執筆者:佐藤友昭
※ 「vLLMとRDMAで構築するローカルLLMクラスタ」連載記事一覧はこちら
ここまでのまとめ
本連載は、コストパフォーマンスを重視した「LM 分散実行」というユースケースの紹介を目的としている。その中でこのユースケースにあると便利そうな「NFS ストレージ」の形を探っていく。これまでの4回で LM 分散実行について書いてきた。今回以降で NFS ストレージについて書いていきたい。現時点でこの NFS ストレージには2つの特徴がある。(1)HDD ベースであることと(2)GPU を搭載していること。HDD の方はすでに使用しているが、GPU の方はまだ使用していない。今回は NFS ストレージ上で Open-WebUI を動作させ、2つの性質のナレッジ(RAG)を構築する。次回以降では LM 分散実行環境に(モデルに加えて)ナレッジを供給し、推論エンジンとして利用することで、より大きなモデルでより高速にナレッジ(RAG)を使用できるというストーリーにしたい。 これまでの4回では「より大きなモデルでより高速に」という部分について Linux PC を用いて1ノードから4ノードまでのスケーラビリティを紹介してきた。
機材の変更
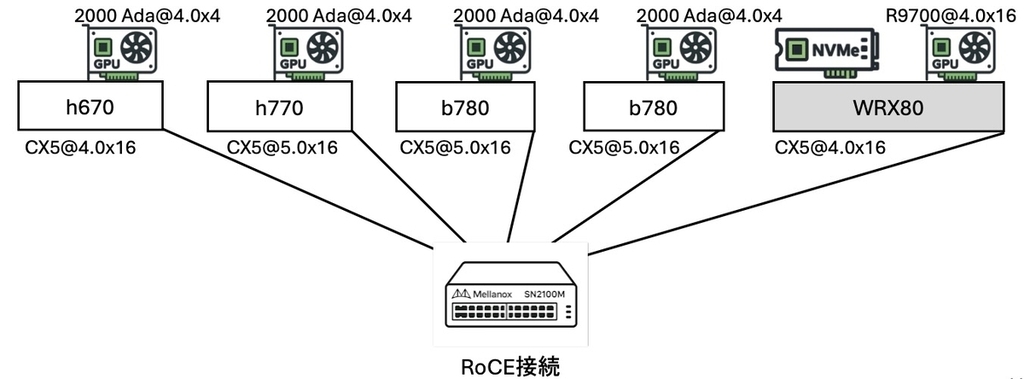
今回、GPU を NVIDIA RTX 4000 Ada GPU からより低価格な RTX 2000 Ada に変更した。それ以外は前回からの変更はない。GPU1台の VRAM 容量が 20GB から 16GB に減っている。これまでと同様の測定を実施したところ、Llama-3-8B、Llama-3.1-8Bモデルが1ノードでは実行できなかった(=実行に2ノード必要だった)が、それ以外は全てのモデルが動作した。ベンチマーク結果の詳細は省略するが、肝心なスケーラビリティに関する値を紹介すると、4ノードでのみ実行可能なサイズのモデル(gpt-neox-20b)のTP数 1, 2, 4 での平均トークン/秒の値は 4.63, 8.74, 15.39 となった。15.39 ÷ 4.63 = 3.32 と、RTX 4000 Ada での 3.25 に劣らぬスケーラビリティである。 平均トークン/秒の値に関しては、全体的に RTX 4000 Ada と RTX 2000 Ada のメモリ帯域幅の比率ぐらいの印象である。1/2 程度の実売価格でこの性能が得られるのであれば RTX 2000 Ada は本連載の主旨によりマッチしていると言える。 RTX 2000 Ada のメモリ帯域幅はカタログに 224GB/s とある。DGX Spark のメモリ帯域幅はカタログに 273GB/s とある。Blackwell 世代の DGX Spark 4台の場合、どの程度のスケーラビリティが得られるのか大変興味がある。機会があれば(そんな機会はないだろうけど)是非試してみたい。 先日 YouTube で、Mac Studio 4台による exo を用いた LM 分散実行の様子を見た。最新の MacOS と最新の exo の組み合わせでは、RDMA/Thunderbolt-5 を介したテンソルパラレル実行が利用でき、ノード数が増えるほど大きなモデルを高速に実行できるようである。こちらのスケーラビリティにも大変興味がある。
NFS ストレージにナレッジ(RAG)を置く
本連載では LM 分散実行環境で共有するナレッジのパターンとして大量のテキストファイルと大規模なコードベースを取り上げたい。ローカル LLM を選択する実際のユースケースではクローズドなデータが対象となると思われるが、連載の都合上、オープンなデータを題材に選択する。
大量のテキストファイル
登録 YouTube チャネルに日々集まるコンテンツの中から実際に視聴するものを選択するためのナレッジ「YouTube Monitoring ナレッジ」を構築する。KB単位の文字起こしテキストファイルがおよそ1万ファイルある。最初は(NFS ストレージではなく)Open-WebUI が動作するホスト(=NFSクライアント)側で毎日テキストファイルをナレッジに登録していたが、だんだん登録に時間が掛かるようになってきた。また、ナレッジ検索にも時間がかかるようになってきた。そこで Open-WebUI ごと NFS ストレージ側に移動したところナレッジ登録も検索も応答性が多少改善したが、根本的にファイル数が多すぎるようである。 そこでファイル数を減らすために1個のファイルに複数のコンテンツを格納するようにした(=全 10,206 ファイルを 206 ファイルに統合した)ところ4時間程でナレッジ登録と検索ができるようになった。現在のところ、1ファイルあたり1メガバイトとしている。1メガバイトが最適なサイズかどうかは分からない。登録に要する時間は1ファイルあたり 65 秒程度で一定だった。この時点でのストレージ消費は以下の状況。
tsato@p620:~$ du -sh /combined_storage/open_webui_data/* 7.9G /combined_storage/open_webui_data/cache 25K /combined_storage/open_webui_data/chroma.sqlite3 512 /combined_storage/open_webui_data/readme.txt 512 /combined_storage/open_webui_data/testfile 124M /combined_storage/open_webui_data/uploads 4.6G /combined_storage/open_webui_data/vector_db 130M /combined_storage/open_webui_data/webui.db tsato@p620:~$
大規模なコードベース
Linux カーネルコードのスナップショットに対して自然言語で問い合わせをするためのナレッジ「Linux Kernel ナレッジ」を構築する。こちらもソースツリーそのままだとファイル数が多すぎるので、1メガバイトのファイルとして(=全 69,925 ファイルを 897 ファイルに統合して)いる。同じく1メガバイトが最適なサイズかどうかは分からない。28時間程度でナレッジ登録と検索ができるようになるが、1つのスナップショットに1つのナレッジという状態であり、改善の余地は大いにある。 登録に要する時間は1ファイルあたり 40〜55 秒程度で一定だった。この時点でのストレージ消費は以下の状況。
tsato@p620:~$ du -sh /combined_storage/open_webui_data/* 7.9G /combined_storage/open_webui_data/cache 25K /combined_storage/open_webui_data/chroma.sqlite3 512 /combined_storage/open_webui_data/readme.txt 512 /combined_storage/open_webui_data/testfile 495M /combined_storage/open_webui_data/uploads 25G /combined_storage/open_webui_data/vector_db 494M /combined_storage/open_webui_data/webui.db tsato@p620:~$
NFS ストレージの GPU
以前に「最近は AMD Radeon AI PRO R9700 (32GB) や Intel Arc Pro B60 (24GB) といった、1GB あたりの価格が NVIDIA GPU に比べて格段に安い GPU が登場している。GPU 単体での購入はできないのかもしれないが、機会があれば是非これらも試してみたい。」と記述したが、今回 NFS ストレージには AMD Radeon AI PRO R9700 (32GB) を選択した。eBay 購入時の価格は $1700 程度だった。RTX 5090 (32GB)などに比べればかなり安価なのではないだろうか。さらに安価であろう Intel Arc Pro B60 (24GB) も是非試してみたい。 NFS ストレージに GPU があると GPU を利用したナレッジ登録や検索が NFS ストレージ単体で可能になる。今回エンべディングモデルの実行は ollama をエンジンに bge-m3 をモデルに選択した。この選択が最適かどうかは分からない。なお、Open-WebUI デフォルトの SentenceTransformers エンジンで BAAI/bge-m3 モデルに選択した場合、AMD GPU が利用されなかった。NVIDIA GPU の環境ではコンテナイメージを open-webui:main から open-webui:cuda に変更することで NVIDIA GPU が利用されるようになったが、AMD GPU の環境向けのコンテナイメージの存在は確認できなかった。その他の Open-WebUI の「ドキュメント」設定項目でのチューニングが実際の運用には必要そうであるが、今回は省略する。今回、ハイブリッド検索およびリランクモデルは使用しない設定(デフォルト設定のまま)である。 LM 分散実行環境のユーザは個々のノードでの CLI による操作を基本とし、ナレッジを利用する場合には Web ブラウザから Open-WebUI に接続し、ナレッジ登録や検索を行うことを想定する。このとき推論エンジンとして LM 分散実行環境を使用する(=Open-WebUI から OpenAI API で LM 分散実行環境の vLLM/Ray に接続する)ことで「より大きなモデルでより高速にナレッジ(RAG)を使用」できることを目指す。
ナレッジ(RAG)の動作確認
今回の場合、オープンなデータが題材なので notebookLM を利用して手短に動作確認用のクイズを作成してもらう。notebookLM のノートブックには 300 個までソースを登録できるようなので、各ナレッジに登録したファイル群を 300 個に分割しなおしてノートブックに登録し、以下のプロンプトを実行した。
RAGの動作確認のため、プロンプトを10個生成してほしい それぞれについて期待される回答も添えてほしい
Open-WebUI を操作し、ollama 上の任意のモデルと上記で作成した 「YouTube Monitoring ナレッジ」、「Linux Kernel ナレッジ」を組み合わせた 「YouTube Monitoring モデル」、「Linux Kernel モデル」を作成する。このときシステムプロンプトは個別に指定できる。次に Open-WebUI の新規チャットでそれぞれを指定し、notebookLM が生成したクイズ10問を1問ずつ出題する。最後にチャットをテキストファイルでダウンロードする。このテキストファイルを Cursor に指定して 100 点満点で採点してもらい、相性のよさそうなollama 上のモデルを選択する。 現段階では ollama 上のモデルの生成品質には拘らず、ナレッジの動作確認のみを行う。コンテキストサイズを 128K に設定した gpt-oss:20b と gpt-oss:120b のみ試したが、20b と 120b の結果は一長一短という感じだった。両者の結果を総合してナレッジ動作は確認できたと判断する。業種やデータの性質によって最適なモデルは違うのだろう。
「YouTube Monitoring ナレッジ」クイズ(最初の3題)
| 番号 | 質問 | 正解(期待される回答) | gpt-oss-20b_128K | gpt-oss-120b_128K |
|---|---|---|---|---|
| 1 | 「Nano Banana」とは何ですか? | Googleの新しい画像生成・編集モデル「Gemini 2.5 Flash Image」のコードネームまたは別名。以前は「Nano Banana」と呼ばれており、画像編集やインフォグラフィックの生成、キャラクターの一貫性保持などに優れている。 | Googleが開発した画像生成モデルで、Gemini 2.5 Flashをベース。高解像度(最大4K)、複数オブジェクト(最大14個)を組み合わせ可能。テキストプロンプトで画像を作成・編集、キャラクターや商品の一貫性を保持。チェーン・オブ・ソートを使用。 ✅ | Googleが提供するAI画像編集・生成モデル。正式名称はGemini 2.5 Flash、2025年8月26日リリース。テキストプロンプトや画像のドラッグ&ドロップで画像編集可能。Nano Banana Proでは4Kまでの高解像度画像生成やGoogle検索を利用したグラウンディング機能。 ✅ |
| 2 | 「Vending Bench 2」におけるGemini 3 Proの成果について教えてください。 | 自動販売機ビジネスをシミュレーションするベンチマーク「Vending Bench 2」において、Gemini 3 Proは元手500ドルを5000ドル以上(約10倍)に増やし、他のモデル(Claude Sonnet 4.5やGrok 4など)を圧倒する最高のROI(投資対効果)を記録。 | Gemini 3 ProはVending Bench 2で最も高いリターンを達成。1年間にわたって仮想の自動販売機ビジネスを実行し、数百件の意思決定を行うベンチマークで、他のフロンティアモデルをすべて上回る収益を上げ、最高のパフォーマンスを示した。 ✅ | Gemini 3 ProはVending Bench 2で圧倒的な成果。元手の$500が$4,967.06まで増加し、約10倍のROIを達成。Gemini 2.5 Proが$576の利益にとどまったのに対し、10倍以上のリターンを達成。長期間のシミュレーションでも最高のパフォーマンスを維持。 ✅ |
| 3 | Googleが発表した「Anti-Gravity」とはどのようなツールですか? | Googleが発表した新しい「エージェンティック開発プラットフォーム」またはIDE(統合開発環境)。VS Codeのフォークであり、CursorやWindsurfに対抗するツールとして、開発者がAIエージェントを使ってコーディング、テスト、デプロイを行うことを支援。 | Anti-GravityはGoogle DeepMindが開発した「agentic」開発プラットフォーム。IDEはVS Codeをベース。Geminiを組み込み、自然言語でコードを書いたり、タブ自動補完やコンテキストに応じたエージェント機能を提供。ローカルで動作。 ✅ | 提供された資料の中には「Anti-Gravity」についての記述がありません。 ❌ |
「Linux Kernel ナレッジ」クイズ(最初の3題)
| 番号 | 質問 | 正解(期待される回答) | gpt-oss-20b_128K | gpt-oss-120b_128K |
|---|---|---|---|---|
| 1 | tools/perf ディレクトリ内で、ftrace機能の組み込みコマンドに関連するCソースファイルの名前は何ですか? |
tools/perf/builtin-ftrace.c |
tools/perf/src/report/ftrace.c ❌ |
tools/perf/builtin-ftrace.c ✅ |
| 2 | Btrfsファイルシステムのロック機構の実装が含まれていると思われるCファイルのパスを教えてください。 | fs/btrfs/locking.c |
fs/btrfs/lock.c ❌ |
fs/btrfs/locking.c ✅ |
| 3 | BroadcomのTG3イーサネットドライバのメインソースファイルとヘッダーファイルのパスは何ですか? | ソース: drivers/net/ethernet/broadcom/tg3.cヘッダー: drivers/net/ethernet/broadcom/tg3.h |
コンテキストに含まれていない ❌ | ソース: drivers/net/ethernet/broadcom/tg3.cヘッダー: drivers/net/ethernet/broadcom/tg3.h ✅ |
次回は、Open-WebUI の推論エンジンとして LM 分散実行環境を使用する(=Open-WebUI から OpenAI API で LM 分散実行環境の vLLM/Ray に接続する)ことでシステムとして「より大きなモデルでより高速にナレッジ(RAG)を使用」できるかを試してみたい。
タイトルの変更
「AI特需に対応: 安価なGPUの可能性」というタイトルから「vLLMとRDMAで構築するローカルLLMクラスタ」に変更した。正直、PC 部材の価格高騰がここまでになるとは予測していなかった。「AI特需に対応」という看板は下すことにした。 今回、eBay 等を駆使して構築した検証環境の購入金額を勘定したところ、総額で ¥260 万程度だった。これは GPU と ConnectX-5 を搭載した PC/WS 6 台と 100GbE スイッチ、ケーブル等から成るが、うち増設メモリ 224GB 分の購入金額は ¥11 万程度である。現時点(2025年末)で、この量の増設メモリを購入しようとしたら幾らかかるだろうか。
「AI特需に対応: 安価なGPUの可能性」というタイトルははてなブログの AI が勧めてきたものの一つであるが、11 月末に別の AI (Gemini 3 Pro) に連載を読んでもらって指摘を求めたところ、タイトルがよくないと言われた。
現在のタイトル(例:「AI特需に対応: 安価なGPUの可能性 (1)」)は、シリーズ名としては綺麗ですが、検索結果やSNSのタイムラインで見た時に「具体的な技術情報」が伝わりにくいです。エンジニアは「技術名」や「解決したい課題」で検索します。
上述の状況もあり、内容に合ったタイトルに変更した。