.25 port 49036 [ ID] Interval Transfer Bandwidth [ 4] 0.0-10.0 sec 21.1 GBytes 18.1 Gbits/sec [ 6] 0.0-10.0 sec 10.9 GBytes 9.39 Gbits/sec [ 8] 0.0-10.0 sec 10.8 GBytes 9.31 Gbits/sec [ 5] 0.0-10.0 sec 21.2 GBytes 18.2 Gbits/sec [SUM] 0.0-10.0 sec 64.1 GBytes 55.1 Gbits/sec ^C real 0m14.240s user 0m0.589s sys 0m19.360s
RDMA
せっかく機能があるので RDMA を試してみることにする。 RDMA をするにはいくつか準備が必要である。
$ sudo apt-get install rdmacm-utils rdma-core
これで /dev/infiniband/rdma_cm が見えるようになって、rdma_server とか udaddy で動作確認ができる。
qperf
apt-get install qperf して、apricot で qperf を起動した上でもう片方から測定した。
帯域は上記の 4並列で動かした iperf での TCP と同等であるが、CPU 使用率は 2% 程度である。(ログを参照)
| テスト名 | 帯域 (GB/s) |
|---|---|
| rc_rdma_read_bw | 6.47 |
| rc_rdma_write_bw | 7.25 |
qperf ログ (click to expand)
toshii@cardamine:~$ qperf 192.168.110.25 -vv -cm1 -m 1M rc_rdma_read_bw
rc_rdma_read_bw:
bw = 6.47 GB/sec
msg_rate = 6.17 K/sec
msg_size = 1 MiB (1,048,576)
time = 2 sec
timeout = 5 sec
use_cm = 1
recv_cost = 2.32 ms/GB
send_real_time = 2 sec
send_bytes = 12.9 GB
send_msgs = 12,336
recv_cpus_used = 1.5 % cpus
recv_cpus_user = 0.5 % cpus
recv_cpus_kernel = 1 % cpus
recv_real_time = 2 sec
recv_cpu_time = 30 ms
recv_bytes = 12.9 GB
recv_msgs = 12,336
recv_max_cqe = 2
toshii@cardamine:~$ qperf 192.168.110.25 -vv -cm1 -m 1M rc_rdma_write_bw
rc_rdma_write_bw:
bw = 7.25 GB/sec
msg_rate = 6.92 K/sec
msg_size = 1 MiB (1,048,576)
time = 2 sec
timeout = 5 sec
use_cm = 1
send_cost = 1.93 ms/GB
recv_cost = 2.07 ms/GB
send_cpus_used = 1.5 % cpus
send_cpus_user = 0.5 % cpus
send_cpus_intr = 0.5 % cpus
send_cpus_kernel = 0.5 % cpus
send_real_time = 2 sec
send_cpu_time = 30 ms
send_bytes = 15.6 GB
send_msgs = 14,855
send_max_cqe = 2
recv_cpus_used = 1.5 % cpus
recv_cpus_user = 0.5 % cpus
recv_cpus_kernel = 1 % cpus
recv_real_time = 2 sec
recv_cpu_time = 30 ms
recv_bytes = 14.5 GB
recv_msgs = 13,831
recv_max_cqe = 1
toy program
単にデータを送受信しているだけではつまらないので、送受信したデータに対して簡単な計算をするプログラムを作成して、トランスポートの違いによる性能の変化をみてみることにする。 ここまでの iperf と qperf の比較から、TCP と RDMA の差は CPU 2コア分程度の memcpy が余計に発生することだと思われるので、そんなに差はつかないのではとも予想できる。
あまり複雑な計算をするとデータ送受信の影響が見えなくなる気もする一方、単純に int 配列に1を足して返すとかだとつまらないので、2次元の拡散方程式 を簡単に差分法で計算することにする。処理の流れは以下のようになる。
do_client_init関数でクライアントが初期値データを作る- TCP または RDMA でサーバにデータを転送する
do_server_work関数で1時間ステップ後の値を計算する- TCP または RDMA でクライアントにデータを転送する
do_client_work関数でクライアントが境界条件を満たすようにデータを更新する(バッファ間を memcpy した後最外周部に 0 を代入する)- 指定された回数に達するまで 2 に戻ってくり返す
クライアント側計算コード (click to expand)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <immintrin.h>
#include "work.h"
int
do_client_init(double *buf, int size, int positive_square) {
__m256d zero, *p;
int i, j, ub;
zero = _mm256_setzero_pd();
i = size * size / 4;
p = (__m256d *)buf;
while (i--)
*p++ = zero;
ub = size / 2 + positive_square;
for(i = size / 2 - positive_square; i < ub; i++)
for(j = size / 2 - positive_square; j < ub; j++)
buf[i * size + j] = 1e4;
return 0;
}
int
do_client_work(const double *read_buf, double *write_buf, int size) {
__m256d zero, *p;
int i;
memcpy(write_buf, read_buf, sizeof(double) * size * size);
/* boundary condition */
zero = _mm256_setzero_pd();
p = (__m256d *)write_buf;
for(i = size / 4; i--; p++)
*p = zero;
p = (__m256d *)(write_buf + (size - 1) * size);
for(i = size / 4; i--; p++)
*p = zero;
for(i = 1; i < size - 1; i++) {
write_buf[i * size] = 0;
write_buf[i * size + size - 1] = 0;
}
return 0;
}
int
do_full_print(const double *buf, int size) {
int i, j;
const double *p;
p = buf;
printf("[");
i = size;
while (i--) {
printf("[");
j = size - 1;
while (j--)
printf("%f, ", *p++);
if (i > 0)
printf("%f],\n", *p++);
else
printf("%f]\n", *p++);
}
printf("]\n");
}
サーバ側計算コード (click to expand)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <immintrin.h>
#include "work.h"
int
do_server_work(const double *read_buf, double *write_buf, double **scratch,
double factor, int size) {
__m512d a0, a, a1, au, ad;
__m512d d, e, f;
__m512d *p, *q, *sp;
int i, j;
if (*scratch == NULL)
posix_memalign(scratch, 64, sizeof(double) * size);
for(i = 0; i < size; i++) {
a = _mm512_setzero_pd();
p = (__m512d *)(read_buf + i * size);
a1 = *(__m512d *)p;
q = (__m512d *)(write_buf + (i - 1) * size);
sp = (__m512d *)*scratch;
for(j = 0; j < size / 8; j++) {
a0 = a;
a = a1;
if (j < (size / 8 - 1))
a1 = ((__m512d *)p)[j + 1];
else
a1 = _mm512_setzero_pd();
if (i > 0)
ad = *(__m512d *)(p + j - size / 8);
else
ad = _mm512_setzero_pd();
if (i < (size - 1))
au = *(__m512d *)(p + j + size / 8);
else
au = _mm512_setzero_pd();
d = _mm512_permutex2var_pd(a, (__v8di){15, 0, 1,2,3,4,5,6}, a0);
e = _mm512_permutex2var_pd(a, (__v8di){1,2,3,4,5,6,7, 8}, a1);
f = d + e + au + ad - 4 * a;
if (i > 0)
/* update previous line */
*q++ = ad + factor * (*sp);
*sp++ = f;
}
}
sp = (__m512d *)*scratch;
p = (__m512d *)(read_buf + (i - 1) * size);
for(j = 0; j < size / 8; j++) {
ad = *(__m512d *)(p + 8 * j);
*q++ = ad + factor * (*sp);
}
return 0;
}
サーバ側では avx512 の permutation 命令を使って要素を 1つずつずらしたデータを用意した上で 8 要素まとめて計算しているが、おかげで動作する環境を選ぶようになってしまった。実際にどれくらい速くなっているかは怖いので測っていないので不明である。
これらを呼び出す本体のプログラムは以下である。 RDMA 版は、以前弊社のブログ (RDMAプログラミング入門) で出てきた RDMA サンプルプログラムを改造したものである。
rpp_e.c (click to expand)
/* SPDX-License-Identifier: GPLv2
* Copyright(c) 2020 Itsuro Oda
*/
#define _GNU_SOURCE
#include <math.h>
#include <unistd.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <rdma/rdma_cma.h>
#include <rdma/rdma_verbs.h>
#include "work.h"
/* rpp_e: simplified version of rpp.
*
* only difference between rpp is that rpp_e uses rdma_create_ep.
*
*/
static int server = -1;
static int debug;
#define DEBUG_LOG if (debug) printf
struct rpp_rdma_info {
uint64_t buf;
uint32_t rkey;
uint32_t size;
};
static struct rpp_rdma_info recv_buf;
static struct ibv_mr *recv_mr;
static struct rpp_rdma_info send_buf;
static struct ibv_mr *send_mr;
static int data_size, count, dsize;
static int work = 0;
static char *read_data, *write_data;
static struct ibv_mr *read_mr;
static struct ibv_mr *write_mr;
static uint32_t rkey;
static uint64_t raddr;
static uint32_t rlen;
static int
rpp_create_ep(char *server_ip, struct rdma_cm_id **id, int server)
{
int ret;
char *p;
struct rdma_addrinfo hints, *res;
struct ibv_qp_init_attr init_attr;
struct ibv_wc wc;
p = rindex(server_ip, ':');
if (p != NULL)
*p++ = '\0';
else
p = "7999";
memset(&hints, 0, sizeof hints);
hints.ai_port_space = RDMA_PS_TCP;
if (server) {
hints.ai_flags = RAI_PASSIVE;
}
DEBUG_LOG("rdma_getaddrinfo\n");
ret = rdma_getaddrinfo(server_ip, p, &hints, &res);
if (ret != 0) {
perror("rdma_getaddrinfo");
return 1;
}
memset(&init_attr, 0, sizeof(init_attr));
init_attr.cap.max_send_wr = 20;
init_attr.cap.max_recv_wr = 20;
init_attr.cap.max_recv_sge = 1;
init_attr.cap.max_send_sge = 1;
init_attr.qp_type = IBV_QPT_RC;
init_attr.sq_sig_all = 1;
DEBUG_LOG("rdma_create_ep\n");
ret = rdma_create_ep(id, res, NULL, &init_attr);
if (ret != 0) {
perror("rdma_create_ep");
return 1;
}
return 0;
}
static int
rpp_setup_buffers(struct rdma_cm_id *id)
{
DEBUG_LOG("rdma_reg_msgs recv_buf\n");
recv_mr = rdma_reg_msgs(id, &recv_buf, sizeof(recv_buf));
if (recv_mr == NULL) {
perror("rdma_reg_msgs recv_buf");
return 1;
}
DEBUG_LOG("rdma_reg_msgs send_buf\n");
send_mr = rdma_reg_msgs(id, &send_buf, sizeof(send_buf));
if (send_mr == NULL) {
perror("rdma_reg_msgs send_buf");
return 1;
}
DEBUG_LOG("rdma_reg_read\n");
read_mr = rdma_reg_read(id, read_data, data_size);
if (read_mr == NULL) {
perror("rdma_reg_read");
return 1;
}
DEBUG_LOG("rdma_reg_write\n");
write_mr = rdma_reg_write(id, write_data, data_size);
if (write_mr == NULL) {
perror("rdma_reg_write");
return 1;
}
return 0;
}
static void
rpp_free_buffers(void)
{
if (recv_mr) {
DEBUG_LOG("rdma_dereg_mr recv_mr\n");
if (rdma_dereg_mr(recv_mr) != 0) {
perror("rdma_rereg_mr recv_mr");
}
}
if (send_mr) {
DEBUG_LOG("rdma_dereg_mr send_mr\n");
if (rdma_dereg_mr(send_mr) != 0) {
perror("rdma_rereg_mr send_mr");
}
}
if (read_mr) {
DEBUG_LOG("rdma_dereg_mr read_mr\n");
if (rdma_dereg_mr(read_mr) != 0) {
perror("rdma_rereg_mr read_mr");
}
}
if (write_mr) {
DEBUG_LOG("rdma_dereg_mr write_mr\n");
if (rdma_dereg_mr(write_mr) != 0) {
perror("rdma_rereg_mr write_mr");
}
}
}
static int
rpp_rdma_recv(struct rdma_cm_id *id)
{
int ret;
struct ibv_wc wc;
DEBUG_LOG("rdma_get_recv_comp\n");
ret = rdma_get_recv_comp(id, &wc);
if (ret < 0) {
perror("rdma_get_recv_comp");
return 1;
} else if (ret == 0) {
fprintf(stderr, "rdma_get_recv_comp ret 0\n");
return 1;
}
/* NOTE: client send remote buffer info to server.
* server's send is to notify only and data has no meaning.
*/
if (server) {
rkey = recv_buf.rkey;
raddr = recv_buf.buf;
rlen = recv_buf.size;
printf("remote rkey %x, addr %lx, len %d\n", rkey, raddr, rlen);
}
/* register for next recieve */
DEBUG_LOG("rdma_post_recv\n");
ret = rdma_post_recv(id, NULL, &recv_buf, sizeof(recv_buf), recv_mr);
if (ret != 0) {
perror("rdma_post_recv");
return 1;
}
return 0;
}
static int
rpp_wait_send_comp(struct rdma_cm_id *id)
{
int ret;
struct ibv_wc wc;
DEBUG_LOG("rdma_get_send_comp\n");
ret = rdma_get_send_comp(id, &wc);
if (ret < 0) {
perror("rdma_get_send_comp");
return 1;
} else if (ret == 0) {
fprintf(stderr, "rdma_get_send_comp ret 0\n");
return 1;
}
return 0;
}
static int
rpp_rdma_send(struct rdma_cm_id *id)
{
int ret;
DEBUG_LOG("rdma_post_send\n");
ret = rdma_post_send(id, NULL, &send_buf, sizeof(send_buf), send_mr, 0);
if (ret != 0) {
perror("rdma_post_send");
return 1;
}
return rpp_wait_send_comp(id);
}
static int
run_server(char *server_ip)
{
int i, ret;
struct rdma_cm_id *listen_id;
struct rdma_cm_id *id = NULL;
double *scratch = NULL;
ret = rpp_create_ep(server_ip, &listen_id, 1);
if (ret != 0) {
return 1;
}
DEBUG_LOG("rdma_listen\n");
ret = rdma_listen(listen_id, 1);
if (ret != 0) {
perror("rdma_listen");
goto out;
}
DEBUG_LOG("rdma_get_request\n");
ret = rdma_get_request(listen_id, &id);
if (ret != 0) {
perror("rdma_get_request");
goto out;
}
ret = rpp_setup_buffers(id);
if (ret != 0) {
goto out;
}
/* regisger for first recieve */
DEBUG_LOG("rdma_post_recv\n");
ret = rdma_post_recv(id, NULL, &recv_buf, sizeof(recv_buf), recv_mr);
if (ret != 0) {
perror("rdma_post_recv");
goto out;
}
DEBUG_LOG("rdma_accept\n");
ret = rdma_accept(id, NULL);
if (ret != 0) {
perror("rdma_accept");
goto out;
}
for(i = 0; i < count; i++) {
/* recieve remote buffer info from client */
ret = rpp_rdma_recv(id);
if (ret != 0) {
goto out;
}
/* RDMA READ */
DEBUG_LOG("rdma_post_read\n");
ret = rdma_post_read(id, NULL, read_data, rlen, read_mr, 0, raddr, rkey);
if (ret != 0) {
perror("rdma_post_read");
goto out;
}
ret = rpp_wait_send_comp(id);
if (ret != 0) {
goto out;
}
if (work)
do_server_work((const double *)read_data, (double *)write_data, &scratch, 1e-2, dsize);
else
printf("RDMA READ data: %s\n", read_data);
/* send go ahead to clinet */
ret = rpp_rdma_send(id);
if (ret != 0) {
goto out;
}
/* recieve remote buffer info from client */
ret = rpp_rdma_recv(id);
if (ret != 0) {
goto out;
}
/* prepare write data */
if (! work)
strcpy(write_data, "bbb");
/* RDMA WRITE */
DEBUG_LOG("rdma_post_write\n");
ret = rdma_post_write(id, NULL, write_data, rlen, write_mr, 0, raddr, rkey);
if (ret != 0) {
perror("rdma_post_write");
goto out;
}
ret = rpp_wait_send_comp(id);
if (ret != 0) {
goto out;
}
/* send complete to clinet */
ret = rpp_rdma_send(id);
if (ret != 0) {
goto out;
}
}
printf("done\n");
out:
rpp_free_buffers();
if (id) {
DEBUG_LOG("rdma_destroy_qp\n");
rdma_destroy_qp(id);
DEBUG_LOG("rdma_destroy_id id\n");
if (rdma_destroy_id(id) != 0) {
perror("rdma_destroy_id id");
}
}
DEBUG_LOG("rdma_destroy_id listen_id\n");
if (rdma_destroy_id(listen_id) != 0) {
perror("rdma_destroy_id listen_id");
}
return ret;
}
static int
run_client(const char *server_ip)
{
int i, ret;
struct rdma_cm_id *id;
struct ibv_wc wc;
ret = rpp_create_ep(server_ip, &id, 0);
if (ret != 0) {
return 1;
}
ret = rpp_setup_buffers(id);
if (ret != 0) {
goto out;
}
/* regisger for first recieve */
DEBUG_LOG("rdma_post_recv\n");
ret = rdma_post_recv(id, NULL, &recv_buf, sizeof(recv_buf), recv_mr);
if (ret != 0) {
perror("rdma_post_recv");
goto out;
}
DEBUG_LOG("rdma_connect\n");
ret = rdma_connect(id, NULL);
if (ret != 0) {
perror("rdma_connect");
goto out;
}
for(i = 0; i < count; i++) {
/* prepare data for RDMA READ */
if (work) {
if (i == 0)
do_client_init((double *)read_data, dsize, 10);
else
do_client_work((const double *)write_data, (double *)read_data, dsize);
} else {
sprintf(read_data, "%04d", i); /* XXX assume data_size is large enough */
strcat(read_data, "aaa"); /* ditto */
}
send_buf.buf = (uint64_t)read_data;
send_buf.rkey = read_mr->rkey;
send_buf.size = data_size;
/* send buffer info to server */
ret = rpp_rdma_send(id);
if (ret != 0) {
goto out;
}
/* recieve go ahead from server */
ret = rpp_rdma_recv(id);
if (ret != 0) {
goto out;
}
/* prepare data for RDMA WRITE */
send_buf.buf = (uint64_t)write_data;
send_buf.rkey = write_mr->rkey;
send_buf.size = data_size;
/* send buffer info to server */
ret = rpp_rdma_send(id);
if (ret != 0) {
goto out;
}
/* recieve complete from server */
ret = rpp_rdma_recv(id);
if (ret != 0) {
goto out;
}
if (! work)
printf("RDMA WRITE data: %s\n", write_data);
}
if (work < 2)
printf("done\n");
else
do_full_print(write_data, dsize);
out:
rpp_free_buffers();
DEBUG_LOG("rdma_destroy_qp\n");
rdma_destroy_qp(id);
DEBUG_LOG("rdma_destroy_id\n");
if (rdma_destroy_id(id) != 0) {
perror("rdma_destroy_id");
}
return ret;
}
static void
usage(void)
{
fprintf(stderr, "usage: rpp_e -s data_size -r count {-s|-c} [-d] server-ip-address\n");
}
int main(int argc, char *argv[])
{
int opt;
char *server_ip;
int ret = 0;
data_size = 4096;
count = 16;
while ((opt = getopt(argc, argv, "csdwS:r:")) != -1) {
switch (opt) {
case 'c':
if (server == 1) {
usage();
return 1;
}
server = 0;
break;
case 's':
if (server == 0) {
usage();
return 1;
}
server = 1;
break;
case 'd':
debug = 1;
break;
case 'w':
work++;
break;
case 'S':
data_size = atoi(optarg);
break;
case 'r':
count = atoi(optarg);
break;
default:
usage();
return 1;
}
}
if (server == -1) {
usage();
return 1;
}
if (optind != argc - 1) {
usage();
return 1;
}
posix_memalign((void **)&read_data, 4096, data_size);
posix_memalign((void **)&write_data, 4096, data_size);
dsize = ((int)sqrt(data_size / sizeof(double)) / 8) * 8;
server_ip = argv[optind];
if (server) {
ret = run_server(server_ip);
} else {
ret = run_client(server_ip);
}
return ret;
}
以下は TCP 版である。何の変哲もないプログラムであるが参考のため。
tcp_pingpong.c (click to expand)
#include <getopt.h>
#include <math.h>
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <strings.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#include <netdb.h>
#include "work.h"
char *read_buf, *write_buf;
size_t buf_size;
int work = 0;
int count;
#define PROTO_MAGIC 0xdfa38def
struct proto_header {
uint32_t magic;
uint32_t count;
};
void
do_print1(const char *buf) {
int i;
const double *bp = (const double *)buf;
for(i = 0; i < 4096 / sizeof(double); i++) {
printf("%f ", *bp++);
if ((i % 16) == 15)
printf("\n");
}
}
void
do_print(const char *buf) {
do_print1(buf);
printf("\n");
do_print1(buf + buf_size - 4096);
}
void
do_client(int fd) {
int i, n, r, dsize;
struct proto_header hdr;
hdr.magic = PROTO_MAGIC;
hdr.count = count;
n = write(fd, &hdr, sizeof(hdr));
if (n != sizeof(hdr)) {
perror("write");
exit(1);
}
if (work) {
dsize = ((int)sqrt(buf_size / sizeof(double)) / 8) * 8;
do_client_init(write_buf, dsize, 10);
}
for(i = count; i; i--) {
for(n = 0; n < buf_size;) {
r = write(fd, write_buf + n, buf_size - n);
if (r < 0) {
perror("write");
exit(1);
}
n += r;
}
for(n = 0; n < buf_size;) {
r = read(fd, read_buf + n, buf_size - n);
if (r <= 0) {
perror("read");
exit(1);
}
n += r;
}
if (work)
do_client_work(read_buf, write_buf, dsize);
}
if (work > 1)
do_full_print(read_buf, dsize);
else
do_print(read_buf);
}
void
do_server(int sfd) {
int i, n, r, dsize;
int fd;
struct sockaddr_un peeraddr;
socklen_t peeraddr_len;
struct proto_header hdr;
double *scratch = NULL;
if (listen(sfd, 5) < 0) {
perror("listen");
exit(1);
}
peeraddr_len = sizeof(peeraddr);
if ((fd = accept(sfd, (struct sockaddr *)&peeraddr, &peeraddr_len)) < 0) {
perror("accept");
exit(1);
}
n = read(fd, &hdr, sizeof(hdr));
if (n != sizeof(hdr)) {
perror("read");
exit(1);
}
if (hdr.magic != PROTO_MAGIC) {
fprintf(stderr, "Bad magic\n");
exit(1);
}
count = hdr.count;
if (work)
dsize = ((int)sqrt(buf_size / sizeof(double)) / 8) * 8;
for(i = count; i; i--) {
for(n = 0; n < buf_size;) {
r = read(fd, read_buf + n, buf_size - n);
if (r <= 0) {
perror("read");
exit(1);
}
n += r;
}
if (work)
do_server_work(read_buf, write_buf, &scratch, 1e-2, dsize);
for(n = 0; n < buf_size;) {
r = write(fd, write_buf + n, buf_size - n);
if (r < 0) {
perror("write");
exit(1);
}
n += r;
}
}
}
int
main(int argc, char **argv) {
int opt;
int client = 0, server = 0;
struct addrinfo *result;
char *p;
int fd, n;
buf_size = 0;
while ((opt = getopt(argc, argv, "cswC:S:")) != -1)
switch (opt) {
case 'c':
client = 1;
break;
case 's':
server = 1;
break;
case 'w':
work++;
break;
case 'C':
count = atoi(optarg);
break;
case 'S':
buf_size = atoi(optarg);
break;
default:
fprintf(stderr, "Usage: %s {-c|-s} -C count -S size host:port\n",
argv[0]);
exit(1);
}
argc -= optind;
argv += optind;
if (argc < 1) {
fprintf(stderr, "Expected host:port\n");
exit(1);
}
posix_memalign(&read_buf, 4096, buf_size);
posix_memalign(&write_buf, 4096, buf_size);
p = rindex(argv[0], ':');
if (p == NULL) {
fprintf(stderr, "Missing port\n");
exit(1);
} else {
*p = '\0';
p++;
}
n = getaddrinfo(argv[0], p, NULL, &result);
if (n != 0) {
fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(n));
exit(1);
}
fd = socket(result->ai_family, result->ai_socktype, result->ai_protocol);
if (fd < 0) {
perror("socket");
exit(1);
}
if (client) {
if (connect(fd, result->ai_addr, result->ai_addrlen) < 0) {
perror("connect");
exit(1);
}
do_client(fd);
} else if (server) {
int one = 1;
if (setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &one, sizeof(one)) < 0)
perror("setsockopt");
if (bind(fd, result->ai_addr, result->ai_addrlen) < 0) {
perror("bind");
exit(1);
}
do_server(fd);
} else {
fprintf(stderr, "Either -c or -s must be specified\n");
exit(1);
}
}
ここからは、以下のパラメータを変動させて性能の変化を見ていく。測定は特記ない限り 3セット行った。
以下の表の時間は time コマンドで測定した (3 * 並列度) 回の平均値である。(単位は秒)
- トランスポート (実行するプログラム)
- バッファサイズ (
-Sオプション) - 繰り返し回数 (
-rまたは-Cオプション) - 計算の有無 (
-wオプション) - 並列度 (ポート番号を変えてサーバおよびクライアントを同時に起動)
| トランスポート | 計算 | バッファサイズ | 繰り返し回数 | 並列度 | client real | client user | client sys | server user | server sys |
|---|---|---|---|---|---|---|---|---|---|
| RDMA | あり | 4194304 | 2500 | 1 | 7.412 | 1.240 | 0.171 | 2.520 | 0.056 |
| RDMA | あり | 4194304 | 2500 | 2 | 11.038 | 1.724 | 0.130 | 2.770 | 0.093 |
| RDMA | あり | 4194304 | 2500 | 4 | 17.412 | 3.068 | 0.076 | 3.073 | 0.100 |
| RDMA | なし | 4194304 | 2500 | 1 | 4.435 | 0.175 | 0.281 | 0.190 | 0.196 |
| RDMA | なし | 4194304 | 2500 | 2 | 5.386 | 0.275 | 0.252 | 0.213 | 0.207 |
| RDMA | なし | 4194304 | 2500 | 4 | 7.821 | 0.245 | 0.249 | 0.190 | 0.218 |
| RDMA | あり | 1048576 | 10000 | 1 | 6.616 | 1.122 | 0.109 | 2.116 | 0.145 |
| RDMA | あり | 1048576 | 10000 | 2 | 7.863 | 1.615 | 0.093 | 2.183 | 0.141 |
| RDMA | あり | 1048576 | 10000 | 4 | 7.652 | 1.599 | 0.077 | 1.647 | 0.115 |
| RDMA | あり | 1048576 | 10000 | 8 | 14.718 | 2.935 | 0.175 | 1.979 | 0.138 |
| RDMA | なし | 1048576 | 10000 | 1 | 3.618 | 0.061 | 0.070 | 0.159 | 0.196 |
| RDMA | なし | 1048576 | 10000 | 2 | 3.910 | 0.074 | 0.073 | 0.169 | 0.192 |
| RDMA | なし | 1048576 | 10000 | 4 | 6.257 | 0.066 | 0.075 | 0.110 | 0.140 |
| RDMA | なし | 1048576 | 10000 | 8 | 12.841 | 0.146 | 0.143 | 0.101 | 0.119 |
| RDMA | あり | 262144 | 40000 | 1 | 6.508 | 1.257 | 0.186 | 1.405 | 0.296 |
| RDMA | あり | 262144 | 40000 | 2 | 7.430 | 1.581 | 0.221 | 1.433 | 0.329 |
| RDMA | あり | 262144 | 40000 | 4 | 9.367 | 1.898 | 0.276 | 1.506 | 0.325 |
| RDMA | なし | 262144 | 40000 | 1 | 4.579 | 0.291 | 0.280 | 0.288 | 0.409 |
| RDMA | なし | 262144 | 40000 | 2 | 5.618 | 0.424 | 0.404 | 0.268 | 0.475 |
| RDMA | なし | 262144 | 40000 | 4 | 7.417 | 0.289 | 0.298 | 0.302 | 0.450 |
| TCP | あり | 4194304 | 2500 | 1 | 9.427 | 0.899 | 4.923 | 1.875 | 5.126 |
| TCP | あり | 4194304 | 2500 | 2 | 10.830 | 1.034 | 6.712 | 1.876 | 5.381 |
| TCP | あり | 4194304 | 2500 | 4 | 17.676 | 2.319 | 10.833 | 2.168 | 5.617 |
| TCP | なし | 4194304 | 2500 | 1 | 6.396 | 0.015 | 3.940 | 0.006 | 4.239 |
| TCP | なし | 4194304 | 2500 | 2 | 7.701 | 0.019 | 5.671 | 0.005 | 4.496 |
| TCP | なし | 4194304 | 2500 | 4 | 12.500 | 0.026 | 9.108 | 0.014 | 4.599 |
| TCP | あり | 1048576 | 10000 | 1 | 10.887 | 0.474 | 4.343 | 1.417 | 5.407 |
| TCP | あり | 1048576 | 10000 | 2 | 11.897 | 0.820 | 5.189 | 1.346 | 5.085 |
| TCP | あり | 1048576 | 10000 | 4 | 16.817 | 1.696 | 9.079 | 1.510 | 5.379 |
| TCP | あり | 1048576 | 10000 | 8 | 29.408 | 2.353 | 11.684 | 1.870 | 5.657 |
| TCP | なし | 1048576 | 10000 | 1 | 8.805 | 0.022 | 3.797 | 0.013 | 4.709 |
| TCP | なし | 1048576 | 10000 | 2 | 9.402 | 0.046 | 5.936 | 0.014 | 4.622 |
| TCP | なし | 1048576 | 10000 | 4 | 13.118 | 0.051 | 7.484 | 0.023 | 4.714 |
| TCP | なし | 1048576 | 10000 | 8 | 22.877 | 0.050 | 10.305 | 0.035 | 4.873 |
| TCP | あり | 262144 | 40000 | 1 | 13.731 | 0.490 | 3.886 | 0.966 | 4.315 |
| TCP | あり | 262144 | 40000 | 2 | 15.007 | 0.520 | 4.458 | 0.864 | 4.456 |
| TCP | あり | 262144 | 40000 | 4 | 18.499 | 0.626 | 5.549 | 0.914 | 4.659 |
| TCP | なし | 262144 | 40000 | 1 | 13.175 | 0.046 | 3.508 | 0.026 | 3.972 |
| TCP | なし | 262144 | 40000 | 2 | 13.979 | 0.063 | 4.130 | 0.052 | 4.256 |
| TCP | なし | 262144 | 40000 | 4 | 17.554 | 0.066 | 5.216 | 0.048 | 4.398 |
いずれの設定でもプロセス1組 (サーバとクライアント) あたり双方向に 10.48GB 通信する。 従って双方向の合計の帯域(GB/s)は 2 * 10.48 * (並列度) / (client real) で計算できる。 (全プロセスが同時に終了するわけではないので若干不正確である。)
計算なしの各測定での帯域をグラフにすると以下のようになる。
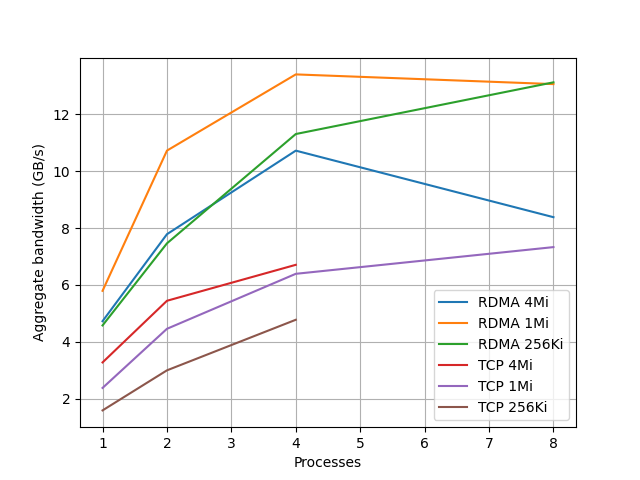
- RDMA はバッファサイズ 1MiB が速く、TCP では 4MiB が速い
- 4並列までは並列度に従って帯域が増えるが、8 並列にしてもあまり増えない (Core i5-6500 が 4コアであることに関係があるかもしれない)
- RDMA バッファサイズ 4Mi は 8 並列で2割くらい性能が落ちていて謎である
- iperf と qperf での片方向のみ測定が最大で 7GB/s 程度であったことを思い出すと、RDMA では双方向に 7GB/s に近い帯域が出るものの、TCP では双方向に通信させても合計帯域は増えていない。(ark.intel.com によると CPU のメモリ帯域は 34.1 GB/s なのでもうちょっと出てもいい気もするが、メモリ帯域ではなくて他が制約になっているのかもしれない)
同様に計算ありでの帯域を計算して以下のグラフにした。
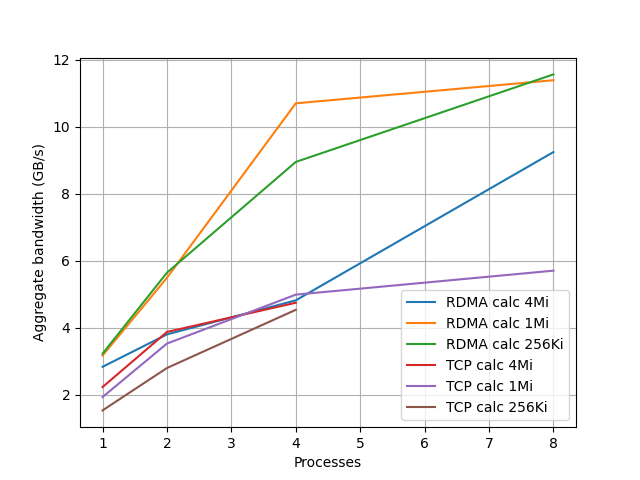
- バッファサイズ 4Mi では RDMA、TCP の差がほとんどない
- それ以外の場合では、計算なしの時と同様 RDMA と TCP は大きな差がついている
計算の有無での client real の秒数の差を計算によるオーバーヘッドとみなして、この差をグラフにすると以下のようになる。
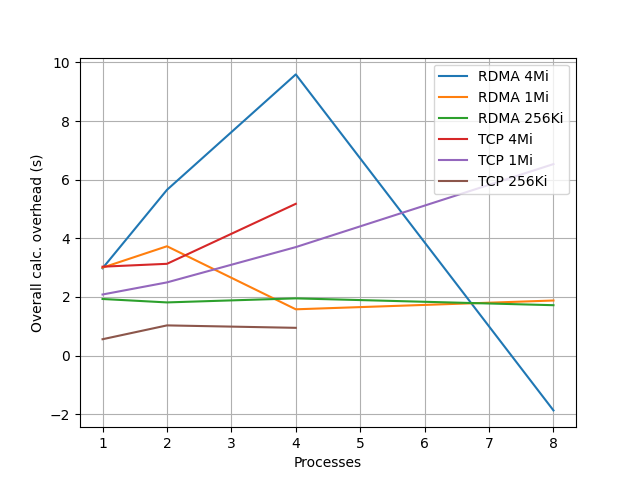
全般的に、他の条件が同一であれば、1 Mi 4並列以上の場合を除き、オーバーヘッドは TCP のほうが RDMA より小さい。TCPの方が小さいのは、カーネルがデータコピーするためにキャッシュに載った状態から計算を始められるのが原因であると思われる。 RDMA ではいくつか不思議な結果がでていて、バッファサイズ 1Mi では並列度 2 → 4 でオーバーヘッドが減少している。(並列度2と4で測定をやりなおしたのだが同様の結果となった。これらについては6セットの測定の平均値をプロットしてある。) また、 4Mi では、計算したほうが速いという不思議な結果になっている。
計算ありの場合の client user 時間のグラフを下に示す。
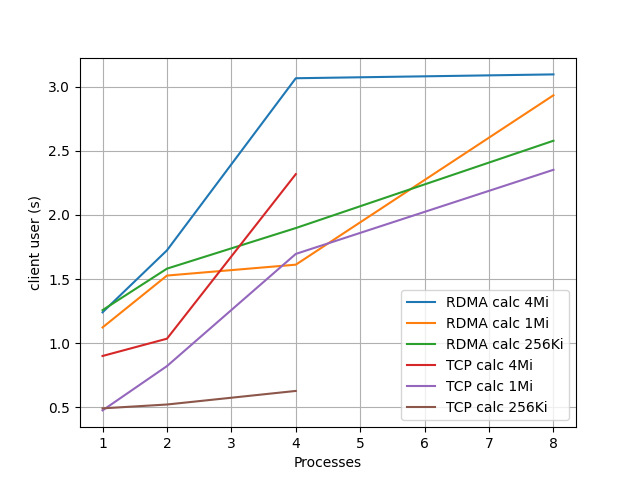
これはほぼ memcpy の時間なので、キャッシュサイズに依存して、アクセスするメモリ総量に応じて遅くなっているようにもみえる。 TCP のほうが速いのはカーネルの時間を使ってキャッシュに載せているからであろう。
サーバ側の user 時間は以下のようであり、一応簡単な計算をしていることもあり、 client ほど差は開いていないが、先程の RDMA 1Mi での並列度 2 → 4 での時間減少がここでも見られる。
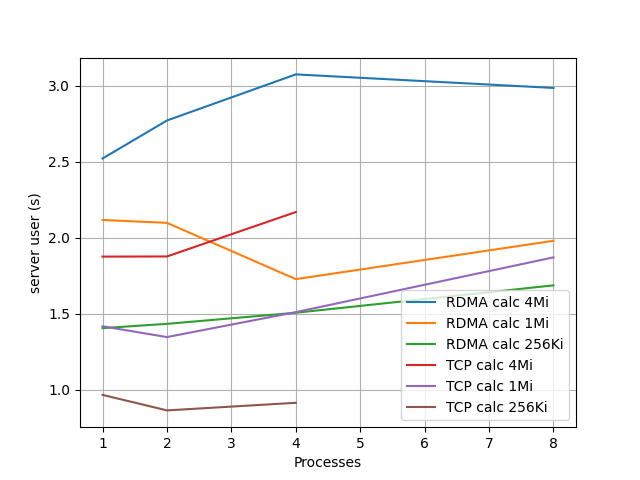
RDMA のときの sys 時間はとても少ないので省略して、 TCP の場合のクライアント、サーバ側の sys 時間を下に示す。
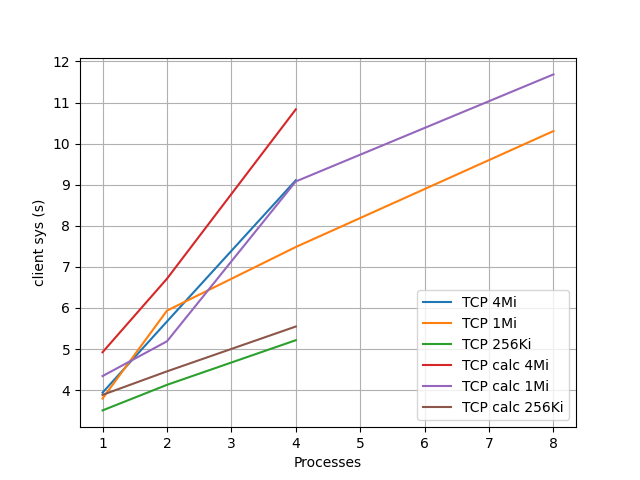
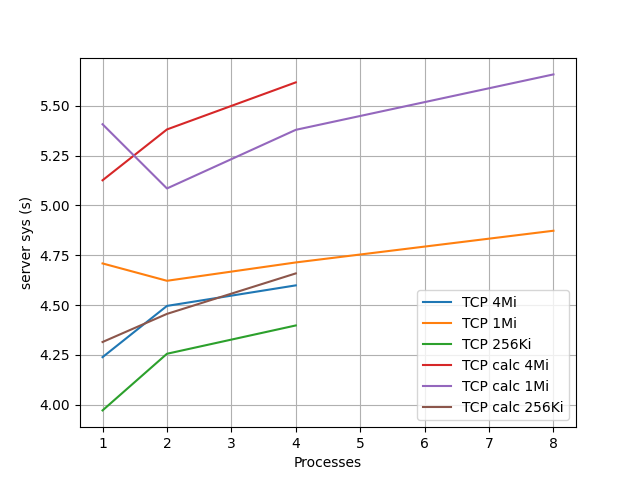
計算ありのほうが余計に時間がかかって、バッファサイズが大きいほうが余計に時間がかかっていて、キャッシュのことを考えればまあそういうものかという気もするが、クライアント側だけ並列度が上がると時間が増えているのがとても気になる。 perf コマンドで様子を見てみたが、8並列では mlx5e_skb_from_cqe_nonlinear の所要時間が増えているが、これだけではこの大きな差を説明できるものではなく、謎がかえって深まった。
perf report 出力 (click to expand)
8並列
# Overhead Command Shared Object Symbol
# ........ ............ ................. .....................................................
#
40.62% tcp_pingpong [kernel.kallsyms] [k] copy_user_enhanced_fast_string
16.00% tcp_pingpong [kernel.kallsyms] [k] clear_page_erms
6.59% tcp_pingpong [kernel.kallsyms] [k] mlx5e_skb_from_cqe_nonlinear
4.80% tcp_pingpong [kernel.kallsyms] [k] __check_object_size
1.91% tcp_pingpong [kernel.kallsyms] [k] free_pcppages_bulk
1.72% tcp_pingpong [kernel.kallsyms] [k] get_page_from_freelist
1.68% tcp_pingpong [kernel.kallsyms] [k] rmqueue
1.52% tcp_pingpong [kernel.kallsyms] [k] __skb_datagram_iter
1.03% tcp_pingpong [kernel.kallsyms] [k] mlx5e_post_rx_wqes
1.01% tcp_pingpong [kernel.kallsyms] [k] skb_release_data
2並列
# Overhead Command Shared Object Symbol
# ........ ............ ................. .....................................................
#
46.01% tcp_pingpong [kernel.kallsyms] [k] copy_user_enhanced_fast_string
19.73% tcp_pingpong [kernel.kallsyms] [k] clear_page_erms
3.95% tcp_pingpong [kernel.kallsyms] [k] __check_object_size
2.07% tcp_pingpong [kernel.kallsyms] [k] __skb_datagram_iter
1.98% tcp_pingpong [kernel.kallsyms] [k] free_pcppages_bulk
1.65% tcp_pingpong [kernel.kallsyms] [k] skb_release_data
1.17% tcp_pingpong [kernel.kallsyms] [k] ipt_do_table
1.11% tcp_pingpong [kernel.kallsyms] [k] _copy_to_iter
1.03% tcp_pingpong [kernel.kallsyms] [k] rmqueue
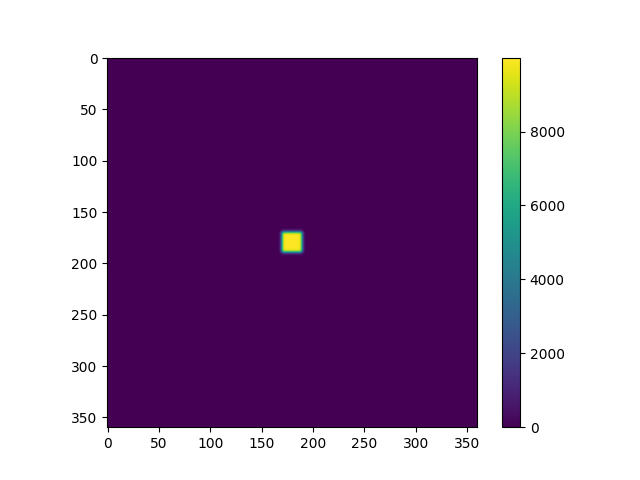
おまけに、拡散方程式の計算結果を示す。繰り返し数 100回と 10000回の場合について、2次元の図と、領域の中心を通る x軸 (または y軸) に平行な線に沿う値をグラフにしたものを示す。 それっぽい結果になっているように思われる。 また RDMA と TCP の場合の結果が一致することも確認できた。
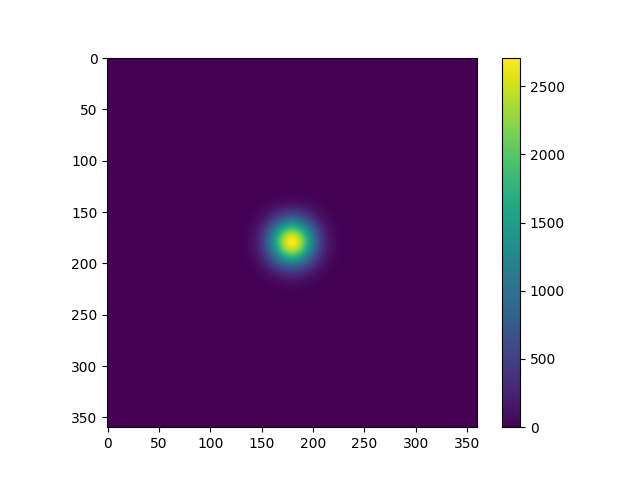
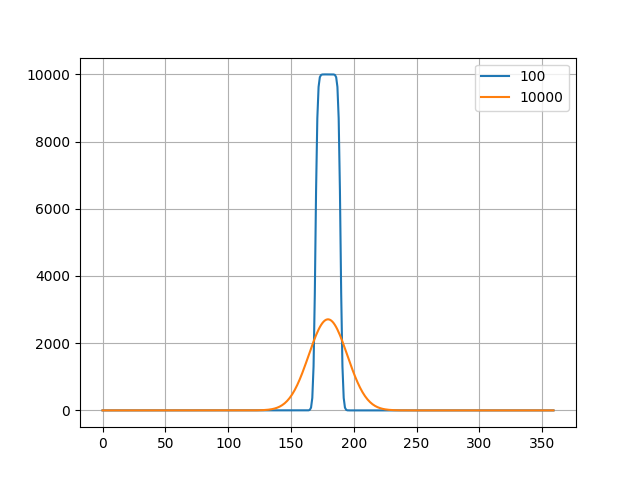
まとめ
キャッシュの効果を期待して、計算ありにすると RDMA と TCP の差がもっと縮むかと思っていたのだが、順当に RDMA の効果を確認する結果となった。 また、100Gbps ともなると PC の各種帯域の限界に近づいてくるのでなかなか性能を出し切ることが難しいと思った。
他にも、
- NFS の transport に RDMA を使って NFS のベンチマークを流す
- OpenStack を入れて OVS offloading してみる
などの遊び方も考えたものの準備が大掛かりになりそうなので今回は行わなかった。 また、スイッチも物によっては中古で安く買えるようなので 3台以上でおもしろそうな実験を思い付いたらやってみたい。