「Linuxカーネル2.6解読室」(以降、旧版)出版後、Linuxには多くの機能が追加され、エンタープライズ領域をはじめとする様々な場所で使われるようになりました。 それに伴いコードが肥大かつ複雑化し、多くのエンジニアにとって解読不能なブラックボックスとなっています。 世界中のトップエンジニア達の傑作であるLinuxカーネルにメスを入れ、ブラックボックスをこじ開けて、時に好奇心の赴くままにカーネルの世界を解読する「新Linuxカーネル解読室」プロジェクト。
本稿では、ネットワーク機能のUDPレイヤーの受信処理ついてカーネルv6.8のコードをベースに解説します。
執筆者 : 須田 哲志、矢野 安希子、稲葉 貴昭
※ 「新Linuxカーネル解読室」連載記事一覧はこちら
はじめに
前回はIPレイヤーにおけるパケットの受信処理(ルーティング処理)について解説しました。 今回は、その続きとなるUDPレイヤーの処理について解説していきます。 まずは、いつも通りパケットの受信処理全体を概観してみましょう。


前回までで、図中の⑦、すなわち「L4(UDP) Processing」に入るところまでを解説しました。 今回は⑦、⑧の部分について解説していきます。 また、図0-1からもわかる通り、今回の記事で「ソフト割り込みコンテキスト」における処理の解説も完結します。
1. 概要
パケットの受信処理において、UDPレイヤーでは一体どんな仕事をしているんでしょうか。
UDPレイヤーでは、受信パケットのUDPソケットへの紐付けを行っています。 そのためには、前提としてソケットが特定できている必要があります。
つまり、UDPレイヤーでは主に以下の2つの処理を行っています。
- ソケット(sock構造体)の特定
(図0-1の⑦~⑧の処理) - 受信パケットのソケットへの配送
(図0-1の⑧以降の処理)
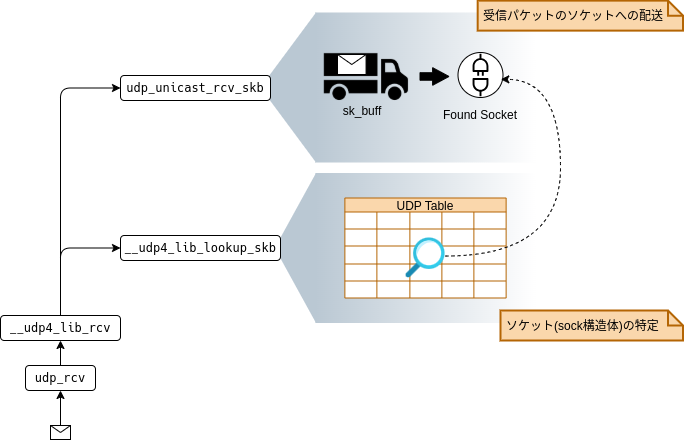

以降ではこれら2つの処理について解説していきます。
2. ソケット(sock構造体)の特定
本章では図0-1の⑦~⑧の処理、すなわち、udp_rcv~udp_queue_rcv_skbで行われるソケット(sock構造体)の特定/取得処理について解説します。
まずはudp_rcvからudp_queue_rcv_skbまで流れを見ていきましょう。
udp_rcv
└── __udp4_lib_rcv
├── inet_steal_sock // ①UDP Early Demultiplexer
├── __udp4_lib_lookup_skb // ②ソケットの特定/取得(本章の解説ターゲット)
└── udp_unicast_rcv_skb
└── udp_queue_rcv_skb // 次章で解説: 受信パケットのソケットへの配送
__udp4_lib_rcvでは以下のどちらかの処理(関数)でソケット(sock構造体)を取得した後、
udp_queue_rcv_skbを呼び出し、次章で解説するソケットへの受信パケットの配送処理に入ります。
inet_steal_sock
前回解説したUDP Early Demultiplexerにより、すでにソケット取得済みの場合に入る処理。 ここでは単純にUDP Early Demultiplexerで取得したソケットをそのまま利用します。__udp4_lib_lookup_skb
UDP Tableを用いて、UDPソケットの検索を行います。
本章では、__udp4_lib_lookup_skbの処理、すなわち、UDP TableからどのようにUDPソケットを探し出しているのか深堀りしていきます。
ただし、__udp4_lib_lookup_skbの解説に入る前に、まずはUDP Tableの構造から見ていきましょう。
2.1 UDP Tableの構造とbind(2)によるソケットの登録
前回の記事ではUDPソケットを特定するためのハッシュテーブルとして、UDP Tableを簡単に紹介しました。
本節ではまず、UDP Table(struct udp_table)の構造について詳しく見てみましょう。
UDP Tableは図2-1に示すとおり、hashとhash2という2つのハッシュテーブルを保持しています。*1
(正確には2つのハッシュテーブルへの「ポインタ」を保持しています。)


また、図2-1からもわかるとおり、ソケットはhashもしくはhash2のどちらかに登録されるのでなく、両方に登録されます。
ハッシュテーブルへのソケット登録タイミング
各ソケットは、bind(2)システムコールが発行されたタイミングでhashとhash2の両方に登録されます。
すなわち、hashとhash2で管理対象とするソケットは同一ということになります。
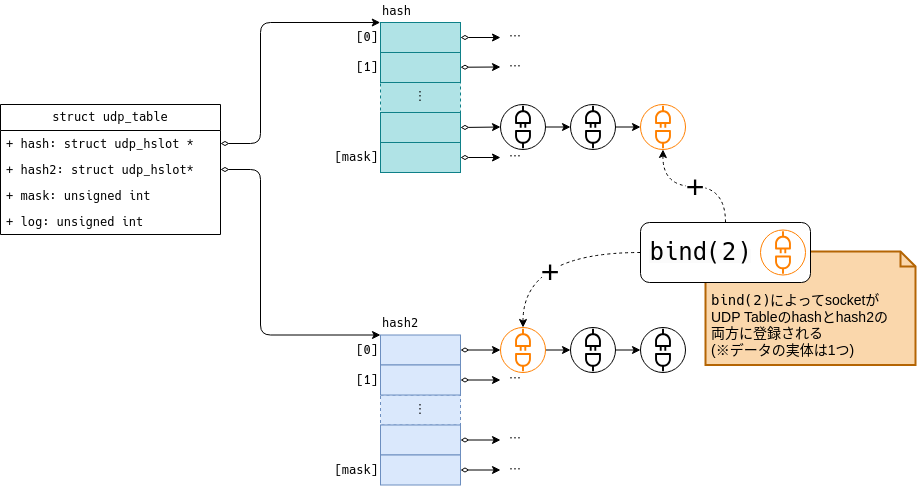

それでは、hashとhash2は一体何が違うのでしょうか。
hashとhash2の違い: 検索キー
まず、hashとhash2ではソケットを検索するための検索キーが異なります。
hashでは以下の2つの要素を検索キーとしています。
- Network Namespace
- 宛先ポート番号
一方、hash2は以下の3つの要素を検索キーとします。
- Network Namespace
- 宛先ポート番号
- 宛先IPアドレス
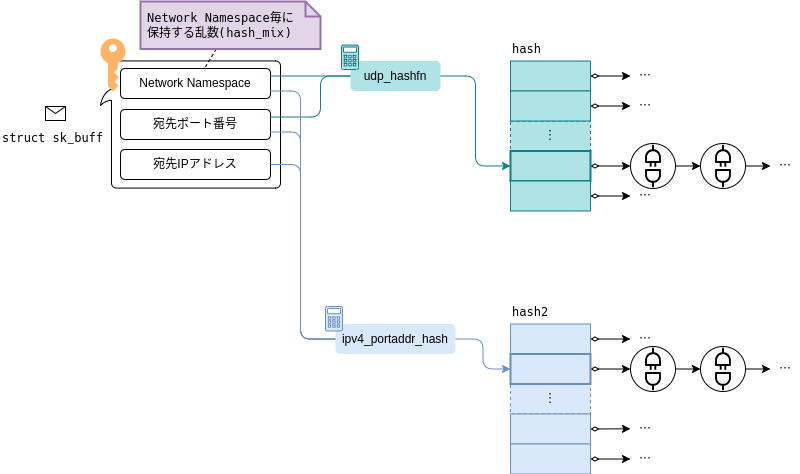

要するに、hash2はhashの検索キーに「宛先IPアドレス」を加えたものと言えます。
*2
これらの検索キーを用いて、それぞれハッシュテーブルのスロット(配列のインデックス)を特定しています。
なお、上記「Network Namespace」は、厳密にはNetwork Namespace毎に用意する乱数(hash_mix)のことを指します。
hashとhash2の違い: 用途
Linuxカーネルでは、処理によってhashとhash2を使い分けています。
hashは主にbind(2)時の空きポート探索やUDPソケットの統計情報の参照に利用されます。
具体的には/proc/net/udpで閲覧できる情報は、このhashテーブルをもとに出力されています。
一方でhash2は、同じくbind(2)時に参照される場合があるほか、UDPソケットの検索処理でも参照されます。
特にパケット受信時のソケット検索ではhash2が参照されるため、本稿ではこのhash2を中心に追っていきます。
UDP Tableの構造がわかったところで、次節では実際にどのようにソケット検索が行われるかを順に見ていきましょう。
2.2 受信処理におけるソケットの検索処理
本章の冒頭で述べたようにUDPソケットの検索は__udp4_lib_lookup_skbで行っています。
(以下に本章冒頭の関数呼び出し関係を再掲しました。)
udp_rcv
└── __udp4_lib_rcv
├── inet_steal_sock // ①UDP Early Demultiplexer
├── __udp4_lib_lookup_skb // ②ソケットの特定/取得(本章の解説ターゲット)
└── udp_unicast_rcv_skb
└── udp_queue_rcv_skb // 次章で解説: 受信パケットのソケットへの配送
前節の解説からもわかるとおり、hash2におけるUDPソケットの特定処理は次の2ステップに分けられます。
hash2のスロットの特定- スロット内でのUDPソケットの特定
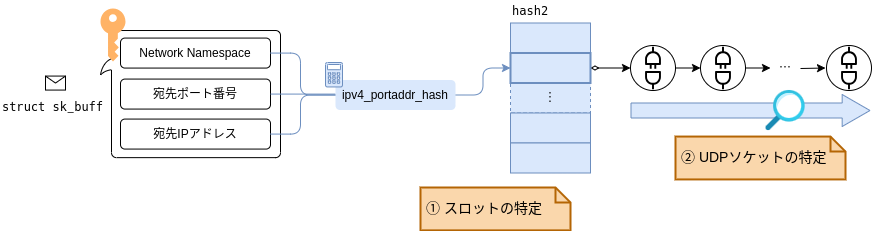

__udp4_lib_lookup_skbでも以下のように2ステップでソケットの特定を行っています。
__udp4_lib_lookup_skb └── __udp4_lib_lookup // スロットの特定(2.2.1項で解説) └── udp4_lib_lookup2 // スロット内におけるUDPソケットの特定(2.2.2項で解説)
次項からは、これらの処理について解説していきます。
2.2.1 検索キーの特定とスロットの特定
前節で解説したhash2の構造からもわかるとおり、スロットを特定するためには以下の3つの情報が検索キーとして必要になります。
- Network Namespace
- 宛先IPアドレス
- 宛先ポート番号
これらの情報は__udp4_lib_lookupに引数として渡され、ipv4_portaddr_hash関数に通すことでハッシュ値、すなわちスロットを計算/取得します(図2-4参照)。
それでは、これらの検索キーはどのように取得しているのでしょうか。
(スロットの特定処理という意味ではこれで解説は終わりです。ここから先はsk_buff構造体まわりのデータ構造の話になります。興味のない方は次項までスキップして問題ありません。)
当然ですが、これらの検索キーの情報は受信パケット(sk_buff構造体)から特定できるようになっています。
Network Namespaceの特定
Network NamespaceはNICに紐付いています。
つまり、ここで言及しているNetwork Namespaceとは当該パケットを受信したNICが属しているNetwork Namespaceのことになります。
受信パケット(sk_buff構造体)には受信したNICを指し示す.dev変数があり、そこからNetwork Namespaceを特定できます。


実際のハッシュ計算に用いられる数値としては、Network Namespace毎に用意される乱数、.hash_mixが用いられます。
宛先IPアドレス/ポート番号の特定
宛先IPアドレスと宛先ポート番号はそれぞれ、IPヘッダーとUDPヘッダー内に存在します。
宛先IPアドレスについては、前回の記事で解説したとおり、iphdr構造体を介してIPヘッダにアクセスすることで取得可能となります。
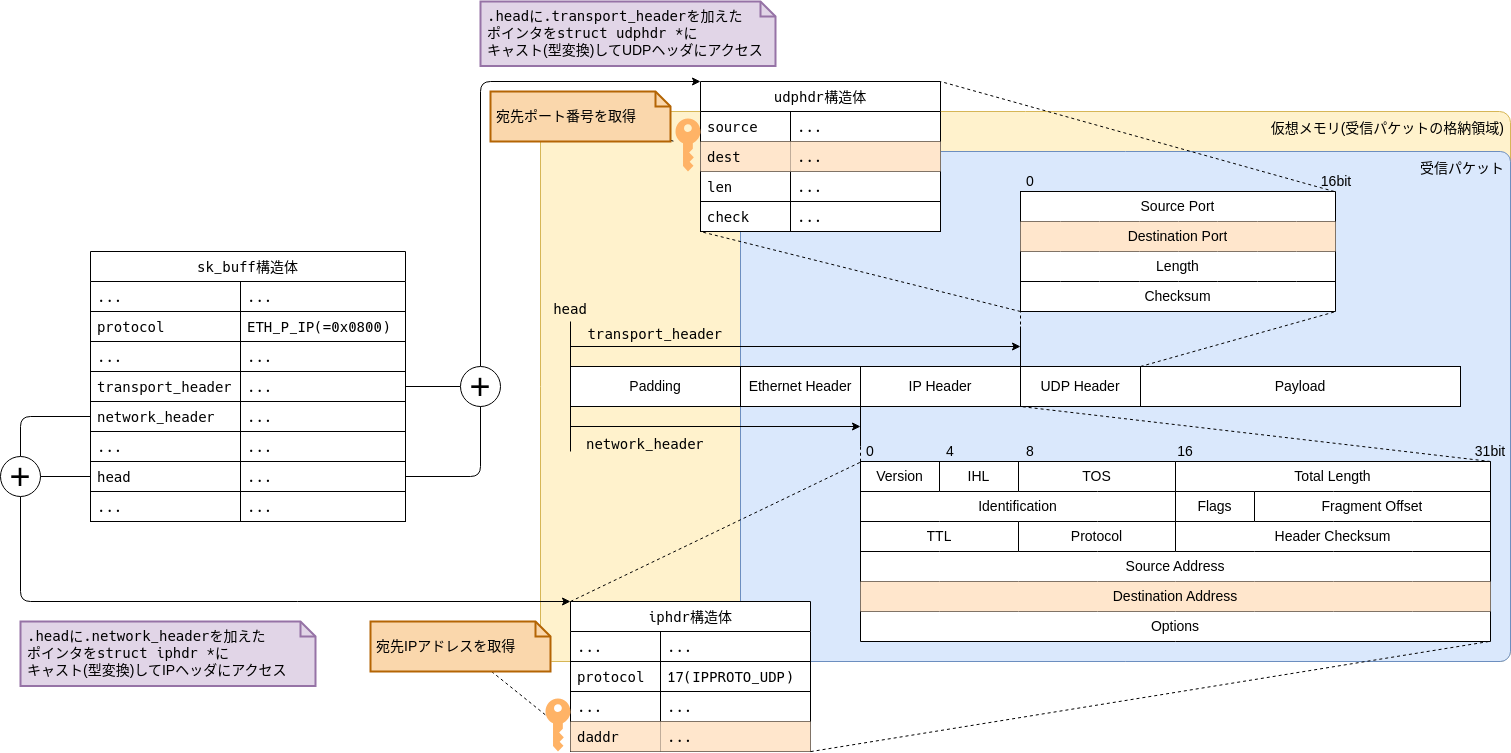

宛先ポート番号についても、IPアドレスと同じアプローチをとっています。
宛先ポート番号についてもsk_buff構造体のメンバ変数に記録されているわけではないため、udphdr構造体を介してUDPヘッダにアクセスする必要があります。
sk_buff構造体ではUDPヘッダまでのオフセットが.transport_headerというメンバ変数に記録されており、これを利用します。
図2-6に示したとおり、パケットの格納領域の先頭アドレスを示す.headと.transport_headerを足し合わせることで、UDPヘッダへのアドレス(ポインタ)を取得できます。
そして、このUDPヘッダへのアドレスをudphdr構造体にキャスト(型変換)してアクセスすることで宛先ポート番号(.dest)を含むUDPヘッダの各種情報にアクセスできるようになります。
このようにして、hash2のスロットの特定に必要な検索キーをsk_buff構造体から取得できることを確認できました。
次項では、これらの検索キーによって特定したスロットの中から目的のソケットをどのように特定しているかについて見ていきます。
2.2.2 ソケットの特定: ソケットのスコアリング
スロットが特定できてしまえば、あとはソケットのリストから、パケットの宛先情報(アドレスとポート番号)と一致するソケットを見つけ出すだけです。 (下図の②の処理)
このときLinuxカーネルでは単純に、リストの先頭から「パケットの宛先情報(アドレスとポート番号)と一致するソケット」を探すのではなく、 ソケットに対して加点方式で採点し、もっとも得点(スコア)の高いソケットを採用するという処理を行っています。 (そもそもパケットの宛先情報と不一致なソケットは採点対象外(-1点)となります。)
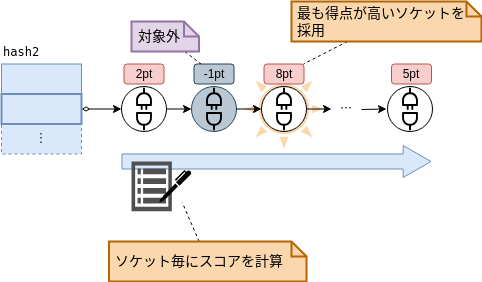

これはつまり、「パケットの宛先情報(アドレスとポート番号)と一致するソケット」が複数存在する状況を想定しているということになります。 これは一体、どういう状況なのでしょうか。
ソケットのスコアリングの背景
ソケットにはSO_REUSEPORTというソケットオプションが存在します。
このオプションを有効にすることで同一ポートに複数のソケットをbind(2)することができるようになります。
SO_REUSEPORTを使うことで、複数のプロセスを同一ポートで待ち受けさせることができるため、負荷分散等に利用されています。
(実際にNginx等のWebサーバーでは負荷分散を目的にSO_REUSEPORTを活用しているようです。)
つまり、SO_REUSEPORTを利用して、複数のソケットを同一ポートにbind(2)した場合に、
「「パケットの宛先情報(アドレスとポート番号)と一致するソケット」が複数存在する状況」が発生するというわけです。
それでは具体的に、どのような条件を満たすとスコアは加算されるのでしょうか?
スコアの加点
実際のスコア計算はcompute_scoreで行っています。
以下で、加点される条件/点数について、具体例をいくつか紹介したいと思います。
- ソケットのプロトコルファミリーが
PF_INETであれば2点。それ以外は1点。 - ソケットに通信相手のIPアドレスが設定してあれば4点。(要するに
connect(2)でIPアドレスを指定していれば加点)
*3 - ソケットに通信相手のポート番号が設定してあれば4点。(要するに
connect(2)でポート番号を指定していれば加点)
*4
他にも受信デバイス(NIC)や受信処理しているCPUコアに関する条件など、いくつか加点条件が存在します。 また、同一得点のソケットが複数見つかった場合には、先に見つかったソケットを採用します。
2.2.3 ソケットの再検索
前項では、スコアリングによってソケットを特定(決定)する処理について解説しました。
このとき、ソケットが特定できなかった場合、どうなるのでしょうか?
Linuxカーネルでは、初回のudp4_lib_lookup2関数呼び出しでソケットが特定できなかった場合、
検索キーの「宛先アドレス」を0.0.0.0(INADDR_ANY)に変更して再度、ソケットの検索処理を行います。
__udp4_lib_lookup_skb
└── __udp4_lib_lookup // スロットの特定
├── udp4_lib_lookup2 // UDPソケットの特定 with パケットの宛先情報
└── udp4_lib_lookup2 // UDPソケットの特定 with INADDR_ANY
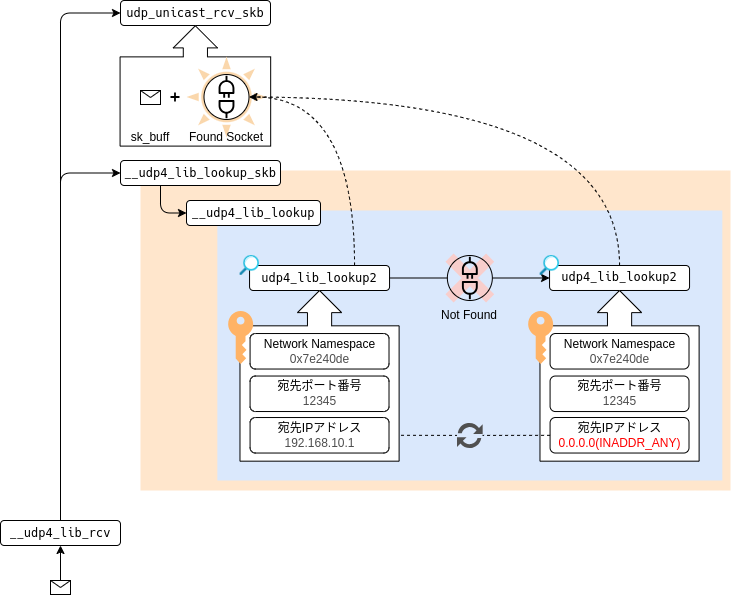

これはつまり、INADDR_ANYでバインドされたソケットは、そうでないソケットに比べて検索コストが僅かに高いと言えます。
3. 受信パケットのソケットへの配送とアプリの起床
前章では、ソケットの特定処理について解説しました。 本章では、この特定したソケットにパケットのデータを配送する処理を見ていきましょう。
一度ここまでの流れをおさらいしましょう。
udp_rcv
└── __udp4_lib_rcv
├── inet_steal_sock // UDP Early Demultiplexer(2章冒頭で紹介)
├── __udp4_lib_lookup_skb // 2章で解説: ソケットの特定/取得
│ └── __udp4_lib_lookup // 2.2.1で解説: スロットの特定
│ ├── udp4_lib_lookup2 // 2.2.2で解説: UDPソケットの特定 with パケットの宛先情報
│ └── udp4_lib_lookup2 // 2.2.3で解説: UDPソケットの特定 with INADDR_ANY
└── udp_unicast_rcv_skb
└── udp_queue_rcv_skb // 3章(本章)のメインテーマ: 受信パケットのソケットへの配送
前章では、ソケットの特定処理として__udp4_lib_lookup_skbを解説しました。
このとき、呼び元の__udp4_lib_rcvでは__udp4_lib_lookup_skbの戻り値として、ソケットを取得します。
そして、udp_queue_rcv_skbで、この特定したソケット(sock構造体)にパケット(sk_buff構造体)を配送します。
それでは、udp_queue_rcv_skb以降の流れを簡単に見てみましょう。
udp_queue_rcv_skb
└── udp_queue_rcv_one_skb
└── __udp_queue_rcv_skb
└── __udp_enqueue_schedule_skb // パケットのデータをソケットにつなぐ
└── sk->sk_data_ready: sock_def_readable // アプリの起床キック
コメントにあるように、ソケットへのデータ配送という観点でコアとなる処理は__udp_enqueue_schedule_skbになります。
次節ではこの処理を深堀していきたいと思います。
3.1 受信パケットのソケットへの配送
__udp_enqueue_schedule_skbの詳細を解説する前に、まずはソケットを介した受信パケットの受け渡し処理についてザックリ把握しておきたいと思います。
(内容的には次回の解説範囲と一部重なります。)
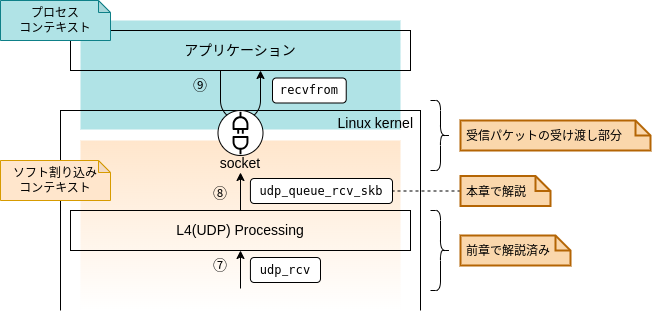

Linuxカーネルは受信したパケットをソケットへ配送します。
一方、アプリケーションはrecvfrom(2)等のシステムコールによりソケットから受信パケットを取り出します。
このとき、受信パケットはどのようなデータ構造によってソケット内で保持されているのでしょうか。
図3-2に示すように、ソケットでは受信パケットをつなぐための受信キュー(.sk_receive_queue)とアプリケーション側(recvfrom(2))からの読み取りを行うための読み取りキュー(.reader_queue)に分かれています。
(どちらのキューも実装上はただのリスト構造です。)
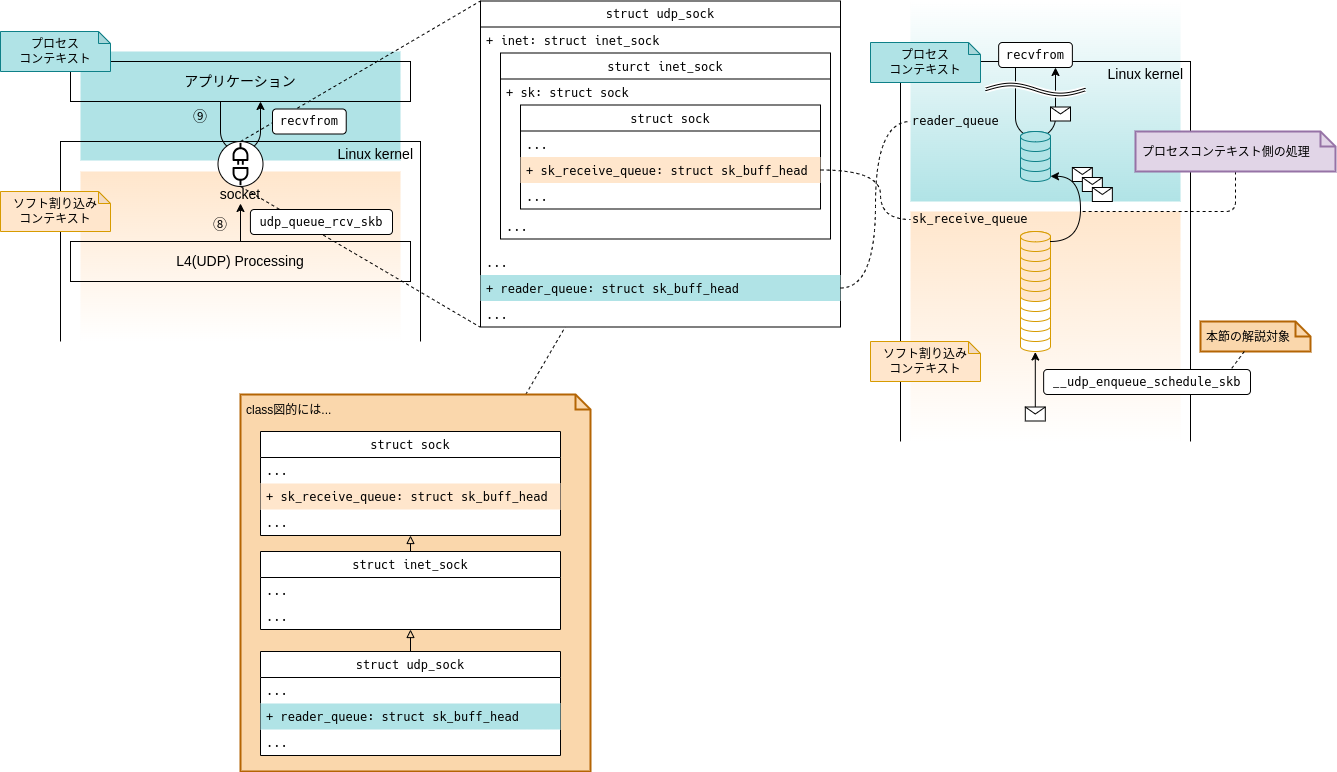

Linuxカーネルは受信したパケットを受信キュー(.sk_receive_queue)にエンキューします。
そして、recvfrom(2)を起点とする読み取り処理では、読み取りキュー(.reader_queue)から受信パケットを取り出します。
なお、図3-2に示したとおり、受信パケットを受信キュー(.sk_receive_queue)から読み取りキュー(.reader_queue)へ移す必要がありますが、これはプロセスコンテキスト側の処理、つまり読み取り処理側(recvfrom(2)の延長)で行います。
ところでなぜ、受信キュー(.sk_receive_queue)と読み取りキュー(.reader_queue)に分かれているのでしょうか?
これは、「受信処理」と「読み取り処理」間の競合状態を避けるためだと考えられます。
「受信処理」と「読み取り処理」は別々のコンテキストで実行されるため、これらは並列動作する可能性が十分にあります。
このとき、仮に「受信処理」と「読み取り処理」で1つのキューを共有していた場合、片方の処理が実行されている間は、もう一方はロック取得待ちになってしまい、実質的に処理を継続することができなくなってしまいます。
そのため、「受信処理」と「読み取り処理」用にそれぞれキューを分離することで、このような競合状態を回避しています。*5
*6
このようにソケットを介した受信パケットの受け渡しでは、受信処理と読み取り処理が並列動作できるように工夫されていることがわかりました。
それでは、次項から__udp_enqueue_schedule_skbの処理について見ていきたいと思います。
3.1.1 受信パケットの受信キューへのエンキュー
__udp_enqueue_schedule_skbでは図3-2に記載してあるとおり、受信したパケットを受信キュー(.sk_receive_queue)にエンキューする処理を行っています。
受信キューといっても実装上はただのリスト構造なので、受信パケットをリストに追加するだけです。非常にシンプルな処理内容ですね。
ただし、受信パケットをエンキューするにあたり、バッファに関する条件チェックを行います。
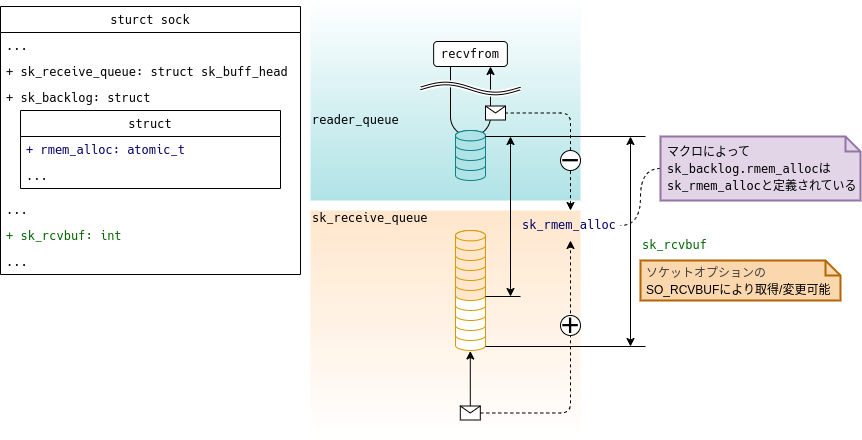
ソケットでは保持(キューイング)できる受信データ量に上限を設けており、この制限に関してはsock構造体内の以下の変数で管理/チェックを行います。
.sk_rcvbuf
ソケットが受信パケットを保持できる最大データ量。(=受信バッファサイズ)
/proc/sys/net/core/rmem_defaultで参照/変更が可能。
また、ソケットオプションのSO_RCVBUFでも参照/変更が可能。(詳細はsocket(7)を参照。).sk_rmem_alloc
現在、ソケットが保持(キューイング)している受信パケットの総データ量。
なお、sk_rmem_allocはマクロ名で、正しくは.sk_backlog.rmem_alloc。
ただし、ソースコード内ではsk_rmem_allocで参照していることがほとんどであるため、本記事でもsk_rmem_allocと記載。
すなわち、.sk_rmem_alloc < .sk_rcvbufのときのみ受信パケットを受信キュー(.sk_receive_queue)にエンキューします。
このとき、当然ですが.sk_rmem_allocの値はエンキューした受信パケット分だけ増加します。
一方、.sk_rmem_allocの値が減少するのは、パケットを読み取りキュー(.reader_queue)から取り出したタイミングになります。
つまり、.sk_rcvbufと.sk_rmem_allocは、図3-3に示すとおり、「受信キュー」だけでなく、「読み取りキュー」の状態も含めた値になります。

このことからアプリケーションのパケット読み取り速度が、パケットの受信速度よりも相対的に遅い場合、図3-4に示すように、.sk_rmem_alloc > .sk_rcvbufとなりパケットドロップが発生する可能性があります。
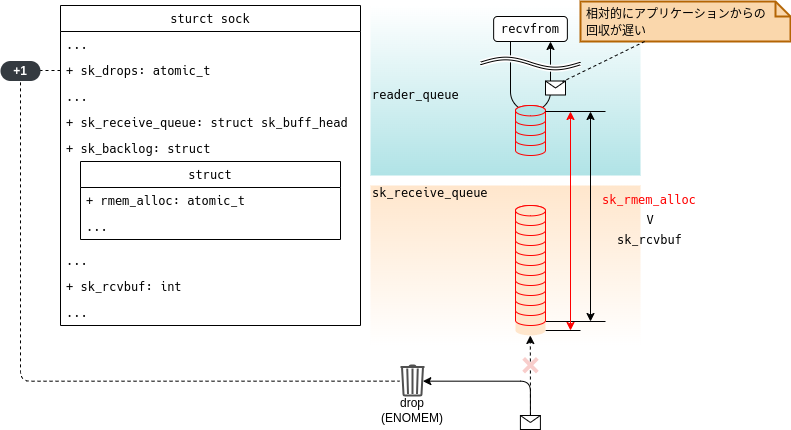

パケットドロップが発生した場合は、sock構造体の.sk_dropsが増加します。
なお、この.sk_dropsの値はss -mで参照することができます。
ここまで、受信パケットをソケットに配送する流れを見てきました。
__udp_enqueue_schedule_skbでは、受信キュー(.sk_receive_queue)に受信パケットをエンキューした後、最後にアプリケーションを起床させる処理を行います。
次節では、このアプリケーションの起床処理について見ていきます。
3.2 アプリケーションの起床処理
3.2.1 アプリケーションの状態(プロセスコンテキストにおける話)
アプリケーションの起床処理について解説する前に、ここで想定しているアプリケーションの状態について簡単に説明したいと思います。
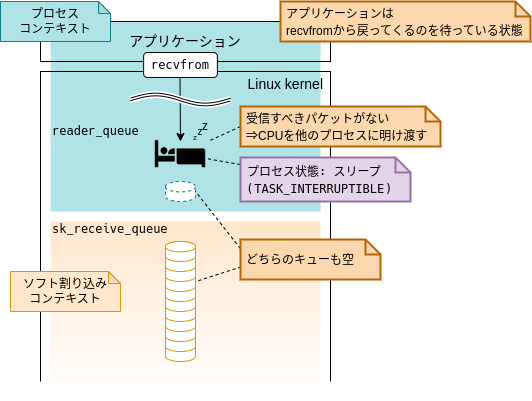
「起床」と記載している時点で、なんとなく想像できそうですが、ここではアプリケーションがパケットの到着を待っている状態(スリープ状態)を想定します。(つまりCPUを別のプロセスに明け渡している状態。)
前節で解説したとおり、アプリケーションはrecvfrom(2)等のシステムコールを経由して「読み取りキュー」(.reader_queue)から受信パケットを取り出します。
このとき、受信すべきパケットが存在しない、すなわち「読み取りキュー」(.reader_queue)と「受信キュー」(.sk_receive_queue)が共に空だった場合、プロセスはスリープ(CPUを別のプロセスに明け渡す)状態になります。
(条件によっては必ずしもスリープ状態になるとは限りませんが、ここではスリープ状態になることを前提として話を進めます。このあたりの話は次回解説予定です。)

次項では、このようにアプリケーションがスリープしている状態を前提に、ソフト割り込みコンテキストにおける処理を解説します。
3.2.2 アプリケーションの起床(ソフト割り込みコンテキストにおける話)
先述したとおり、__udp_enqueue_schedule_skbでは、受信キュー(.sk_receive_queue)に受信パケットをエンキューした後、アプリケーションを起床させます。
起床処理自体はスケジューラの処理が大きく関わってくるため、詳細は割愛し、起床すべきアプリケーションの特定と関数コールについてのみ簡単に触れたいと思います。
アプリケーションプロセスは自身が受信パケットの到着待ちでスリープ状態に遷移する際、自身のプロセス情報(task_struct構造体へのポインタ)をsock構造体に登録します。
これにより、ソフト割り込みコンテキスト側の処理(__udp_enqueue_schedule_skb)から、アプリケーションプロセスを特定し起床処理を実行することができます。


最後にこの起床処理部分の関数呼び出し関係を掲載しておきます。(呼び出し関係が深いので一部省略しています。)
__udp_enqueue_schedule_skb // 3.1節で解説: パケットを受信キューにエンキュー └── sk->sk_data_ready: sock_def_readable // 起床処理のエントリー。ソケット生成時に登録される関数ポインタ。 └── wake_up_interruptible_sync_poll ︙ └── __wake_up_common └── curr->func: receiver_wake_function // アプリケーション側が登録する起床用コールバック関数 ︙ └── try_to_wake_up
4. ソフト割り込みコンテキストにおける受信処理の振り返り
今回でソフト割り込みコンテキストにおける受信処理の解説が完結しました。 せっかくなので、ここでソフト割り込みコンテキストの処理全体について簡単に振り返りたいと思います。 本連載では毎回、概観図として以下を掲載してきました。
そして、本連載の初回では、概観図とともに以下のシーケンス図も掲載していました。


ソフト割り込みコンテキストに関する解説は連載第2回目の「Ethernetドライバ ポーリング処理編」から始まり、 主に図4-2中のloopで囲まれた部分を解説してきました。
これまで、net_rx_actionから始まり、各レイヤーにおける主要な関数に触れながら解説を行ってきました。
ここでnet_rx_actionからソケットに配送するまでの流れを一望したいと思います。


このようにしてみると非常に長いですね。 また、図4-3中に記載があるとおり、IPレイヤーの途中までは複数パケットをまとめて(=リスト/サブリストとして)処理していますが、途中から単一パケットで処理しています。 つまり、単一パケットの処理に切り替わっている部分は、リストのパケット数分だけループしているということになります。 さらに、図4-3のポーリングハンドラ以降は図4-2のloopで囲まれている部分の処理に該当します。 すなわち、この図4-3の大部分がループしているということになるわけです。 このようにしてみると、Linuxカーネルのパケット受信処理はそれなりにコストがかかっていることが、なんとなく実感できるのではないでしょうか。
5. 次回予告
次回が「パケット受信処理」のラストになります。 次回はアプリケーションがソケットから受信パケットを取り出す処理を追っていきます。
*1:Linuxカーネルv6.13から新たなハッシュテーブルhash4が追加されました。すなわち、v6.13ではUDP Tableに3つのハッシュテーブルを保持していることになります。
*2:もともとhash2は存在せず、あとから追加されました。hashだけでは、多数のIPアドレスが使われた場合にスロットに繋がるソケットのリストが長くなり、検索に時間がかかることが問題視されました。このような背景から宛先IPアドレスをキーに加えたhash2が導入されました。
*3:このときに設定済みのIPアドレスとパケットの送信元アドレスが異なれば、スコアには-1が登録され当該ソケットは検索対象外となります。
*4:このときに設定済みのポート番号とパケットの送信元ポート番号が異なれば、スコアには-1が登録され当該ソケットは検索対象外となります。
*5:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=2276f58ac5890e58d2b6a48b95493faff7347e3a
*6:「受信キュー」から「読み取りキュー」に受信パケットを移す際に競合状態になる可能性はあります。そのため、「受信処理」と「読み取り処理」用にキューを分離したとしても完全に競合状態を回避できるわけではありません。ただし、 「受信キュー」から「読み取りキュー」に受信パケットを移すタイミングは、「読み取りキュー」が空になったタイミングであり、また、このとき「受信キュー」に存在する全パケットをまとめて移動させるため、競合が発生する機会は限定的と考えられます。